
Data Vault 2.0 mit dbt
Im ersten Teil dieser Blogserie haben wir Ihnen dbt vorgestellt. Nun schauen wir uns an, wie Sie Data Vault 2.0 mit dbt umsetzen können und welche Vorteile sich daraus ergeben. Falls Sie den ersten Teil noch nicht kennen, können Sie ihn hier nachlesen.
In diesem Artikel:
Dbt-Modelle
dbt bietet die Möglichkeit, Modelle zu erstellen und aus diesen Modellen dynamisch SQL zu generieren und auszuführen. So können Sie Ihre Datentransformationen in Modellen mit SQL und wiederverwendbaren Makros auf Basis von Jinja2 schreiben, um Ihre Datenpipelines sauber und effizient auszuführen. Der wichtigste Teil für den Anwendungsfall Data Vault ist jedoch die Möglichkeit, solche Makros zu definieren und einzusetzen.
Zunächst sollten wir jedoch klären, wie Modelle in dbt grundsätzlich funktionieren.
Dbt übernimmt die Kompilierung und Ausführung von Modellen, die mit SQL und der Makrosprache Jinja geschrieben sind. Jedes Modell besteht aus genau einer SQL SELECT-Anweisung. Der Jinja-Code wird während der Kompilierung in SQL übersetzt.
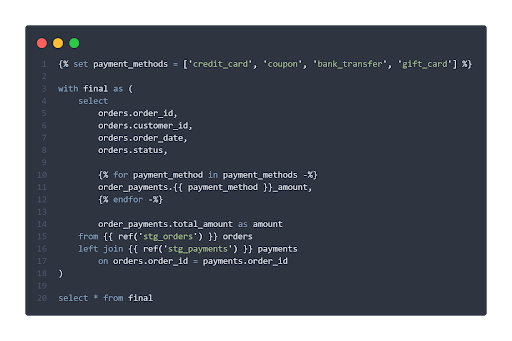
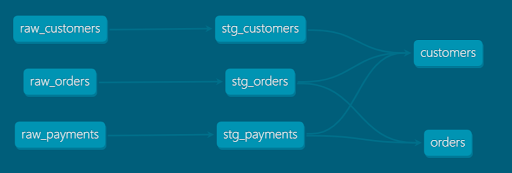
Die folgende Abbildung zeigt ein einfaches dbt-Modell. Ein großer Vorteil von Jinja ist die Möglichkeit, SQL programmatisch zu erzeugen – zum Beispiel mit Schleifen oder Bedingungen. Über die Funktion ref() erkennt dbt außerdem die Abhängigkeiten zwischen den Modellen und erstellt daraus einen Abhängigkeitsgraphen. So wird sichergestellt, dass Modelle in der korrekten Reihenfolge ausgeführt werden und die Datenherkunft nachvollziehbar bleibt. Ein solcher Lineage-Graph könnte etwa so aussehen:
Die Materialisierung von Modellen lässt sich auf unterschiedlichen Konfigurationsebenen steuern. So ist schnelles Prototyping mit Views möglich, bei Bedarf lässt sich später aber auch auf materialisierte Tabellen umstellen – etwa aus Performancegründen.
Data Vault 2.0 und Makros
Wie aber lässt sich Data Vault 2.0 mit dbt umsetzen? Der wichtigste Aspekt bei der Verwendung von Data Vault 2.0 ist die Möglichkeit, Makros zu definieren und zu nutzen. Makros können in Modellen aufgerufen werden und erzeugen dort zusätzlichen oder sogar den gesamten SQL-Code dynamisch.
Beispielsweise könnten Sie ein Makro schreiben, das ein Hub generiert. Dieses Makro erhält das Quell- bzw. Staging-Modell als Eingabeparameter sowie die Angabe der Spalten für den Business Key, das Ladedatum und die Datensatzquelle. Der entsprechende SQL-Code für das Hub wird dann daraus dynamisch erzeugt. Der große Vorteil: Eine Änderung am Makro wirkt sich sofort auf alle betroffenen Hubs aus, die Wartbarkeit erheblich verbessert.
Zusätzlich profitiert man von der aktiven Open-Source-Community rund um dbt. Es gibt zahlreiche Open-Source-Pakete mit denen dbt erweitert werden kann.
Einige davon eignen sich auch hervorragend für den Einsatz von Data Vault 2.0 mit dbt.
