Scalefree hat untersucht, ob KI einen Data Vault Engineer ersetzen kann. Die Genauigkeit war perfekt, doch Aufwand und Leistungslücke erzählten eine andere Geschichte.
Jedes Datenteam stellt sich derzeit die gleiche Frage: Wenn KI SQL schreiben, Dokumentationen erstellen und komplexe Strukturen eigenständig abfragen kann – welche Aufgaben bleiben dann eigentlich noch für den Data Engineer?
Kann ein KI-Agent ein Raw Data Vault selbständig abfragen? Benötigt ein Unternehmen noch erfahrene Engineers, um ein Vault zu modellieren, zu dokumentieren und zu pflegen, wenn die KI dies theoretisch selbst ermitteln könnte? Wir haben das Experiment durchgeführt. Die Ergebnisse waren unerwartet.
Conversational Analytics meistern: Ein praktischer Leitfaden für Einrichtung, Test und Optimierung
Erfahren Sie, wie Sie mit den Daten Ihres Unternehmens in Alltagssprache kommunizieren und präzise, sofortige Antworten auf Basis Ihrer individuellen Kennzahlen erhalten. Dieses praxisorientierte Webinar zeigt Ihnen eine Strategie, mit der Sie KI-Halluzinationen vermeiden und zuverlässige KI-Datenassistenten implementieren – ohne umfassende, kostspielige Umstrukturierungen. Melden Sie sich zum kommenden Webinar am 16. Juni 2026 an! (Kostenlose Registrierung)
Kommt Ihnen das bekannt vor?
Ihr LinkedIn-Feed ist voll von Aussagen wie: „KI kann SQL schreiben.“ „Stellen Sie Ihren Daten einfach eine Frage.“ „Kein Engineer erforderlich.“ Und tatsächlich: Einiges davon stimmt. KI-Agenten werden zunehmend besser darin, Datenstrukturen abzufragen, für die vor zwei Jahren noch Spezialwissen nötig war.
Die Frage ist also berechtigt: Wenn eine KI durch Raw-Data-Vault-Entitäten navigieren, Hubs mit Links und Satellites verknüpfen und eine korrekte Antwort liefern kann – welche Rolle bleibt für den Data Vault Engineer?
Scalefree wollte nicht länger über diese Frage diskutieren, sondern sie messen. Gleiche Daten, identischer KI-Agent, zwei Architekturen: eine schlanke Fact Table mit neun Spalten und ein vollständiges Raw Data Vault mit zwölf Tabellen. Zwanzig Fragen wurden jeweils beiden Systemen gestellt.
Das Ergebnis bei der Genauigkeit? Gleichstand. Das Gesamtbild? Weitaus differenzierter.
Die Einrichtung hinter den Ergebnissen
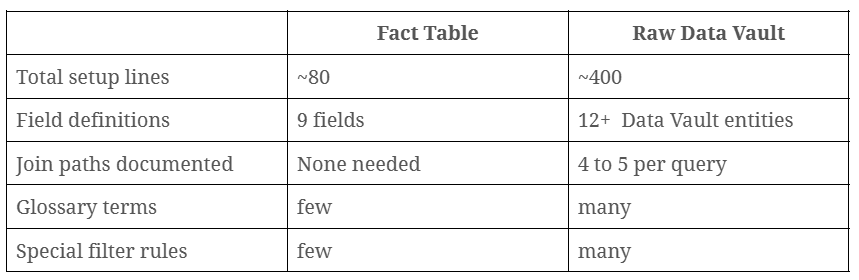
Beide Agenten basierten auf Googles Gemini Data Analytics SDK, einem sofort einsatzbereiten Python-Toolkit, das sich direkt mit BigQuery verbindet und die NL2SQL-Pipeline standardmäßig abwickelt. Doch bevor einer der Agenten eine einzige Frage beantworten konnte, benötigten beide einen detaillierten Satz von Systemanweisungen: Tabellenbeschreibungen, Felddefinitionen, Glossarbegriffe, Abfragehinweise. Hinter jeder dieser Informationen steht eine Person, die die Daten gut genug kennt, um sie präzise zu beschreiben. Diese Rolle verschwindet durch KI nicht – sie wird vielmehr noch wichtiger.
So sah dies in der Praxis aus:
Die Anweisungen für die Fact Table ließen sich in einem Durchgang erstellen. Das Raw Vault erforderte die Dokumentation jedes Join-Pfads, jeden Satellite-Filters und jeder Entitätsbeziehung, bevor der Agent korrekt schlussfolgern konnte. Das bedeutete fünfmal so viel Dokumentation für das gleiche Ergebnis.
