From BI to AI: Operationalizing Predictive Analytics where your Data already lives
Traditional Business Intelligence and reporting are incredibly good at telling what happened yesterday. How much revenue was generated last quarter? How many users logged in this week? But while understanding the past is important, today’s businesses need to know what will happen tomorrow.
This is where Predictive Analytics comes in. At its core, predictive analytics simply uses historical data to forecast future outcomes. Instead of asking how many customers canceled last month, predictive analytics asks:
“Which specific customers are most likely to cancel next week?”
Many organizations understand this value and eagerly hire data scientists to build these models. Yet, time and time again, these predictive initiatives fail to make it out of the PoC phase and into daily business operations because of how teams and data architectures are fundamentally structured.
Predictive Analytics on the Modern Data Platform
Learn how to bridge the gap between your data platform and actionable AI by building predictive models directly where your business data lives. This webinar covers practical strategies for transforming warehouse data into features, deploying models, and automating the flow of insights back into your daily operational workflows. Learn more in our upcoming webinar on March 17th, 2026!
In this article:
The Problem: The “Two Silos” of Data
In many companies, Data Engineering and Data Science exist in two entirely different worlds.
Data Engineers and Data Warehouse Developers spend their days building the Modern Data Platform. They carefully extract, clean, conform, and govern data from dozens of sources to create a “Single Source of Truth.” When a business analyst looks at a revenue dashboard, they know they can trust the numbers because the data platform enforces strict business logic.
Data Scientists, on the other hand, often work in isolated environments like standalone Jupyter notebooks. Because they need massive amounts of data to train their machine learning models, they often bypass the data platform entirely, pulling raw, unstructured data directly from a data lake.
This disconnect creates some challenges:
- Duplicated Effort: Data Scientists waste up to 80% of their time cleaning and prepping raw data, work the Data Engineering team has already done in the platform
- Inconsistent Metrics: Because models are built on raw data, a model’s definition of “Active Customer” might completely contradict the official definition used by the in the data platform
- The “Wall of Production”: A model might look perfectly accurate on a data scientist’s laptop, but because it relies on disconnected, ungoverned data pipelines, integrating its predictions back into the daily workflows of sales or support teams becomes an IT nightmare
- Exclusivity: Data analysts are often limited to classic descriptive analytics which slows time-to-insight. The optimal solution is to democratize data science, empowering analysts to implement predictive use cases directly.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsThe Solution: Bring the Machine Learning to the Data
The fix to this problem requires a fundamental shift in how we think about machine learning architecture. Instead of moving data out of governed systems to feed external ML models, we need to bring the ML workflows more closer to the data.
By positioning the Modern Data Platform as the foundation for predictive analytics, you ensure that every prediction is built on the same trusted, cleansed, and governed business data used for your daily reporting. The Data Platform becomes the Feature Store, a centralized hub where data is prepared once and used everywhere, whether for a BI dashboard or training a predictive model.
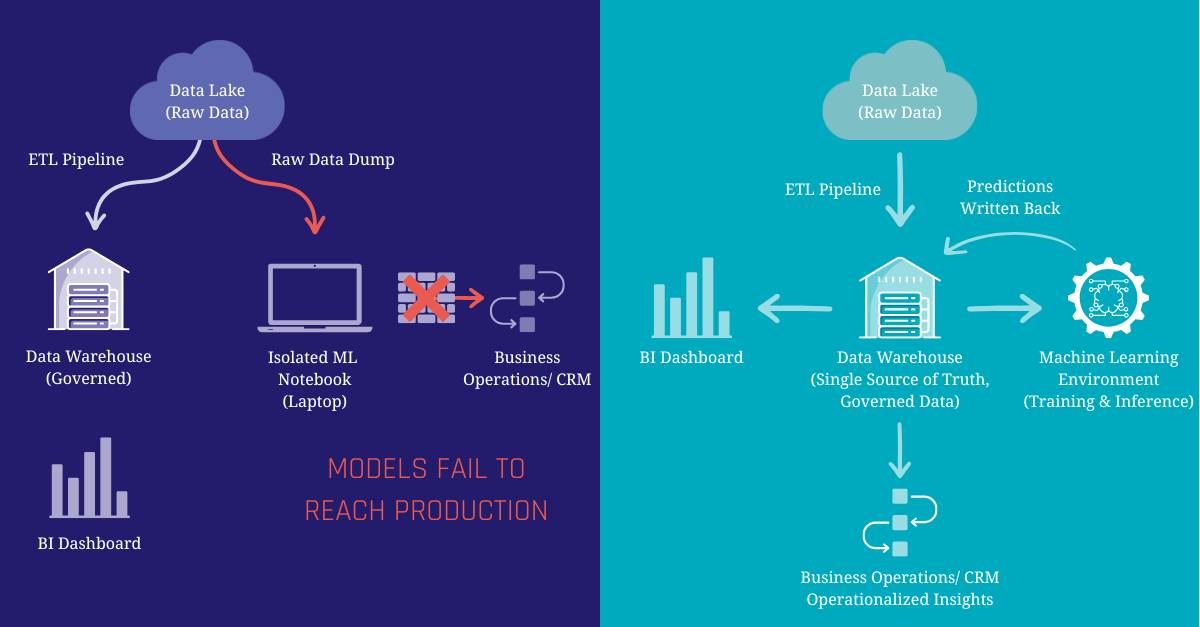
When the data platform serves as the single source of truth for both analysts and algorithms, magic happens. Data science teams stop wrestling with raw data pipelines, data engineering teams maintain governance, and the business gets predictions they can actually trust and operationalize.
