
AI in Data Warehousing
The ability to efficiently store, manage, and analyze data has become a critical aspect for any organization. The field of Data Warehousing is an integral part of the process by providing structured, centralized storage for large volumes of data and is an important element of business intelligence.
However, the increasing volume and complexity of data is becoming increasingly challenging to manage. That said, AI is already shaping many processes in a wide variety of areas, including data warehousing.
This article explores the basic principles and applications of artificial intelligence and how AI can be integrated into an Enterprise Data Warehouse, by using it to enhance the design and operation of data warehouses, as well as enabling the development of more challenging data science applications like machine learning or predictive analytics.
AI in Data Warehousing: Fundamental Principles and Applications
This webinar delves into the essential principles of Artificial Intelligence (AI) and its transformative role in data warehousing. We explore how AI and Machine Learning (ML) not only enhance the construction and operation of data warehouses but also leverage the vast amounts of data stored within them for developing powerful applications, e.g. for predictive analytics.
You will gain an understanding of the foundational AI technologies driving these advancements and how they intersect with data science and machine learning to optimize data storage, improve decision-making, and unlock new business insights. This webinar provides valuable perspectives on integrating these technologies into your data warehousing practices.
Foundational Principles of AI
Let’s start by categorizing the term artificial intelligence, as well as other terms such as machine learning, deep learning, or generative AI, in order to clarify the context and what exactly is hidden behind these terms.
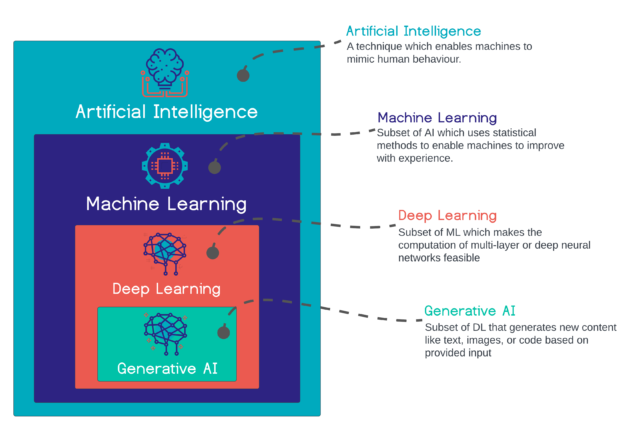
Artificial Intelligence is now more of a generic term and represents a broad field. In general, the term AI encompasses techniques that allow computers to emulate human behavior, enabling them to learn, understand language, make decisions, recognize patterns, and solve complex problems in a way that is similar to human intelligence.
Machine Learning (ML) as a Subset of AI
Machine Learning is a subset of the field of artificial intelligence and, even if less present as a term, one of the most important. Machine Learning uses advanced techniques and algorithms to recognize patterns in large amounts of data, allowing machines to learn and adapt autonomously to make inferences or predictions based on the data. Unlike traditional programming where tasks are executed based on clear and defined instructions, machine learning relies on statistical analysis based on input data to output data values that fall within an expected range. Essentially, machine learning enables computers to learn and interpret data without being explicitly programmed for each individual case.
Deep Learning (DL) – A Deeper Dive into ML
Deep Learning is a more specialized sub-area of machine learning & AI and uses deep neural networks to perform in-depth data processing tasks to recognize complex patterns.
Deep learning uses many layers to extract high-level features from raw data as input, in a sense simulating the way a human brain works.
In this respect, deep learning is particularly strong in processing very large amounts of data, using it to learn complex patterns in order to solve a wide variety of tasks. Well-known examples of this are tasks such as image or voice recognition, which every smartphone is capable of.
Generative AI – The Creative Aspect of Deep Learning
Generative AI is a term that has recently become more widely known, especially due to ChatGPT. Generative AI is a sub-area of deep learning and includes deep learning models that generate new content, such as text, images, code, or even videos, based on data on which they have been trained on. They are able to generate novel outputs without explicit instructions that do not directly replicate the training data. This opens up completely new possibilities such as generating large texts, complex images, or even music.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsThe Role of AI in Building Data Warehouses
AI is changing everything, including data warehousing. As such, it can help to enhance the efficiency and effectiveness of your data warehouse from the ground up. From the design and structure to the ongoing data management processes, there are many opportunities where AI can help.
