What is Data Vault 2
Data Vault 2 is a business intelligence system that includes the components needed to realize your enterprise vision for data integration and information delivery. As a hybrid architecture, it combines the best aspects of third normal form and a star schema, resulting in a historical-tracking, detail-oriented, uniquely linked set of normalized tables.
Crucially, this robust foundation transforms your infrastructure into an AI-ready data platform. By ensuring that advanced analytics and machine learning models are fueled by highly reliable, fully auditable data, Data Vault 2 leverages original modeling concepts into a modern environment, enabling outstanding scalability, flexibility, and consistency. It is an open standard based on three major pillars: Architecture, Modeling, and Methodology.
General Definitions
Before diving into how Data Vault 2 works, it is helpful to understand a few foundational concepts that are essential to the framework. For a complete, guided introduction, our Udemy course “Data Vault: An Introduction by Michael Olschimke” is a great place to start.
Business Keys
These are unique identifiers of relevant business objects (such as a customer, product, or order). They establish a common language across your enterprise, allowing different systems to integrate seamlessly. A good business key has a low propensity to change and is universally recognized.
Rules
Data Vault strictly separates rules into two types. Hard Rules are technical adjustments that adapt data for the platform without altering its fundamental meaning. Soft Rules (or business rules) transform the data to serve end-user requirements and business logic.
1. Data Vault Architecture
The Data Vault 2 architecture is built upon a highly scalable three-layer structure. This approach separates the complexities of data integration and historical tracking from the delivery of actionable insights to end users.
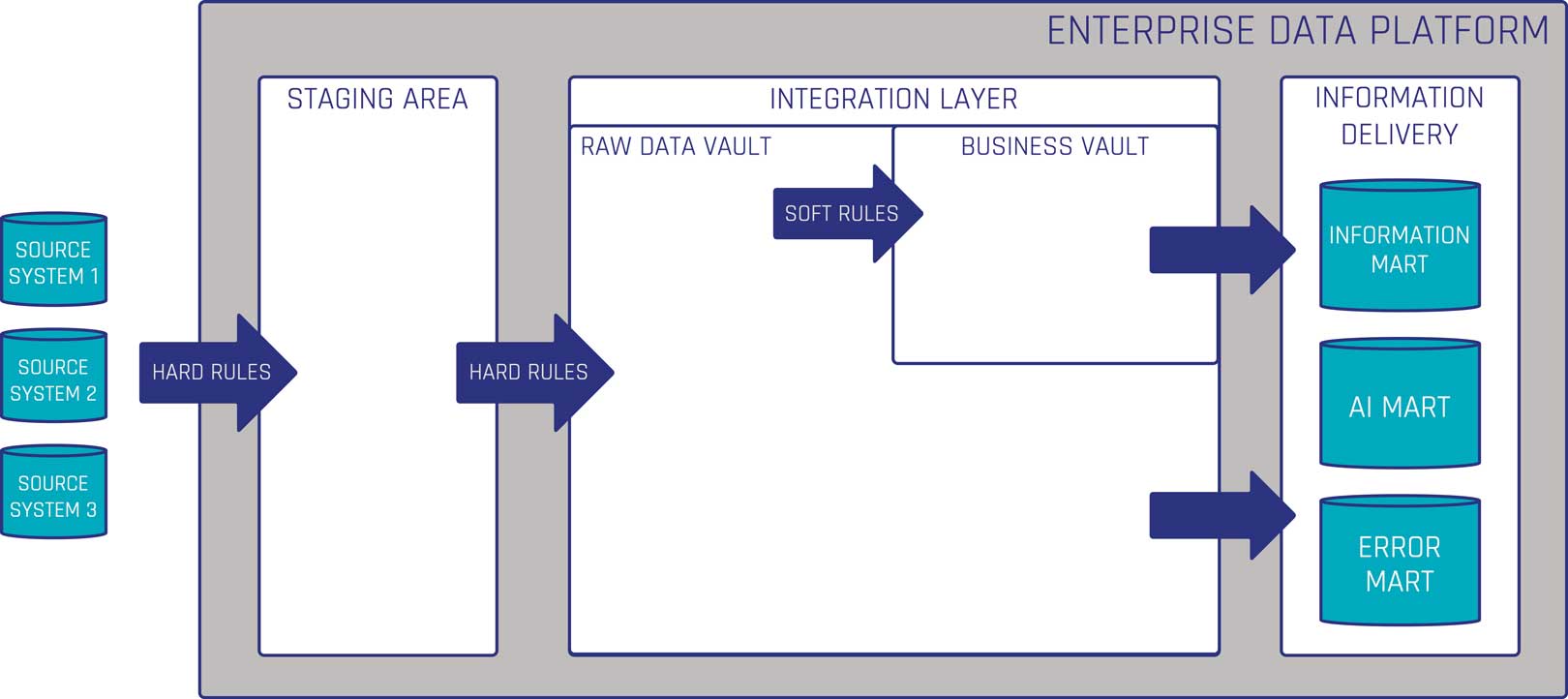
Staging Area
The initial layer where raw, unmodified data is collected from various source systems. Its primary purpose is to offload the burden from operational systems and prepare the data for the warehouse using only Hard Rules.
