In today’s AI-driven world, businesses are looking for smarter, cost-effective chatbot solutions that enhance customer interactions and streamline internal operations. While traditional chatbot models often struggle with outdated or generic responses, modern advancements have opened the door to more dynamic and intelligent systems.
This article is for business leaders, developers, and AI enthusiasts looking to implement smarter chatbot solutions. It explores Retrieval-Augmented Generation (RAG), a game-changing approach that enhances chatbot performance by retrieving relevant information in real time. By the end, you’ll not only understand why RAG is so powerful but also how to implement it effectively to build scalable, cost-efficient, and context-aware chatbots using Google Cloud Platform Services.
Implementing Production-Ready RAG Chatbots: Enhancing Information Retrieval with AI
Join our webinar for a practical guide to building and deploying powerful, RAG-driven chatbot solutions. We’ll show you how to leverage essential Google Cloud services for effective implementation, enabling your chatbot to deliver more accurate and relevant responses. Register for our free webinar, July 15th, 2025!
The Challenge of Deploying Chatbots
Chatbots are widely used in businesses to automate customer support and streamline internal operations. While large language models (LLMs) have improved chatbot capabilities by generating human-like responses, they come with significant challenges. LLMs require costly fine-tuning, extensive resource usage, and ongoing maintenance, making them impractical for many companies. Additionally, fine-tuned models quickly become outdated, requiring frequent retraining to stay relevant.
An alternative approach is Retrieval-Augmented Generation, which dynamically retrieves relevant information in real time, rather than relying solely on pre-trained data. This allows chatbots to stay up-to-date, reduce costs, and improve accuracy, making RAG a powerful solution for businesses looking for intelligent and scalable AI-driven chatbots without the high expenses of fine-tuning or pre-training.
RAG Architecture
RAG is revolutionizing the way chatbots interact and provide information. But how does this powerful architecture actually work? The magic lies in its two distinct phases: The Preparation Phase, where the knowledge base is built, and the Retrieval Phase, where user queries are processed and relevant information is retrieved to generate a response. Each phase plays a crucial role in creating an intelligent and responsive system. Let’s explore how RAG works in detail, starting with the preparation phase.
Preparation Phase
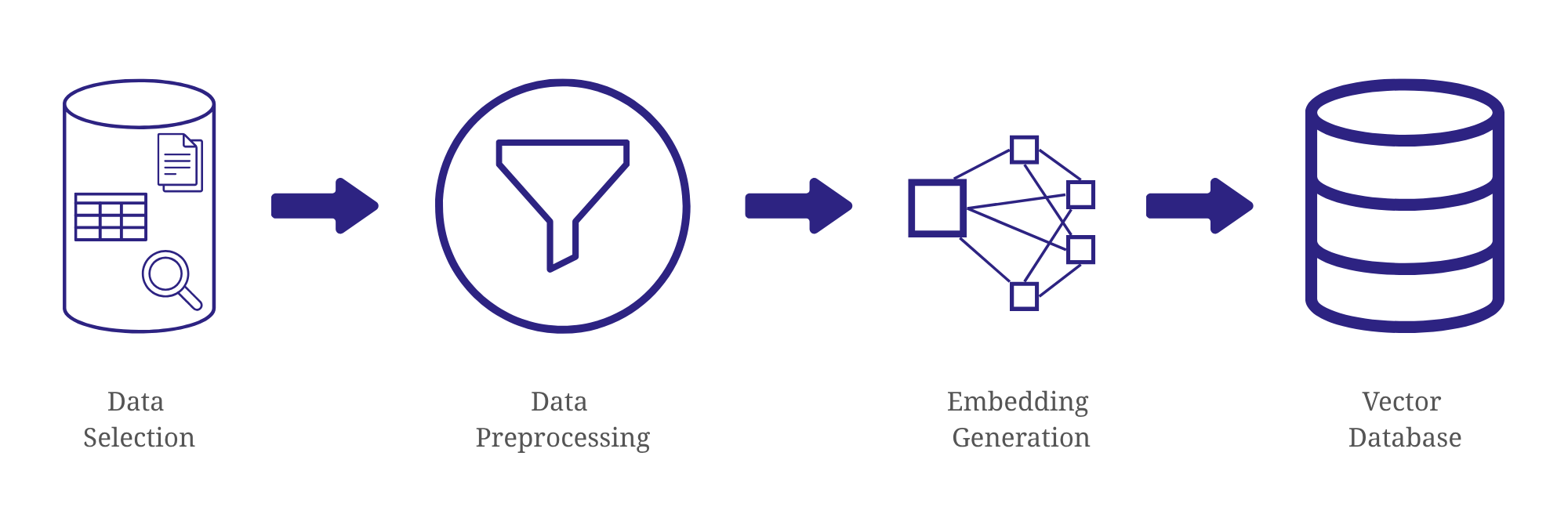
Data Selection: The preparation begins by selecting the appropriate data for the chatbot’s knowledge base. This typically involves choosing organized sources like databases, which contain the structured information necessary for the chatbot to function effectively.