Two Architecture Approaches
So, how do we actually bring the machine learning to the data? There isn’t a one-size-fits-all answer. Depending on the team’s skillset and the complexity of the models, there are typically one of two foundational patterns adopted:
Pattern 1: In-Warehouse Machine Learning (Democratizing ML)
Modern cloud data platforms have evolved beyond just storing and querying data, many now have machine learning engines built directly into them.
- How it works: Using standard SQL, Data Analysts and Analytics Engineers can train, evaluate, and deploy models entirely inside the data platform (for example BigQuery ML, Snowflake Cortex or Databricks)
- The Benefit: This radically democratizes predictive analytics. You don’t need to know Python or manage complex infrastructure to build a model. If you know SQL, you can generate predictions using the exact same tables you use for your BI dashboards
- The Trade-off: While perfect for standard tasks like regression or classification, you are limited to the specific algorithms supported by the data platform
Pattern 2: The Data Platform as a Feature Store (The Hybrid Approach)
For organizations with dedicated Data Science teams building highly complex or custom models, the data platform takes on a different role: the Feature Store.
- How it works: Data Scientists continue to work in their preferred external ML platforms (like Vertex AI, Databricks, or other). However, instead of pulling messy data from a data lake, they connect directly to the data platform to pull curated, business-approved data (“features”) for training
- The Benefit: Data Scientists retain maximum flexibility to use advanced Python libraries and deep learning frameworks, while ensuring the models are trained on governed, accurate data
- The Trade-off: It requires a bit more orchestration to manage the pipeline between the data platform and the ML platform, and ensuring predictions are accurately written back to the data platform

Example: Predicting Customer Churn
To understand the benefits of these approaches, let’s look at a classic business challenge: Customer Churn Prevention.
Imagine a SaaS company trying to figure out which customers are likely to cancel their subscriptions. In a siloed environment, predicting this is can be a messy, manual science project. But on a modern data platform, it becomes an automated operational workflow:
- The Foundation (Data): Because of the Data Engineering team’s work, the data platform already contains all necessary historical information of the customer. CRM data (company size), financial records (billing history), product logs (login frequency), and Zendesk tickets (recent complaints) are all cleaned, joined, and sitting in governed tables including a full history of changes
- The Prediction (Modeling): An analyst uses In-Warehouse ML (Pattern 1) to run a classification model against this historical data. The model identifies the hidden patterns of a churning customer and generates a “Churn Risk Score” between 0 and 100 for every active user
- The Operationalization (Action): This is the crucial step. The predictions aren’t left in a notebook. The risk scores are written directly back into a new table in the data platform. Through reverse-ETL, these scores can be automatically synced to the CRM as well as dashboards and reports can easily be built on top of the results.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsConclusion
Predictive analytics shouldn’t be an isolated science experiment. It should be a living, breathing part of your operational reality. By treating your modern data platform as the foundation for your machine learning workflows, you eliminate data silos, empower your analysts, and ensure your predictions are built on the trusted business data that matters most.
It is time to operationalize predictive insights where your business data already lives.
Want to see how this works in practice?
Join our upcoming webinar: Predictive Analytics on the Modern Data Platform. We will explore how to build and run predictive analytics directly on top of your data platform using trusted, governed business data as the foundation. You’ll learn practical patterns for turning warehouse models into features, training and deploying predictions, and integrating results back into reporting and operational workflows. Join me on March 17th.
– Ole Bause (Scalefree)