Integration Layer
This is the core of the platform, designed to create a single point of facts. It is divided into two parts:
- Raw Data Vault: Stores data in its original, unmodified format, ensuring full historical context and strict auditability.
- Business Vault: An intermediary layer where Soft Rules and calculations are applied to bridge the gap between raw data and end-user needs.
Information Delivery
The user-facing layer that transforms data into accessible formats like star schemas or flat tables. It delivers data via specialized marts tailored to specific needs, for instance:
- Information Mart: Focuses on business metrics and KPIs.
- Error Mart: Tracks data inconsistencies that violate hard rules.
- AI Mart: A feature store derived from multiple data sources, used directly by data scientists to train machine learning and AI models.
2. Data Vault Modeling
Data Vault modeling is designed to explicitly meet the needs of today’s enterprise data platforms, managing big data and high velocity with ease. The model is based on three core entities that represent a business from its fundamental components:
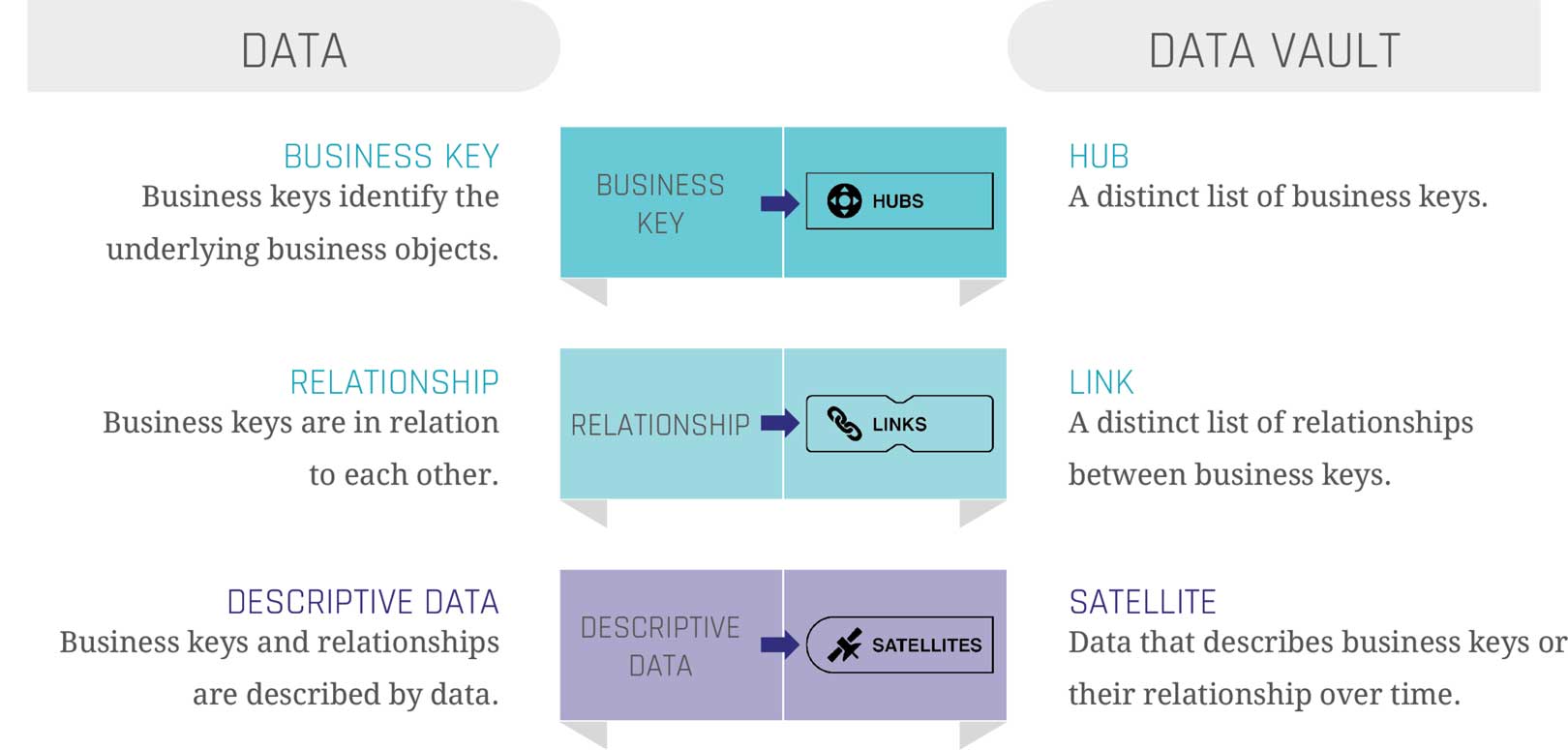
Hubs
Represent core business concepts through a distinct list of business keys (e.g., a “Customer” or “Flight” Hub).
Links
Serve as the connectors that illustrate how different Hubs (business concepts) interact and relate to one another (e.g., a patient visiting a doctor).
Satellites
Store the descriptive attributes and historical context associated with Hubs or Links. Every time an attribute changes, the Satellite logs it, creating a complete historical timeline.
To illustrate how these core entities work together, consider an aviation scenario:
