Data Quality as the Basis for solid decision-making
When making business decisions, data quality is a critical facet to factor into the decision-making processes. Thus, the immediate access to the data and certainty on its quality can enhance business performance immensely. But the sad truth is that we see bad data in operational systems due to human-caused errors such as typos, ignoring standards and duplicates, in addition to lack of input-validators in operating systems such as must-fields not being declared as well as references to other entities (primary-foreign-key constraints) not being defined.
In this article:
Data Quality in Data Vault 2.0
In decision support systems, business users eventually expect to see high quality data down the stream. However, the quality of data can be subjective. What might be considered as wrong data to a business user, can also be correct and valuable data to another business user. For this reason when loading a data warehouse, we would want to load all data and leave nothing behind. In any way, the data warehouse should provide both “single version of facts” as well as “versions of the truth” which is represented in Data Vault 2.0 as Raw Data Vault and Business Vault. For this to be accomplished, the core data warehouse, that being the raw data vault layer, must remain untouched. The best way to fix the data should be proactive and start in the business information systems or operational systems. This way we can avoid the continuous flow of bad data at once. However, this method is often rejected as it is considered to be costly due to enterprise alignment or errors in the source system.
Data Quality in the Business Vault
The second best practice is implementing data quality routines by applying soft business rules in the data warehouse. Soft business rules are implemented in the Business Vault or in the loading process of the Information Marts. Any data quality routines should be implemented in these places as well. By implementing data quality as soft business rules, the incoming raw data is not modified in any way and remains within the enterprise data warehouse for further analysis. If the data quality rules change, or new knowledge regarding the data is obtained, it is possible to adjust the data quality routines without having to reload any previous raw data. Now, this practice can make the first method possible when we write the correct data from Information Marts back to operational systems.
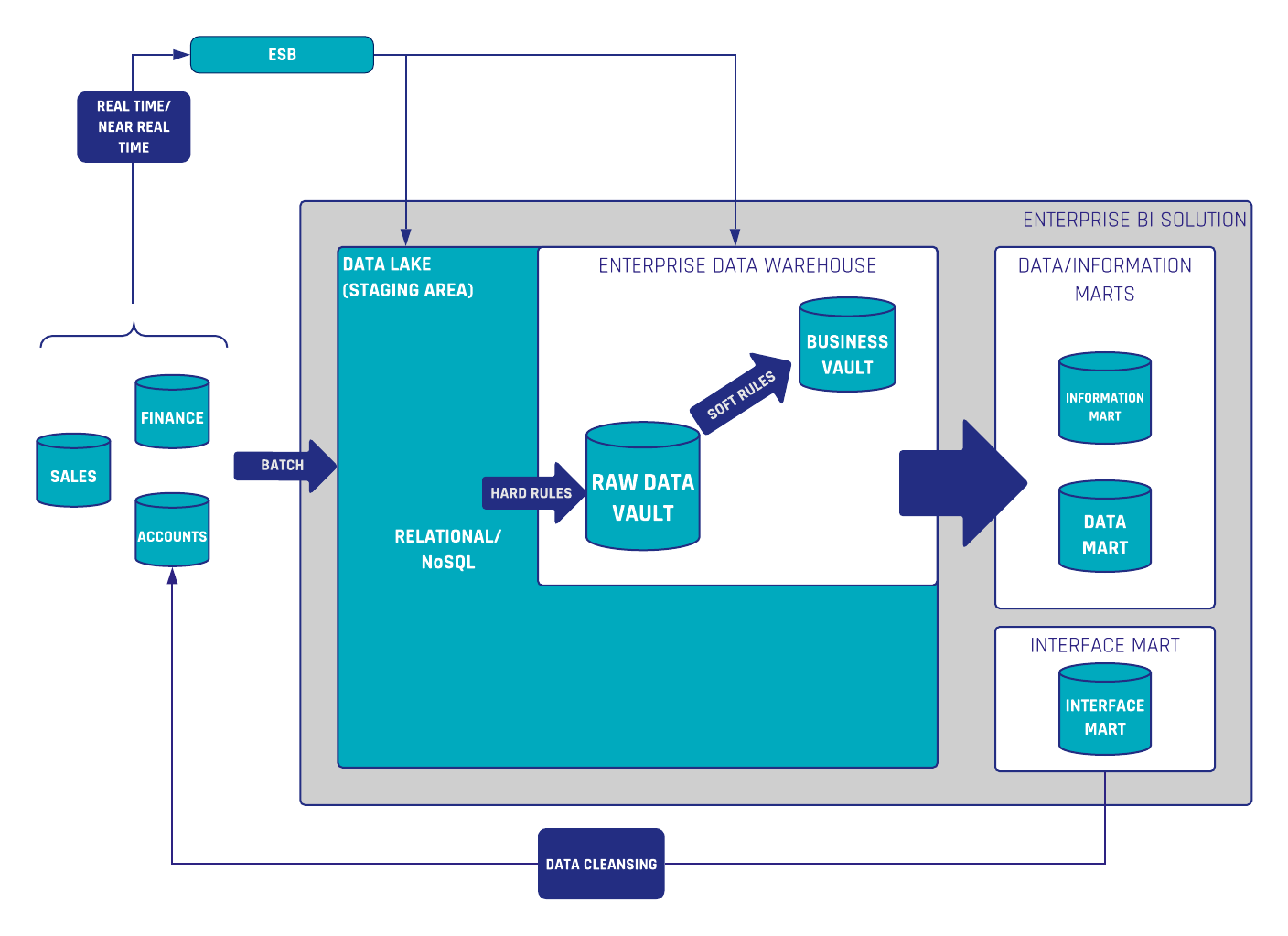
Figure 1. Data Cleansing
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsWrite Back quality data to operational system (source system)
An example of our data quality routines at Scalefree is the quality check of phone-numbers in the CRM system Salesforce. Phone-numbers sometimes show as an unreadable or hard to read form or can be incomprehensible by automated processes and other operational applications. So with this routine, we read the data from the Raw Data Vault, a cleansing or quality job script then rearranges these numbers in a readable and comprehensible form. After which, the data is then provided to an Information Mart (or what we call in this case: Interface Mart) which in turn can then be used to send this data back to the operational source system itself. This is where business users can also use this data in their business operations without having to go downstream. The next time when loading the raw data into the Raw Data Vault, the data is already cleansed.
Conclusion
If possible, fix your data in the source system first to ensure accuracy at the source. The Raw Vault should always remain an untouched replica of the data delivered by the source system. Data quality routines should be performed in the Business Vault, where transformations and validations take place. Finally, write cleaned and validated data back into the source system as needed.
