Data Vault 2.0 with dbt
This article focuses on the benefits of using Data Vault 2.0 with dbt, and the importance of choosing the correct implementation tools. Data is an important asset in the decision-making process. As we have previously discussed in another post, Data Vault 2.0 is the right choice when the goal of an enterprise data warehouse is to have fully historized and integrated data. Additionally, it is also better suited to instances in which data from many source systems needs to be combined. You can find the previous blog post here.
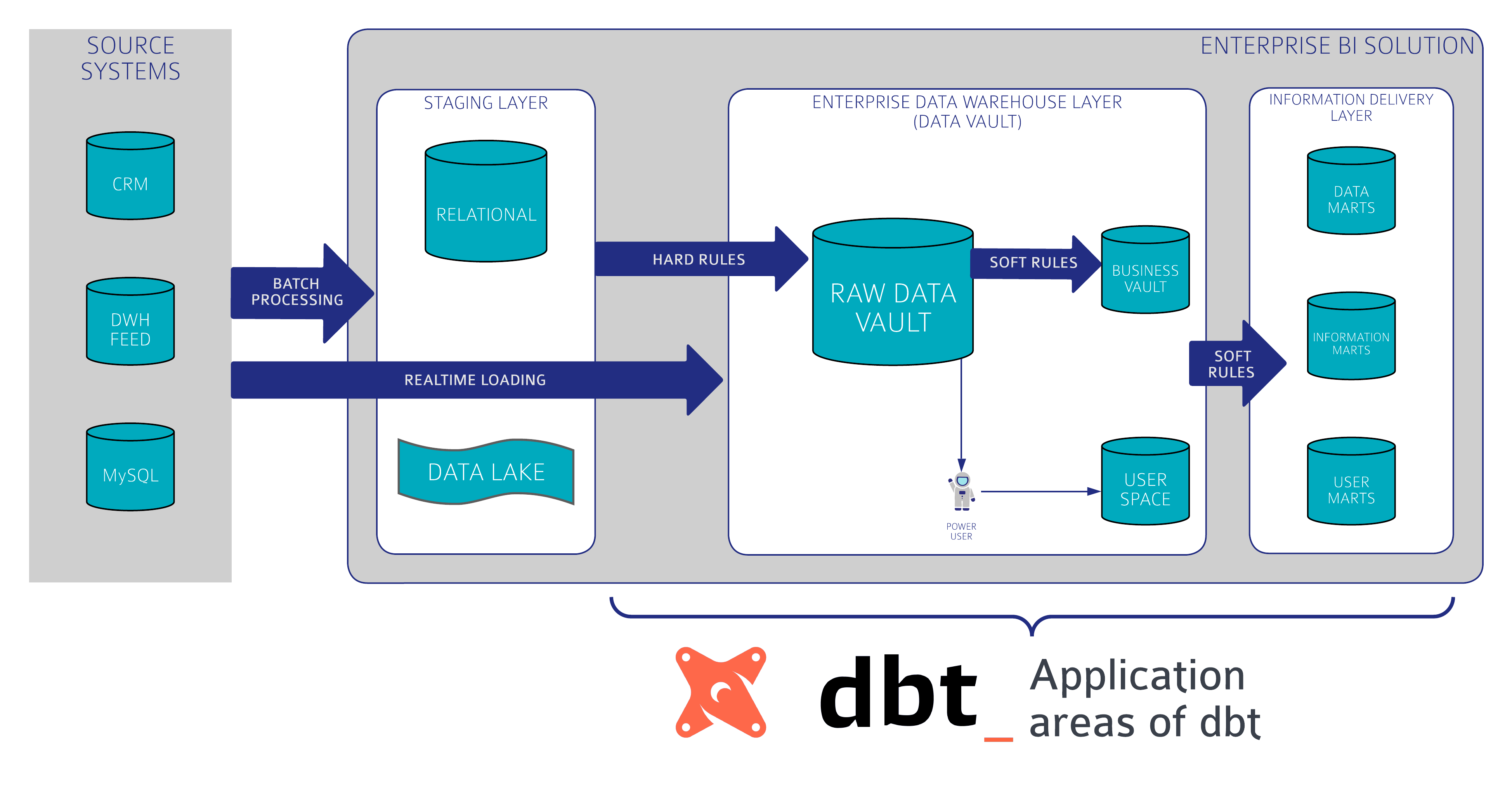
While Data Vault 2.0 focuses on the “what”, there are many options for the “how” of technically translating a Data Vault model into physical tables and views in the enterprise data warehouse, as well as for orchestrating and loading/processing the procedures. And this is where Data Vault 2.0 with dbt creates an effective solution.
About dbt
This data build tool transforms your data directly into your data warehouse. For reference, dbt is the “T” in ELT. Therefore, dbt assumes that data is already loaded into a database from which the current database can query. In contrast, ETL extracts data then transforms it and before loading it into the target. With ELT, the data is not transformed as it moves into the data warehouse. (with transform we mean transformation by soft business rules which would change the meaning of the data. Of course, we have to make sure that the data fits into the target table (data type adjustments, etc.). Here we are talking about “hard rules”.)
Dbt is particularly compatible and useful in cloud DWH solutions such as Snowflake, Azure Synapse Analytics, BigQuery, and Redshift and performs transformations and modeling directly on the database in order to take advantage of the performance of these highly scalable platforms.
How dbt works
Models and SQL statements can be easily created, tested, and managed in dbt itself. A powerful combination of the scripting language, Jinja2, and the all-time classic SQL allows users to build models. The simple interface enables data analysts without engineering know-how to initiate appropriate transformations. Data team workflows become more efficient and cost-effective because of this. Behind this tool sits an open-source community that is constantly and passionately developing the tool. As such, dbt is available both as a free, reduced core version and as a comprehensive and flexible cloud version.
How does Data Vault 2.0 with dbt work?
Part of the Data Vault 2.0 methodology is the model that focuses on how to design the core data warehouse with a scalable solution. The core Data Vault entities are hubs, links ,and satellites. That said, using Data Vault 2.0 with dbt provides the ability to generate Data Vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your data pipelines in a clean and efficient way.
Conclusion
Dbt does not reinvent the wheel, but when it comes to building a new EDW – especially if it is in the clouds – it provides a very helpful basic framework with many important functions for Continuous Integration and Deployment already defined. dbt brings the standards of software development into the world of data transformation. This allows developers to concentrate on the core tasks of data modeling and business logic. Especially, not only for smaller projects, this tool offers a lightweight and extremely affordable alternative to other data warehouse automation solutions.

Hi Ole,
since you mention dbt in the context of the Data Vault, it’s not clear whether you actually meant dbtvault, which supports the Raw Vault structures, but does not, for example, currently support Azure Synapse Analytics, or whether your intention was to recommend using the generic dbt for generating the Raw Vault structures. Could you clarify?
Thanks,
Gideon
Hi Gideon,
this article just describes how you can benefit from using dbt in your Data Vault project in general.
AutomateDV(formerly dbtvault) is currently not planning to support Synapse in the future and has also some drawbacks e.g. in loading patters that are not consistent with the Data Vault 2.0 standards.
We have released our own package datavault4dbt which is fully compliant with data vault 2.0 standards and also supports more entity types and we are currently working on Synapse support for our package. I can definetely recommend using this package.
If you can’t wait until the support is released you would need to implement everything by your own. Then you should definetely take use of macros to have repeatable patterns to generate your raw vault structures.