
Namenskonventionen im Data Warehousing
In diesem Artikel werden wir weitere Vorschläge für Namenskonventionen in einer data warehouse-Lösung vorstellen und Beispiele für Namensstandards geben, die sowohl unser Team als auch unsere Kunden intern verwenden. In diesem vorherigen Blogeintrag können Sie bereits erläuterte Aspekte unserer Namensgebung finden. Darin finden Sie eine Standarddokumentation - von der Groß- und Kleinschreibung bis zur Überlegung, ob Präfixe oder Suffixe in Datenbankobjektnamen verwendet werden sollen.
Schichtenschema
Für die Namen von Ebenenschemata werden bevorzugt Präfixe verwendet.
Wie im letzten Blogbeitrag beschrieben, erhöht diese Konvention die Sichtbarkeit bei der Datenexploration innerhalb des Enterprise Data Warehouse für Entwickler und Geschäftsanwender, indem Schemata der gleichen Data Warehouse-Schichten zusammengefasst werden.
Nachfolgend finden Sie eine Liste gängiger Enterprise Data Warehouse-Schichten und unsere entsprechenden Empfehlungen zu Namenskonventionen:
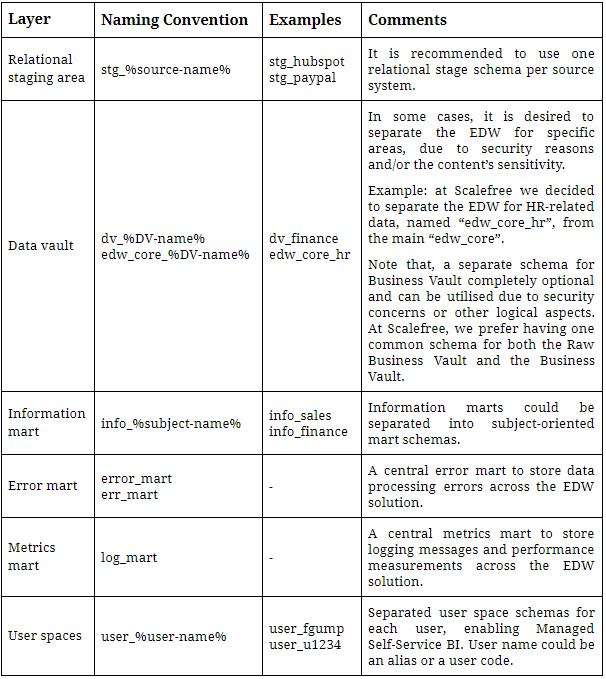
Abbildung 1: Empfohlene Benennungskonventionen für gängige Enterprise Data Warehouse-Schichten
EDW/Datenspeichereinheiten
Wie im vorangegangenen Abschnitt erläutert, trennen wir nicht zwischen dem Raw Data Vault und dem Business Vault in verschiedenen Datenbankschemata. Stattdessen können die Benutzer anhand des Entitätsnamens zwischen einer Raw Vault-Entität und einer berechneten Entität unterscheiden.
Im Folgenden finden Sie eine Liste von Namenskonventionen für Standard Data Vault 2.0 Entitäten zusätzlich zu den erweiterten Entitätstypen.
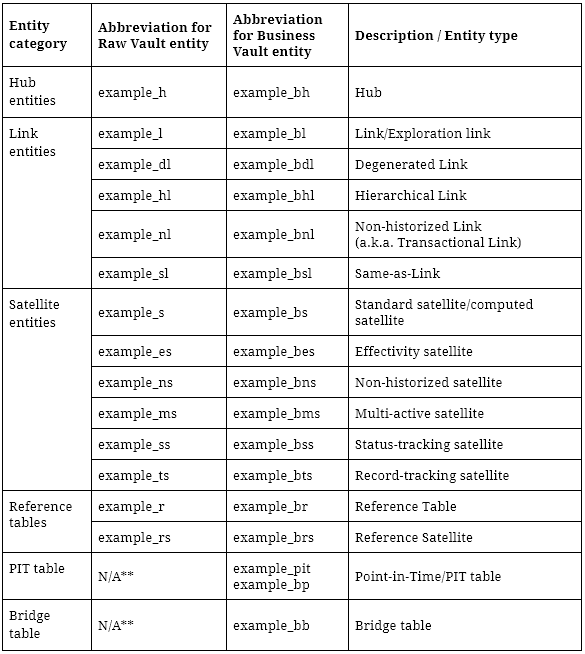
**Anmerkung: PIT und Bridge Tables sind nur im Business Vault verfügbar
Abbildung 2: Namenskonventionen für Standard-Data Vault-Entitäten
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsMehr über Benennungskonventionen für Satelliteneinheiten
Die Kriterien für die Aufteilung von Satelliten spielen eine wichtige Rolle bei den Namenskonventionen für Satellitenstrukturen. Es wird nämlich nicht empfohlen, dass alle beschreibenden Daten eines Geschäftsobjekts in einer einzigen Satellitenstruktur gespeichert werden - stattdessen sollten die Rohdaten vorzugsweise nach bestimmten Kriterien aufgeteilt werden. ( Linstedt, D., & Olschimke, M. (2016). Building a scalable Data Warehouse Warehouse with Data Vault 2.0. P114-115)
Bei Scalefree haben wir drei Arten von Satelliten-Splits definiert:
- aufgeteilt nach Quellensystem
- technische Aufteilung nach Änderungsrate, Sicherheitsstufe und Datenschutzstufe
- und geschäftsorientierte Aufteilung
Die Trennung von Satelitten nach Quellsystem und die technischen Anforderungen wie der Änderungsrate der Daten sind gängige und empfohlene Praktiken, wenn es um die Aufteilung beschreibender Attribute geht. Wir haben uns jedoch entschlossen, die Rohdaten noch weiter aufzuteilen, sowohl technisch als auch nach ihrer geschäftlichen Bedeutung.
