There are two competing approaches to data analytics available in the industry, and most professionals at least tend to one or the other as the preferred tool of choice: data warehousing vs data lake. This article sheds light on the differences between both approaches and how Data Vault 2.0 provides a best of breed solution that integrates the advantages of both approaches into a unified concept.
About Data Warehousing
Data Warehousing is the traditional enterprise solution for providing reliable information to decision makers at every level of the organization. Data warehouse solutions (but also data lakes) are based on a data model, which is traditionally defined on the basis of either the information requirement in a bottom-up approach or in a top-down approach based on an integrated enterprise information model.
In any case, the traditional data warehouse is based on a concept called “schema-on-write” where the data model is established when loading the data into the data warehouse. This often leads to non-agile data processing, as this data model often requires modifications in order to cope with changes in the business.
About Data Lakes
Data lakes, on the other hand, are based on the “schema-on-read” concept. Instead of modeling the enterprise or fitting the incoming dataset into a target information model, the data is first and foremost stored on the data lake as delivered without any modelling applied.
While traditional data warehousing often leads to overmodeling and non-agile data analytics, the data lake approach often leads to the direct opposite: to unmanaged data and inconsistent information results.
The Best of Breed
Both approaches are on the extreme ends of the data analytics space and used throughout the years with mixed results. With the emergence of the Data Vault 2.0 concept, a third option is available to industry professionals to build data analytics platforms.
Data Vault 2.0 is a best of breed between traditional data warehousing and data lakes: for example, there is a data model to manage the data and business logic as in traditional data warehousing, but it follows a schema-on-write approach as in data lakes.
The Data Vault 2.0 architecture comprises multiple layers:
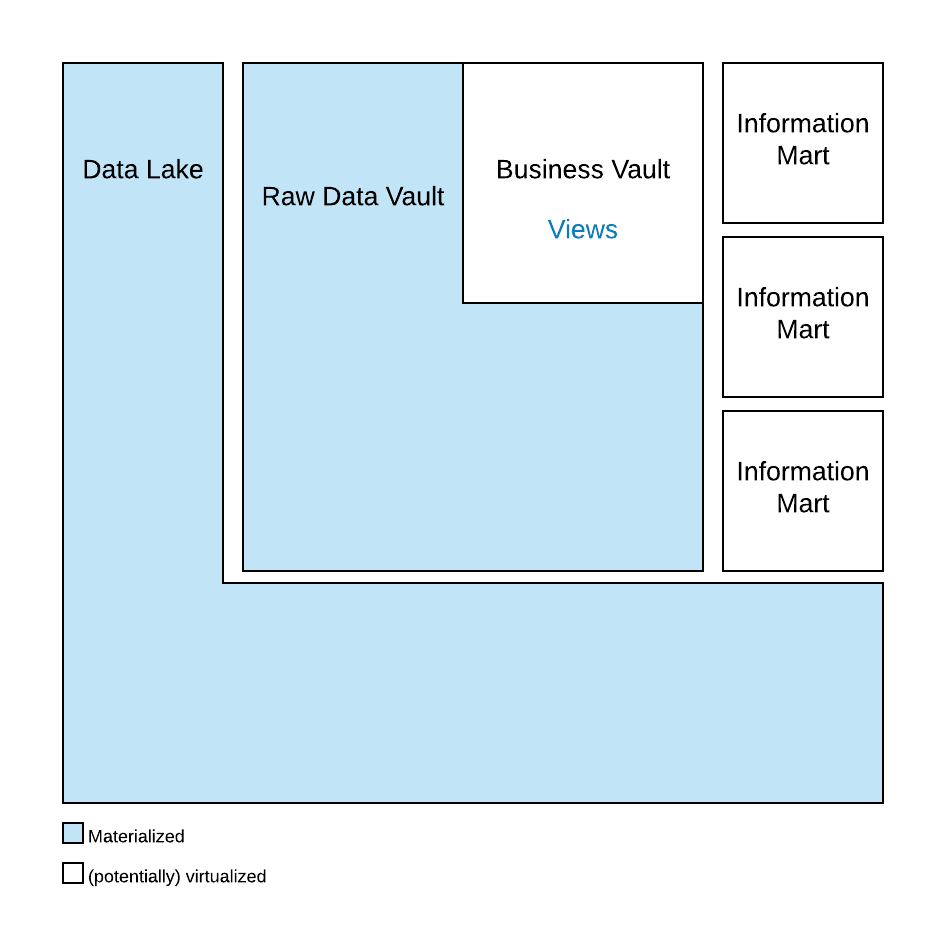
The first layer is the staging area: it is used to extract the data from the source systems. The next layer is the Raw Data Vault. This layer is still functionally oriented as the staging layer, but integrates and versionizes the data. To achieve this, the incoming source data model is broken down into smaller components: business keys (stored in hubs), relationships between business keys (stored in links) and descriptive data (captured by satellites).
The Business Vault is the next layer, but only sparsely modelled: only where business logic is required to deliver useful information, a Business Vault entity is put in place. The Business Vault bridges the gap between the target information model (as in the next layer) and the actual raw data. Often, the raw data doesn’t meet the expectations of the business regarding data quality, completeness, or content and thus needs to be adjusted. Business logic is used to fill the gap.
The final layer is the information mart layer where the information model is produced to deliver the final information in the desired format, e.g., a dimensional star schema. This model is used by the business user either directly in ad-hoc queries or using business intelligence tools such as dashboarding or reporting software.
The first layers until the Raw Data Vault are still functionally oriented because the model is still derived either directly from the source system (as in the staging area) or by breaking down the incoming data model into smaller, normalized components, as in the Raw Data Vault. The target schema is only applied at the latest layer, the information mart layer. This is when the desired information model is applied. Because the information mart is often virtualized using SQL views, the target schema is actually applied during query time. Queries against the view layers are merged with the SQL statements inside the view layer and run against the materialized tables in the Raw Data Vault, the actual data. Therefore, the schema-on-read concept is used in Data Vault 2.0.
Data Vault 2.0 also preserves the agility: the concept has demonstrated in many projects that it is easy to extend over time when either the source system structures change, the business rules change or the information models need to be adjusted. In addition, it is easy to add new data sources, additional business logic and additional information artifacts to the data warehouse.
On top of that, the Data Vault 2.0 model is typically integrated with a data lake: the above diagram shows the use of a data lake for staging purposes, which is the recommended “hybrid architecture” for new projects at Scalefree. But the data lake can also be used to capture semi-structured or unstructured data for the enterprise data warehouse or to deliver unstructured information marts.
With all that in mind, the Data Vault 2.0 concept has been established itself as a best of breed approach between the traditional data warehouse and the data lake. Organizations of all sizes use is to build data analytics platforms to deliver useful information to their decision makers.
