Enterprise Data Warehouses mit Data Vault 2.0
Während Enterprise Data Warehouses (EDWs) traditionell für Reporting und Dashboards genutzt werden, geht ihr wahres Potenzial mit Data Vault weit über diesen grundlegenden Anwendungen hinaus. Data Vault 2.0 bietet eine beispiellose Flexibilität und Skalierbarkeit, die es Unternehmen ermöglicht, neue Anwendungsfälle wie Datenbereinigung, operative Prozessautomatisierung und prädiktive Analysen zu realisieren. Dieser Artikel zeigt, wie Data Vault 2.0 Unternehmen dabei unterstützt, zentrale Datenbereinigungsregeln anzuwenden, die Datenqualität direkt an der Quelle zu verbessern und Total Quality Management (TQM) umzusetzen. Durch die volle Ausschöpfung der Möglichkeiten ihres EDWs können Unternehmen über reine Analysen hinausgehen und nachhaltige, agile sowie wirkungsvolle Datenstrategien entwickeln.
Mit Data Vault 2.0 über die Standard-Reporting hinausgehen
Reporting und Dashboarding sind in der Geschäftswelt zum Standard geworden, wenn es um die Ermittlung von KPIs und anderen Kennzahlen geht. Um diesen Berichtsprozess zu unterstützen, haben sich Enterprise Data Warehouses etabliert. Aufgrund der zunehmenden Datenmengen und -vielfalt ist jedoch der Bedarf nach Methoden entstanden, mit denen sich die vorhandenen Daten so nutzen lassen, dass zusätzlicher Nutzen für die individuellen Anforderungen eines Unternehmens geschaffen wird. Data Vault 2.0 bietet eine breite Palette an Methoden zur Entscheidungsunterstützung, die über das klassische Reporting hinausgehen, und liefert darüber hinaus wertvolle Informationen mit Blick auf zukünftige Entwicklungen. Überzeugen Sie sich selbst und begleiten Sie uns, wenn wir Ihnen verschiedene Ansätze und Lösungen vorstellen, mit denen Sie das volle Potenzial Ihrer Daten ausschöpfen können.
Flexibilität und Skalierbarkeit
Einfach ausgedrückt sammelt ein Enterprise Data Warehouse (EDW) Daten aus internen und externen Quellen eines Unternehmens, um sie für einfaches Reporting und Dashboards bereitzustellen. Häufig werden auf diese Daten analytische Transformationen angewendet, um die Reports und Dashboards noch nützlicher und wertvoller zu gestalten. Dabei bleiben jedoch oft weitere wertvolle Anwendungsfälle ungenutzt, die beim Aufbau eines Data Warehouses häufig übersehen werden. Denn EDWs verfügen über ein bislang ungenutztes Potenzial, das weit über die reine Auswertung vergangener Statistiken hinausgeht. Um diese Potenziale zu erschließen, bringt Data Vault ein hohes Maß an Flexibilität und Skalierbarkeit mit, um dies auf agile Weise zu ermöglichen.

Das Data Vault Handbook:
Grundlagen und moderne Anwendungen
Ihr Weg zu einer skalierbaren und resilienten Datenplattform
Das Data Vault Handbook ist eine leicht verständliche Einführung in Data Vault. Es richtet sich an Datenexperten und bietet einen klaren, zusammenhängenden Überblick über die Grundprinzipien von Data Vault.
Data Vault Anwendungsfälle
Zunächst einmal wird das Data Warehouse häufig lediglich zur Datensammlung und Vorverarbeitung von Informationen für Reporting- und Dashboard-Zwecke genutzt. Wer jedoch nur diesen einen Aspekt eines EDW ausschöpft, vergibt die Chance, das volle Potenzial der Daten zu nutzen, indem er das EDW auf solche grundlegenden Anwendungsfälle beschränkt.
Dabei lässt sich eine Vielzahl von Use Cases realisieren, beispielsweise zur Optimierung und Automatisierung operativer Prozesse, für Prognosen und Vorhersagen, zur Rückführung von Daten in operative Systeme als neuen Input oder zur Auslösung von Ereignissen außerhalb des Data Warehouses – um nur einige der zahlreichen Möglichkeiten zu nennen.