Data Preprocessing: To prepare the raw data for optimal use in a RAG system, preprocessing is essential. This stage serves three primary purposes: enabling efficient retrieval, ensuring compatibility with the generative AI model, and optimizing for effective embedding generation. Efficient retrieval hinges on assigning unique identifiers, such as IDs, to each data element. This allows the system to quickly locate and access specific pieces of information. To enhance both the generative AI model’s understanding and the quality of embeddings, techniques such as flattening tables, tokenization, text cleaning, stemming, lemmatization, stop word removal, and data type conversion can be employed. These techniques refine the data’s structure and content, making it easier for the generative AI model to process and understand, while also optimizing the data for capturing semantic meaning and relationships in the embeddings.
Embedding Generation: With the data now preprocessed and refined, it’s ready to be transformed into a format suitable for efficient retrieval. This is where embedding generation comes in. This step involves converting the preprocessed data into numerical vectors known as embeddings using a specifically trained embedding model. The embeddings capture the semantic meaning of the data, encoding relationships between words, concepts, and ideas, which enables efficient retrieval of relevant information. The specific embedding model used will depend on the nature of the data and the requirements of the RAG system.
In natural language processing, an embedding is a numerical representation of a word, phrase, or document that captures its meaning. These numerical vectors, which can range from a few hundred to many thousand dimensions, are designed so that words or documents with similar meanings have embeddings that are close together in the vector space.
For example, in an embedding space, the word “cat” would be located much closer to the word “lion” (another feline) than to the word “car” (an unrelated object). Meaning that even if two words were nearly identical in spelling but had vastly different meanings, their embeddings would be distant. This spatial arrangement reflects the semantic relationship between the words.
This allows AI systems to understand relationships between words and concepts, enabling them to perform tasks such as identifying similar documents. Embeddings are a fundamental building block for many AI applications, including RAG.
Saving the Embeddings in a Vector Database: The final step in the preparation phase is to store the generated embeddings in a specialized database designed for handling vector data. This is crucial because traditional databases aren’t optimized for storing or searching high-dimensional vectors. Saving the embeddings in a vector database ensures that the RAG system can quickly pinpoint the most relevant information in the knowledge base when responding to user queries.
Now looking at Data Vault’s architecture, we see that to some extent it is quite similar to what Databricks proposes: a multi-layer solution composed of a Staging layer, a Raw Data Vault and a Business Vault, followed by the domain-specific information marts. In the image below, we can see an example of a Data Vault architecture.
Retrieval Phase