The central business elements -such as airports, carriers, and flights- are modeled as distinct Hubs (HubAirport, HubCarrier, and HubFlight). To represent a complete flight and establish the relationship between these independent objects, a Link (LinkFlight) connects all three of these Hubs together. Finally, Satellites are attached to provide the necessary context and descriptive data. For instance, HubAirport has multiple Satellites (SatAirportLocation and SatAirportTZ) to separate and historically track different types of airport attributes.
Wondering how to model your own complex business scenarios? Bring your questions to Data Vault Friday, our live weekly Q&A webinar.
To ensure lightning-fast reporting and analytics, the Business Vault also utilizes Query Assistant Tables, such as Point-in-Time (PIT) and Bridge tables. These system-generated entities act as indexes to simplify complex data joins and drastically accelerate query performance for end-users.

3. Data Vault Methodology
Data Vault 2 incorporates core engineering standards like Capability Maturity Model Integration (CMMI), Total Quality Management (TQM), and Six Sigma to ensure consistent, repeatable, and high-quality deployments.
However, modern Data Vault 2 environments have evolved to embrace highly agile, value-driven ways of working:
Disciplined Agile
An evolutionary approach that balances quality, speed, and adaptability. It encourages self-organizing teams to work iteratively, addressing technical debt at its root cause and delivering functional solutions quickly.
Product Mindset
Instead of viewing a data platform as a finite “project” with an end date, Data Vault 2 methodology encourages a product-based approach. The data platform is treated as an ongoing, evolving product that delivers continuous, incremental value to the business, ensuring it scales seamlessly alongside your organization’s needs.
Want to master these standards for your own team? Explore our Data Vault 2.1 Training & Certification.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Read it for Free

Marc Winkelmann
Managing Consultant
Phone: +49 511 87989342
Mobile: +49 151 22413517