Daher lautet unsere vollständige Namenskonvention für Satelliteneinheiten wie folgt:
[parent-obj]_[biz-split]_[src]_[tech-split]_[satellite-type-suffix]
Mit:
[parent-obj] = der Name des Geschäftsobjekts des übergeordneten Satelliten
[biz-split] = die Unternehmensklassifizierung,
[src] = eine Abkürzung für das Quellsystem und
[tech-split] = eine Kombination von technischen Kriterien für das Satellitensplitting.
Bitte beachten Sie, dass durch die Aufteilung der Daten in Sicherheitsstufen, die Daten ebenfalls in Sicherheitsgruppen klassifiziert werden. So erhalten die Endnutzer nur Zugang zu bestimmten Tabellengruppen, die ihrer Sicherheitsstufe entsprechen.
Im Rahmen unseres Vorgehens reichen die Sicherheitsstufen von:
- die niedrigste Vertraulichkeitsstufe - Stufe 0, 1: keine Sicherheitsmaßnahmen erforderlich, für öffentliche Daten,
- begrenzter Zugang zu bestimmten internen Parteien - Ebene A, R, C, F.
- auf die höchste Vertraulichkeitsstufe - Stufe S: streng geheim.
Es ist wichtig zu beachten, dass das letzte technische Kriterium für die Aufteilung von Satelliten innerhalb der SOP der Scalefree durch die Aufteilung der Privatsphäre definiert ist. Diese Trennung ist ein notwendiger Bestandteil des Prozesses, da sie persönliche und nicht-persönliche Informationen voneinander trennt.
Im weiteren Verlauf verteilt der geschäftsorientierte Satellitensplit die Rohdaten in verschiedene Satellitentabellen, wobei bestimmte geschäftliche Bedeutungen des Dateninhalts verwendet werden.
Zu diesem Zweck haben wir mehrere Klassifikationen definiert, darunter zum Beispiel „Kontakt“ für Kontaktdaten und „Aktivität“ für Daten, die Nutzerinteraktionen mit dem Quelldatensatz erfassen.
Darüber hinaus können Datenmodellierer auch benutzerdefinierte Klassifikationen für spezifische fachliche Bedeutungen innerhalb von Geschäftsobjekten definieren.
Beispielsweise werden alle Datenattribute einer Anwendung, die auf der CRM-Plattform Salesforce installiert sind, häufig in einer einzigen Satellitenstruktur gespeichert. Daher zielt die geschäftsorientierte Aufteilung der Satelliten darauf ab, die Benutzerfreundlichkeit und Zugänglichkeit des EDW für die Endbenutzer zu verbessern. Dies geschieht dadurch, dass die Benutzer die von ihnen benötigten Daten innerhalb des DWH schneller und einfacher finden können, indem sie die Daten in Gruppen einteilen, die für die Geschäftsbenutzer tatsächlich von Bedeutung sind.
Setzt man alles zusammen, ergibt sich zum Beispiel folgender Satellitenname in unserer internen EDW-Lösung::
customer_contact_sfdc_lcp_s
Das obige Objekt ist ein Satellit des Geschäftsobjekts Kunde und enthält die Kontaktinformationen der Kunden aus dem Quellsystem Salesforce. Sein Inhalt hat also eine niedrige Änderungsrate, eine Sicherheitsstufe von C und enthält personenbezogene Daten.
Fazit
In diesem Artikel haben wir unsere Empfehlungen bezüglich der Namenskonventionen für verschiedene Arten von data warehouse-Objekten vorgestellt und einen detaillierten Einblick in unsere Überlegungen zur Benennung von Satelliten gegeben.
Interessieren Sie sich für andere Aspekte des Namensstandards? Lassen Sie es uns im Kommentarbereich wissen!
- von Trung Ta