With the knowledge base now prepared and ready for efficient retrieval, let’s explore how the RAG system interacts with users and generates responses in real-time.
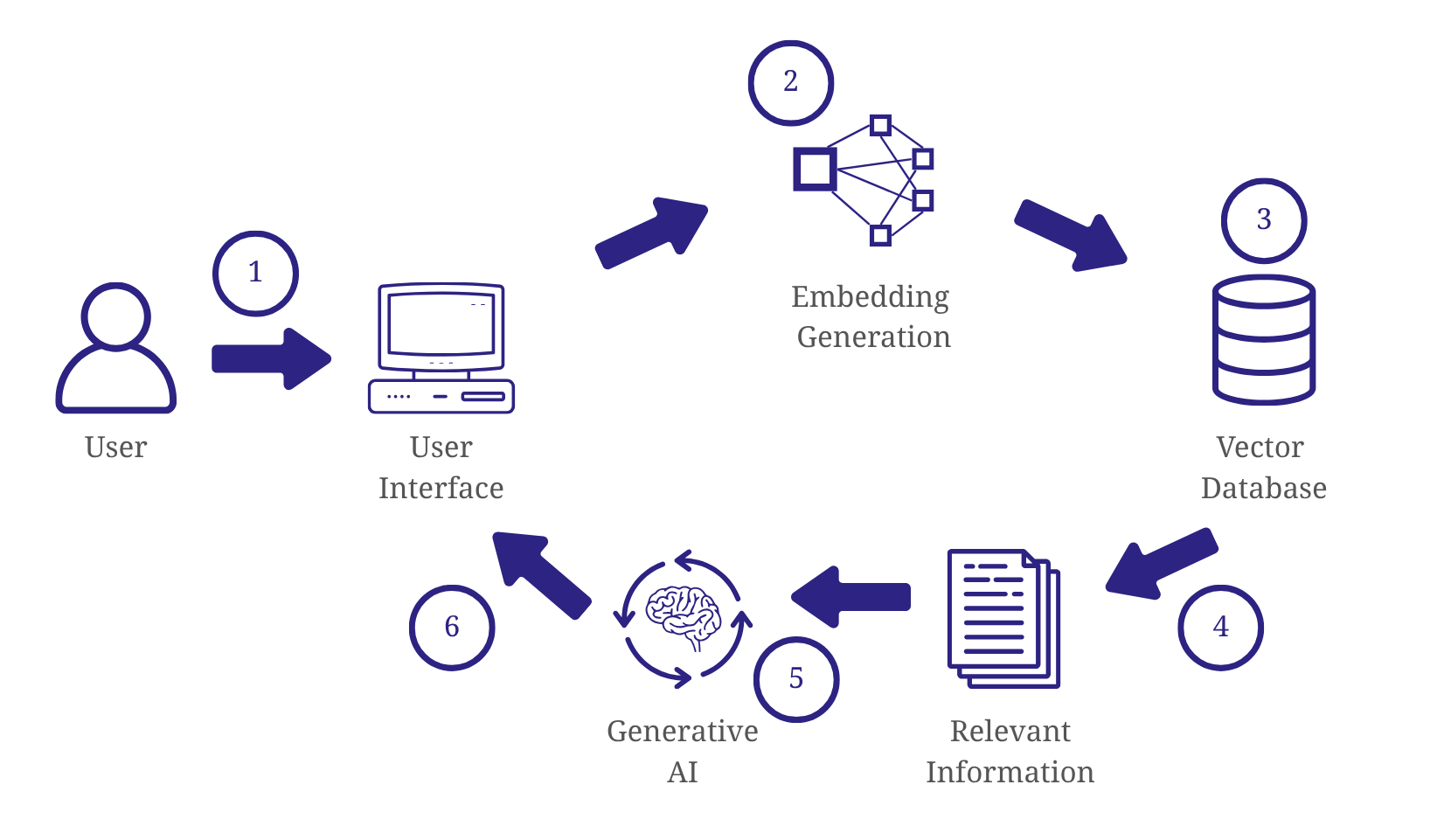
- User Interaction: The process begins with a user interacting with the chatbot through a user interface. This interaction could be a chat window, or any other platform that allows users to input queries.
- Embedding Generation: The user query is then converted into an embedding using the same embedding model that was used to process the knowledge base during the preparation phase. Consistency is vital because different embedding models might produce different numerical representations, hindering the similarity search process.
- Similarity Search and Retrieval: The query’s embedding is used to perform a similarity search within the same vector database that contains the knowledge base embeddings. This search identifies the most semantically similar embeddings, returning their corresponding IDs.
- Retrieve relevant Information: The IDs retrieved from the similarity search are then used to query the preprocessed data from the knowledge base. This lookup retrieves the corresponding documents in their preprocessed text form, providing the generative AI model with the necessary context for generating a response.
- Generative AI: The retrieved information, along with the original user query, is passed to a generative AI model. This model uses its knowledge to generate a relevant response to the user’s query. The generative process allows RAG systems to provide answers that are more than just basic information retrieval.
- Delivering the Response: Finally, the generated response is delivered back to the user through the user interface. The response could be in the form of text displayed in a chat window or a spoken response from a voice assistant.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsImplementing a RAG-Based Chatbot: A Practical Example
Now that we’ve explored the underlying architecture of RAG, let’s see how you can implement a RAG-based chatbot using services from the Google Cloud Platform. This example focuses on building an internal knowledge chatbot that can answer employee questions based on internal documents from a knowledge platform.
Data Preparation
The foundation of any effective RAG system is well-prepared data. This initial phase focuses on transforming your raw knowledge into a searchable format, ensuring documents are ready for efficient retrieval.

- Data Selection and Preprocessing: First, you’ll need to gather the relevant internal documents, preprocess them and save the data in a data platform like Google Cloud Storage.
- Embedding Generation: Once the preprocessed data is securely stored, Google Cloud Vertex AI is utilized to transform this data. Vertex AI extracts the textual content and converts it into high-dimensional vector embeddings, creating numerical representations that capture the semantic meaning of your documents. You can choose from various pre-trained embedding models or fine-tune your own model based on your specific needs.
- Vector Database: With the embeddings successfully generated, Google Cloud Vertex AI Vector Search then serves as the vector database. It efficiently stores these high-dimensional embeddings and is designed to enable rapid and accurate similarity searches during the retrieval phase.