Datenbereinigung (innerhalb eines operativen Systems)
In Data Vault wird zwischen Rohdaten und Geschäftsdaten unterschieden. Rohdaten werden im Raw Data Vault gespeichert, Geschäftsdaten im Business VaultInnerhalb von Data Vault 2.0 dient der Raw Data Vault dazu, sowohl gute, schlechte als auch fehlerhafte („hässliche“) Daten exakt so zu speichern, wie sie vom Quellsystem geliefert werden. Der Business Vault hingegen kann auf Basis definierter Geschäftsregeln jede gewünschte fachliche Sichtweise ableiten – etwa durch die Berechnung einer KPI wie den Gewinn, gemäß einer vom Fachanwender definierten Geschäftsregel.
Für Reporting- und Dashboard-Zwecke werden üblicherweise Datenbereinigungsregeln angewendet, um die Daten für die jeweilige Analyse besser nutzbar zu machen und somit Rohdaten in wertvolle Informationen zu transformieren. Diese Geschäftsregeln zur Datenbereinigung können jedoch auch genutzt werden, um die bereinigten Daten in das operative System zurückzuschreiben. Idealerweise werden diese Regeln über virtualisierte Tabellen und Views innerhalb des Business Vault umgesetzt. Die bereinigten Daten können anschließend wieder in das operative System zurückfließen, um das Konzept des Total Quality Management (TQM) zu realisieren, bei dem Fehler an der Wurzel behoben werden, die häufig im Quellsystem selbst liegt.
Die Verwendung des EDW für die Datenbereinigung kann also mehrere Vorteile haben. Bei klassischen Datenbereinigungstools ist es oft nicht möglich, komplexe Skripte auszuführen. Die meisten Tools haben vordefinierte Listen von Ländern usw., um einige ausgewählte Attribute zu bereinigen. Außerdem sind die meisten Tools für die Bereinigung von Daten aus nur einem einzelnen operatives Quellsystem konzipiert und lassen Inkonsistenzen zwischen mehreren operativen Systemen außer Acht.
Aus der Sicht von Data Vault sind Datenbereinigungsregeln gewöhnliche Geschäftsregeln. Das heißt, sie werden mit Hilfe von Business Satellites implementiert, häufig unter Einbeziehung von Referenztabellen. Die folgende Abbildung zeigt ein Beispiel für eine Datenbereinigung auf Basis einer Data Vault 2.0 Architektur wie sie intern bei Scalefree.
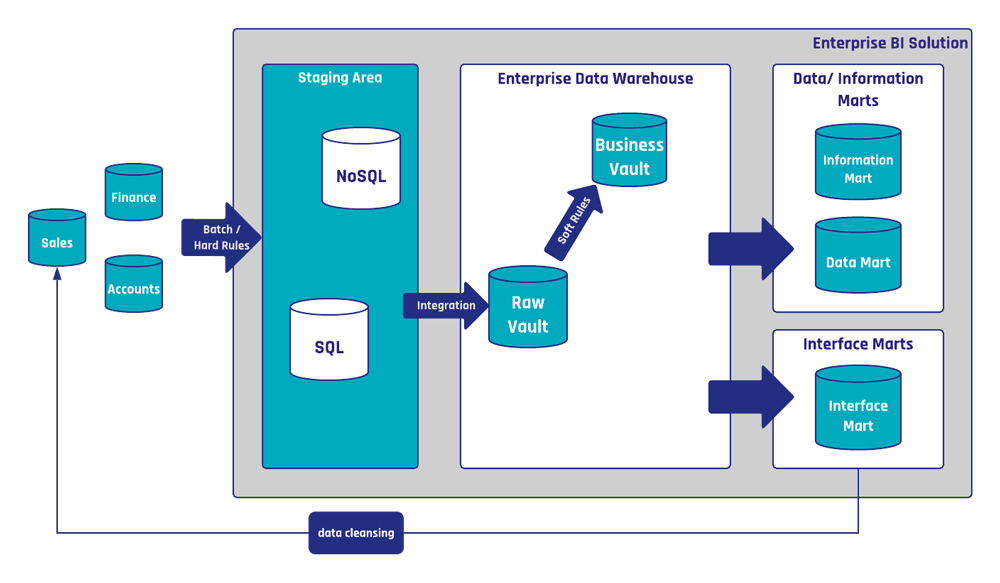
Das Scalefree-EDW dient als zentrale Bibliothek für Datenbereinigungsregeln, die in verschiedenen Systemen – sowohl im EDW als auch in operativen Systemen – verwendet werden können. Der dargestellte Datenbereinigungsprozess wird unter anderem genutzt, um Kundendatensätze zu bereinigen sowie Telefonnummern und die zugehörigen Adressen zu standardisieren. Neben den Information Marts existiert der Interface Mart „Sales Interface“, der die API des Vertriebssystems implementiert und Datenbereinigungsregeln aus dem Business Vault anwendet. Ein periodisch ausgeführtes Skript lädt die Daten aus dem Interface Mart über die API in das Quellsystem. In diesem konkreten Fall ist das Skript in Python geschrieben.