AI has the power to address a data warehouse’s biggest challenges: performance, governance, and usability. This is data intelligence and will revolutionize the way you query, manage, govern, and visualize your data.
Enhancing Design and Structure
The architecture of a data warehouse is critical as it needs to support efficient data querying and scalability while maintaining performance. By analyzing usage and query patterns, AI algorithms can suggest the most effective data models and indexing strategies. This not only speeds up the retrieval of information but also ensures more agile data handling when scaling or integrating new data sources.
Automating Data Integration, Cleaning, and Transformation
By letting AI take over low-level tasks, data engineers can focus on higher-level tasks such as designing data models, training machine learning algorithms, and creating data visualizations. For example, The Coca-Cola Company uses AI-powered ETL tools to automate data integration tasks across its global supply chain to optimize sourcing and procurement processes.
But AI can also support the actual developers in their work, enabling them to work faster and more efficiently. Developers can use AI to debug problems in their code faster by using AI-based code generation and analysis, such as Github Copilot, which completes, refactors, and debugs code in real time directly in the IDE.
The automation of performance tuning of data warehouse workloads can also be improved with predictive optimizations, which can save a considerable amount of costs.
AI can also scale and automate governance using automated tagging, documentation, and natural language search across all data and assets in an organization.
Right up to the possibility that business users could use natural language to interact with the data, ask questions, and build dashboards, the possibilities are endless and we are only at the very beginning of these developments.
Using a Data Warehouse for AI Applications
The nature of a data warehouse, a structured and centralized repository that aggregates data from multiple sources within an organization, makes it a perfect foundation for building and training AI applications. AI models require large amounts of data with as much variability as possible that are well structured and have a high data quality, which a data warehouse can perfectly provide for an organization to train its own AI model.
For example, a data warehouse in a retail context might store years of customer purchase history, demographics, and product information. Data that can be used to train AI models to predict future buying trends or recommend products effectively.
Enhancing AI Capabilities with Data Vault
Data Vault 2.0 in particular sets the exact right conditions for training your own AI models by leveraging the structured, reliable data framework that Data Vault 2.0 provides.
Here’s are some examples how this integration can benefit AI-driven analytics:
- Improved Data Quality: The organized and auditable structure of Data Vault 2.0 ensures higher data quality and consistency, which is important for training accurate AI models. Clean, well-structured data models reduce the time spent on data preparation and increase the reliability of AI predictions.
- Enhanced Historical Analysis: The comprehensive historical data captured by Data Vault 2.0 allows AI models to perform more accurate trend analysis and forecasting. This capability is especially valuable in sectors like finance and retail, where understanding long-term trends can significantly impact strategic decisions.
- Data Reliability and Lineage: Data Vault 2.0’s robust framework ensures data reliability through its unique architecture that captures data from various sources while maintaining its lineage. This means every piece of data in the system can be traced back to its origin, providing transparency and trust in the data used for AI models.
Conclusion
Integrating artificial intelligence (AI) into data warehousing significantly enhances the efficiency and effectiveness of data storage, management, and analysis. By applying AI techniques, organizations can automate data integration, cleaning, and transformation processes, leading to more accurate and timely insights. Furthermore, AI-driven optimization of data warehouse design and structure ensures improved performance and scalability. Embracing AI in data warehousing not only streamlines operations but also empowers businesses to leverage advanced analytics, such as machine learning and predictive analytics, thereby unlocking deeper insights and fostering informed decision-making.

Good and knowledgeable blog.
The article explains how artificial intelligence is enhancing modern data warehousing by automating and improving key tasks such as data integration, cleaning, transformation, and performance optimization. Instead of handling all processes manually, AI can suggest efficient data models, automate ETL work, and support governance and natural-language interactions with data. It also highlights that a data warehouse provides the structured, high-quality data needed to train and deploy advanced AI and predictive analytics models. Overall, AI makes data warehouses smarter, more scalable, and better at unlocking business insights.