Beide auf dem Prüfstand
Der Test war so angelegt, dass er sich in der Komplexität steigerte. Die ersten fünf Fragen waren einfach: Gesamtanzahl der Buchungen, Filterung nach Bürostandort. Dann kamen Datums- und Zeitlogik: bestimmte Tage, Monatszeiträume, tägliche Aufschlüsselungen. Die mittlere Stufe betraf die Daueranalyse: durchschnittliche Buchungslängen, das längste Zeitfenster, exakte Übereinstimmungen in Minuten. Danach folgten Muster nach Wochentagen: welcher Wochentag am häufigsten genutzt wurde, wie Montage im Vergleich abschnitten. Die letzten fünf Fragen kombinierten alle Aspekte – multidimensionale Abfragen, bei denen Standort, Zeit und Ressourcentyp in einer einzigen Antwort zusammengeführt werden mussten. Hier ein Auszug aus den letzten drei Stufen:

Auszug aus der Benchmark-Test-Suite mit 20 Fragen
Eine bewusste Designentscheidung: keine personenbezogenen Daten. Namen und E-Mail-Adressen befinden sich in einem zugriffsbeschränkten Bereich des Vaults, auf den der Agent nicht zugreifen kann. Die Fact Table wurde von Anfang an entsprechend gestaltet. Ein fairer Test und saubere Data Governance.
Die Ergebnisse
Ehrlich? Niemand hatte mit einem perfekten Genauigkeitsergebnis gerechnet. Und unter uns: Als Data Vault Engineers hatten wir gehofft, dass es nicht so kommt.
Beide Architekturen beantworteten jede einzelne Frage korrekt. Der KI-Agent bewältigte ein Vault mit zwölf Tabellen inklusive Hubs, Links und Satellites genauso souverän wie eine einzelne, flache Tabelle. Das ist beeindruckend – und ein wenig ernüchternd. Es zeigt auch: Die Modellierung und Dokumentation wurden korrekt durchgeführt. Mit einer schlecht beschriebenen Struktur sind 20 von 20 Punkten unmöglich.
Doch betrachten Sie die letzten beiden Spalten: Das Raw Vault benötigte insgesamt 33 Minuten, um das zu leisten, was die Fact Table in sechs Minuten schaffte. Das entspricht durchschnittlich 1,65 Minuten pro Frage gegenüber 0,3 Minuten bei der Fact Table. Gleiches Ziel, aber fünfmal längerer Weg.
Was das für Ihr Unternehmen bedeutet
Übertragen wir diese Zahlen auf die geschäftliche Praxis:
33 Minuten Gesamtabfragezeit gegenüber sechs Minuten. Das sind durchschnittlich 1,65 Minuten pro Frage gegenüber 0,3 Minuten bei der Fact Table. Für Business-Anwender, die schnelle Antworten erwarten, ist dieser Unterschied spürbar. Und bevor überhaupt eine Abfrage lief, benötigte das Raw Vault etwa 400 Zeilen Systemanweisungen – geschrieben von jemandem, der die Daten tief genug versteht, um sie präzise zu beschreiben.
Das bedeutet nicht, dass das Raw Data Vault die falsche Wahl ist. Für das Enterprise-Datenmanagement bleibt es der Goldstandard. Doch ein KI-Agent, der direkt darauf arbeitet – ohne Semantic Layer und erfahrene Engineers – führt zu langsamen Antworten und frustrierten Nutzern.
Bauen Sie das Vault auf, und erstellen Sie darüber eine Fact Table als KI-taugliche Schicht. Diese Kombination vereint die Vorteile beider Ansätze. Sie gibt Ihrem Data Vault Engineer eine Aufgabe, die KI nicht übernehmen kann: Jemand muss die Daten gut genug kennen, um sie zu beschreiben und so modellieren, dass die KI damit arbeiten kann. Diese Rolle wird nicht verschwinden.
Die wichtigsten Erkenntnisse
- Bewerten Sie Ihr KI-Setup nicht nur anhand der Genauigkeit. Berücksichtigen Sie auch Abfragezeit und Einrichtungsaufwand.
- Eine gut modellierte Fact Table liefert schnelle, zuverlässige Conversational Analytics mit minimalem Aufwand.
- Ein Raw Data Vault kann diese Genauigkeit erreichen, benötigt aber fünfmal mehr Dokumentation und läuft fünfmal langsamer.
- Gute Dokumentation erfordert jemanden, der die Daten versteht. KI kann das nicht für Sie übernehmen – zumindest noch nicht.
- Die beste Architektur für KI-Analysen ist kein Entweder-oder: Nutzen Sie das Vault für Datenintegrität und die Fact Table als KI-Schicht.
- Ihr Data Vault Engineer ist kein Kostenfaktor, den man streichen kann. Er ist der Grund, warum das alles funktioniert.
Was als Nächstes kommt
Die gesamte Geschichte erfahren Sie in unserem kommenden Webinar: Conversational Analytics meistern – Ein praktischer Leitfaden für Einrichtung, Test und Optimierung. Live-Abfragen, echte Fehlerbeispiele, ein praktischer Entscheidungsrahmen – und das alles mit echten Unternehmensdaten. (Hier kostenlos registrieren)
In der Zwischenzeit teilen Sie uns gerne Ihre Situation mit: Arbeiten Sie mit einem Raw Vault, einer Fact Table oder einem anderen Ansatz? Hinterlassen Sie einen Kommentar – wir lesen alle.