Zum Beispiel bietet unser eigenes Open-Source-Paket DataVault4dbt, das hier bei Scalefree entwickelt und aktiv gepflegt wird, einen umfassenden Satz an dbt-Makros zur Übersetzung eines „auf dem Papier“ entworfenen Data-Vault-Modells in tatsächliche Tabellen und Views – darunter Hubs, Links, Satelliten und mehr. Das Paket wird bereits in realen Projekten eingesetzt und unterstützt dabei, Best Practices für eine moderne, revisionssichere Data-Vault-2.0-Implementierung durchzusetzen.
Um alle Funktionen und Makro-Parameter im Detail kennenzulernen, werfen Sie einen Blick in die Dokumentation.
Das Einzige, was Sie in Ihrem Modell benötigen, beispielsweise für einen Hub, ist ein einziger Makroaufruf:
{%- hub(src_pk, src_nk, src_ldts, src_ource, source_model) -%}
Mit den Parametern des Makroaufrufs definieren Sie die Quelltabelle, in der sich die benötigten Spalten befinden (source_model), sowie die Spaltennamen für den Hash-Key(src_pk), den/die Business-Key(s) (src_nk), das Ladedatum (src_ldts) und die Datensatzquelle (src_source). Wird das Modell mitsamt dem enthaltenen Makro ausgeführt, wird der SQL-Code kompiliert und auf dem Datenbanksystem ausgeführt.
Die dafür nötigen Metadaten können beispielsweise direkt im Modell mithilfe von Jinja-Variablen definiert werden:
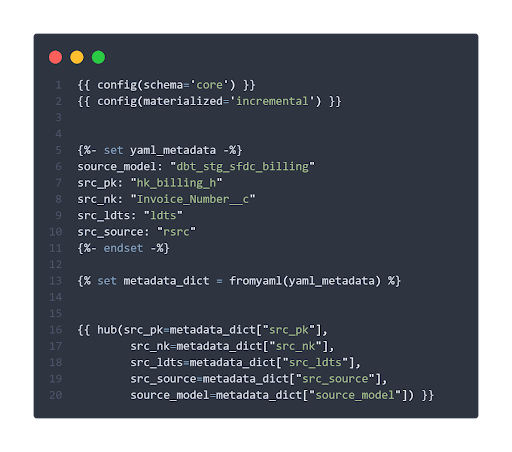
Dabei zeigt sich auch, dass dbt unterschiedliche Optionen zur Materialisierung bietet. So kann etwa mit der inkrementellen Materialisierung eine Entität schrittweise als Tabelle geladen werden.
Beim Ausführen des Modells erzeugt dbt den vollständigen SQL-Code aus dem Makro und entscheidet automatisch, wie die Daten geladen werden: Existiert die Hub-Tabelle noch nicht, wird sie erstellt und vollständig geladen. Ist sie bereits vorhanden, erfolgt ein inkrementelles Laden.
Wer bereits versucht hat, ein Data Vault-Modell mit reinem SQL umzusetzen, wird schnell erkennen, wie viel einfacher dieser Ansatz im Vergleich dazu ist. Das Team kann sich vollständig auf das Modellieren konzentrieren und sobald die Metadaten definiert sind, übernimmt dbt zusammen mit den Makros die gesamte technische Logik.
Frei verfügbare Pakete ermöglichen es, grundlegende Prinzipien von Data Vault 2.0 in dbt zu integrieren, und erleichtern so den Einstieg in die Implementierung. Aufgrund der offenen Architektur von dbt lassen sich alle Makros individuell an projektspezifische Anforderungen oder interne Standards anpassen.
Wichtig zu beachten: Viele der derzeit verfügbaren dbt-Pakete zur Umsetzung von Data Vault 2.0 weichen in einzelnen Details von den offiziellen Standards ab. Unser eigenes Open-Source-Paket DataVault4dbt, das hier bei Scalefree entwickelt und aktiv gepflegt wird, schließt diese Lücke: Es unterstützt alle zentralen Data Vault 2.0 Entitäten sowie aktuelle Best Practices. Das Paket kommt bereits in realen Projekten zum Einsatz und trägt dazu bei, eine moderne und revisionssichere Implementierung sicherzustellen.
Fazit
Die Kombination von Data Vault 2.0 mit dbt vereinfacht die Umsetzung moderner Data-Warehouse-Architekturen erheblich – dank der Möglichkeit, Modelle und Makros zu definieren und daraus dynamisch effizientes SQL zu generieren. So kann sich das Team ganz auf das Design konzentrieren, während dbt die technische Umsetzung übernimmt.
Unser Open-Source-Paket DataVault4dbt bringt diese Vorteile direkt in reale Projekte und bietet eine zuverlässige, standardkonforme Grundlage für den Aufbau von Hubs, Links, Satelliten und mehr.
-von Ole Bause (Scalefree)