
Data Vault 2.0 Implementierung
Data Vault 2.0 wird häufig nur als Modellierungstechnik verstanden, umfasst jedoch weitaus mehr. Es handelt sich um eine vollständige BI-Lösung, die agile Methodik, Architektur-, Implementierung und Modellierung miteinander vereint.
Warum also Data Vault verwenden?
- Data Vault 2.0 ermöglicht es, automatisierte Ladeprozesse/-muster zu erstellen und Modelle sehr einfach zu generieren
- Plattformunabhängigkeit
- Prüfbarkeit (Auditability)
- Skalierbarkeit
- Unterstützt ELT- anstelle von ETL-Prozesse
Nachdem wir nun das Warum beantwortet haben, fragen Sie sich vielleicht, welche Schritte erforderlich sind, um Data Vault 2.0 in Ihrem Projekt zu implementieren.
Das hängt von vielen Faktoren ab, z. B. von Ihrem Geschäftsfall, der gewünschten Architektur, der Art und Weise, wie Ihre Datenquellen geladen werden, dem Zeitplan für Ihr Projekt usw.
Schritt-für-Schritt-Anleitung zur Implementierung von Data Vault 2.0
Für Anfänger kann es etwas überwältigend sein, mit Data Vault 2.0 zu beginnen und herauszufinden, wie und wo man es implementiert. In diesem Webinar wird ein sehr grundlegender Leitfaden zur Verfügung gestellt, der die notwendigen Schritte für eine Data Vault 2.0-Implementierung auf der Grundlage von Geschäftsanforderungen von Grund auf aufzeigt. Dies geschieht anhand eines Beispiels, das von der Erfassung einiger Beispielanforderungen bis zum fertigen Produkt reicht.
Data Vault 2.0: Featurebasierte Architektur
Eines steht fest: Die Architektur sollte vertikal aufgebaut werden, nicht horizontal. Das bedeutet nicht Schicht für Schicht, sondern Feature für Feature.
Ein gängiger Ansatz hierfür ist der Tracer Bullet-Ansatz. Auf der Grundlage des Mehrwerts fürs Unternehmen, der durch einen Bericht, ein Dashboard oder ein Information Mart definiert ist, müssen die Quelldaten identifiziert, modelliert und durch alle Schichten der Architektur geladen werden.
Nehmen wir zum Beispiel an, dass die Geschäftsanforderung darin besteht, ein Dashboard zu erstellen, um die Verkaufszahlen des Unternehmens zu analysieren:
1. Extraktion (Extract)
Als Erstes müssen wir die Daten aus den Quellsystemen extrahieren und sie im Rohzustand ablegen. In diesem Beispiel speichern wir sie in einem vorübergehenden Staging Layer, alternativ könnte jedoch auch ein persistenter Staging Layer in einem Data Lake genutzt werden.
2. Transformieren (Transform)
Als Nächstes sollten Sie, wenn nötig, einige Hard Rules anwenden. Seien Sie dabei vorsichtig, denn Sie wollen hier keine betriebswirtschaftlichen Berechnungen mit Hilfe eines Transformationstools durchführen. Es gibt viele verschiedene Data Warehouse-Automatisierungstools wie dbt, Coalesce, WhereScape, usw., die zur Verfügung stehen
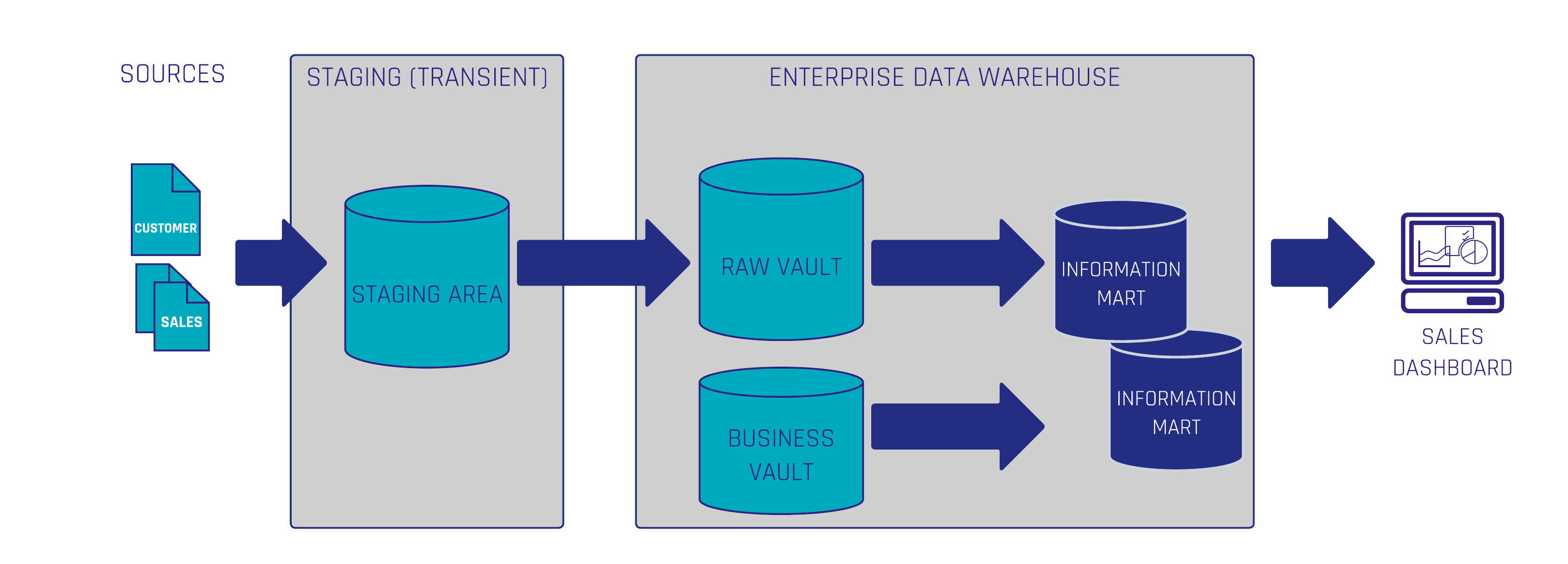
3. Laden (Load)
Laden Sie Ihre Raw Stage in den Raw Vault.
4. Business-Anforderungen modellieren