Ein wichtiger Aspekt dieses Prozesses ist die sorgfältige Dokumentation der Datenbereinigungsregeln. Eine interne Wissensplattform wird verwendet, um die Dokumentation jeder einzelnen Regel zu speichern. So kann jeder Mitarbeiter, der auf die Dokumentation zugreift, nachvollziehen, welche Regeln für die operativen Daten angewendet wird. Dies kann auch für Fachanwender von Nutzen sein, da sie dann verstehen können, warum ihre Daten über Nacht korrigiert wurden.
Fazit
Dank der Flexibilität von Data Vault können Unternehmen neue Möglichkeiten erschließen, die über reines Reporting und Dashboarding hinausgehen. So kann das Data Warehouse zur Datenbereinigung innerhalb operativer Systeme eingesetzt werden, indem zentral definierte Bereinigungsregeln angewendet werden.
Wenn Sie mehr über Data Vault Anwendungsfälle und die neuesten Technologien am Markt erfahren möchten, bietet das World Wide Data Vault Consortium (WWDVC) eine hervorragende Gelegenheit dazu. Hier haben Sie die Möglichkeit, mit den erfahrensten Experten auf diesem Gebiet in direkten Austausch zu treten. In diesem Jahr findet die Konferenz erstmals vom 9. bis 13. September in Hannover, Deutschland, statt.
Dort wird Ivan Schotsmans über Informationsqualität im Data Warehouse sprechen. In seinem Vortrag zeigt er auf, wie aktuelle und zukünftige Herausforderungen der Data Warehouse Architektur bewältigt werden können, wie sich ein agiler Ansatz bei der Implementierung eines neuen Data Warehouse umsetzen lässt und wie das Business stärker eingebunden werden kann. Um diese Gelegenheit nicht zu verpassen, melden Sie sich noch heute an und sichern Sie sich spannende Vorträge von Wherescape, Vaultspeed sowie zahlreichen weiteren Anbietern und Experten!
Hi,
interesting approach, thanks for the post. I have a question on where those data cleansing rules are being applied…
1) Between the source systems and staging systems –> I assume not as we want the staging area to be a loading-only to offload the source system asap. No? What are the ‘hard rules’ between the source and staging?
2) the data cleansing between the interface marts and source systems seems to be outside the vault? Does this mean you do not keep the ‘cleaned’ up data in the vault directly? (but it would automatically come in after a next load from source)
Thank you
Thank you for your comment!
Under the term “hard business rules” we classify technical rules that enforces correct data format while loading data from source systems into the staging layer. For instance, if an attribute provides information about points in time, then it should be of data type TIMESTAMP or equivalent. However source systems sometimes don’t deliver the correct type. In this case, the attribute should be remapped to the correct data type. Additionally, hard business rules can be normalization rules that handle complex data structures, e.g. to flatten nested JSON objects.
About your question regarding data cleansing: in our example, the data cleansing operation takes place both inside and outside the Data Vault. To clarify the idea behind this operation, the process starts with sourcing data from the Raw Vault, then soft rules that correct phone number and address formats would be applied onto the raw data and the results are written in Business Vault structures. The Interface Mart only selects cleansed records from the Business Vault, which haven’t yet been written back into the source operational system. And from there, an external script loads the data from the Interface Mart into the source system’s API – to update the original records with the correct, standardized format for phone numbers and addresses.
And you are correct – this external script doesn’t load the data from the Interface Mart into the Raw Vault, since the updated records in the source system should show up in the next staging operation and will be picked up into the Raw Vault then.
I hope that answers your questions.
Thank you kindly,
Trung Ta