Retrieval Architecture
This section outlines the Retrieval-Augmented Generation architecture of our Google Chat chatbot. It describes the flow of a user’s query through various Google Cloud Platform services, from initial submission to the delivery of a generated response, creating a robust and intelligent conversational experience.
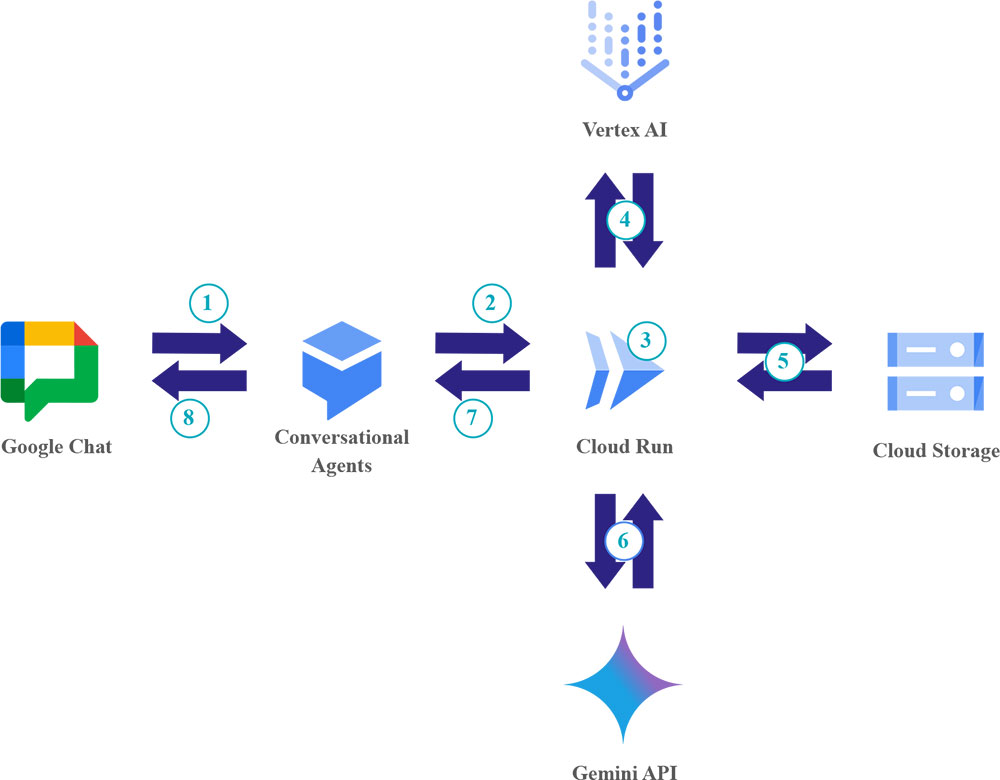
- User Interaction: The user begins by asking a question within Google Chat. Google Chat serves as the user interface, directing the query to the Conversational Agents platform.
- Request Orchestration: Conversational Agents receives the user’s input. It then triggers a webhook call, sending the user’s query to our RAG orchestrator service, which is hosted on Google Cloud Run.
- User Query Embedding: From this point, the Google Cloud Run service takes over as the central orchestrator of the RAG pipeline. It starts by processing the user’s query, generating a high-dimensional vector embedding of it using the same embedding model that was utilized during the data preparation.
- Information Discovery: The generated user query embedding is then transmitted from Cloud Run to Vertex AI Vector Search. Vertex AI performs an efficient similarity search, identifying and returning the ID(s) of semantically similar documents from the knowledge base based on the provided embedding.
- Relevant Information Retrieval: With the identified document ID(s) obtained from Vertex AI Vector Search (these IDs precisely match our preprocessed documents that are most relevant to the user’s query), the Cloud Run service accesses Google Cloud Storage. From Cloud Storage, the full text content of these matched knowledge base pages is fetched. These documents provide the essential context required for accurate response generation.
- Generative AI Response: The Cloud Run service then combines the original user query with the retrieved document content into a carefully constructed prompt. This comprehensive prompt is sent to the Gemini API, leveraging Google’s large language model to generate a natural language answer.
- Response Delivery: The generated answer from the Gemini API is received by the Cloud Run service. The Cloud Run service formats this response and sends it back to Conversational Agents.
- Final User Delivery: Conversational Agents receives the generated answer and seamlessly relays it back to the user within Google Chat, completing the interaction.
This example demonstrates how you can leverage GCP services to implement a RAG-based chatbot for internal knowledge sharing. By combining data preparation, embedding generation, similarity search, and generative AI, you can create a powerful tool that empowers employees with quick and easy access to relevant information.
– Tim Voßmerbäumer (Scalefree)