Modellieren Sie die Data Vault-Entitäten, die zur Erfüllung der jeweiligen Business-Anforderung benötigt werden. Wenn wir zum Beispiel Verkaufstransaktionen und Kundendaten haben, modellieren wir einen Non-Historized Link, auch Transactional Link genannt, und einen Customer Hub – ergänzt durch Satelliten, die die beschreibenden Daten der Kunden enthalten, die wir später im Sales Dashboard anzeigen möchten.
5. Business-Logik anwenden
Nun benötigen wir einige Berechnungen und Aggregationen. Dazu bauen wir Business-Logik auf Basis der Raw Vault Entitäten auf und laden diese in den Business Vault.
6. Information Mart erstellen
Zwar könnten wir die Daten direkt aus dem Raw Vault und dem Business Vault für Dashboards oder Diagramme nutzen, aber um die Daten für Business User besser strukturiert und leicht zugänglich bereitzustellen, bauen wir einen Information Mart mit einem Sternschema – bestehend aus einer Faktentabelle und den dazugehörigen Dimensionen.
7. Daten visualisieren
Um das Sales Dashboard in einem BI-Tool wie Power BI oder Tableau zu erstellen, greifen wir nun direkt auf das Sternschema im Information Mart zu. Dort finden sich alle benötigten Informationen, verbunden mit unserem Data Warehouse in der zugrunde liegenden Datenbank.
Data Vault 2.0 bietet einen agilen, skalierbaren und flexiblen Ansatz für die Automatisierung von Data Warehousing . Wie im Beispiel gezeigt, haben wir nur die Data Vault-Tabellen modelliert, die zur Umsetzung der Aufgabe – dem Aufbau eines Sales Dashboards – notwendig waren. Auf diese Weise können Sie Ihre Lösung bedarfsgerecht skalieren, ohne das gesamte Unternehmen auf einmal modellieren zu müssen.
Die Antwort auf die Frage, wie man Data Vault 2.0 implementiert, lässt sich in einem einfachen Satz zusammenfassen: Konzentrieren Sie sich auf den Mehrwert fürs Unternehmen!
Wenn Sie eine Schritt-für-Schritt-Anleitung dieser Implementierung mit echten Beispieldaten in dbt als Transformationstool sehen möchten, schauen Sie sich diese Webinar-Aufzeichnung an.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsFazit
Die Implementierung von Data Vault 2.0 folgt einem strukturierten Ansatz: Sie beginnt mit der Extraktion von Daten aus Quellsystemen in ein Staging Area, gefolgt von minimal notwendigen Transformationen und dem Laden in den Raw Vault. Darauf aufbauend werden – gesteuert durch konkrete Business-Anforderungen – die Data Vault-Entitäten modelliert, Business-Logik angewendet, Information Marts aufgebaut und schließlich die Daten visualisiert. Diese featurebasierte Methodik gewährleistet Skalierbarkeit und Flexibilität und ermöglicht es Unternehmen, ihre Entwicklung Schritt für Schritt auf den Mehrwert fürs Unternehmen auszurichten. Durch die Orientierung an klar definierten Anforderungen können Organisationen ihre Data Warehouse-Lösung effizient aufbauen und gezielt weiterentwickeln.