“Stop writing complex SQL, start talking to your data?”
This provocative question highlights a growing shift in how we interact with data. For years, getting answers from a Data Warehouse meant writing SQL queries or relying on pre-built dashboards.
For many organizations, their data platforms remain underutilized because accessing insights still requires writing code or navigating complex dashboards. It’s time to go beyond static reports and unlock a true intelligence layer on top of your data warehouse. Recent advances in Large Language Models (LLMs) and Natural Language Processing (NLP) are making data warehouses smarter, faster, and easier to use for everyone. In this article, we’ll explore how LLMs can transform the way you interact with your data – from using plain English queries instead of SQL, to AI-driven discovery of hidden insights, to enriching your data pipelines – and why this shift represents the future of data analytics.
Unlock the Intelligence Layer: LLMs in Data Warehousing and the Future of your Data
Unlock your data warehouse’s full potential! This webinar reveals how Large Language Models and Natural Language Processing are transforming data interaction, empowering everyone to effortlessly translate plain language into SQL, enable AI-driven data discovery, and deliver actionable insights to every stakeholder. Register for our free webinar, August 12th, 2025!
From Complex SQL to Conversational Queries
Business users often depend on data engineers or analysts to fetch answers, creating bottlenecks in decision-making. Even data professionals themselves spend considerable time writing and optimizing SQL, rather than interpreting results. What if anyone could simply ask the data warehouse a question in plain language and get the answer? This is the promise of LLMs as an “intelligence layer”, a layer that bridges complex datasets and human comprehension. Advanced LLMs can understand a user’s question or request and generate the appropriate SQL queries on the fly.
This technology (often called Text-to-SQL or Natural-Language-to-SQL or NL2SQL) has rapidly evolved and major technology players have already taken note. For example, Databricks introduced a Natural Language Query feature (LakehouseIQ) to let users ask questions of their Lakehouse, and Snowflake is also exploring LLM-driven query capabilities.
Imagine asking your data warehouse in plain English: “What were our top-selling products last quarter by region?”. This text input is passed into a LLM, often enriched by company-specific data via RAG and then the system translates that into a correct, optimized SQL query that retrieves the answer.
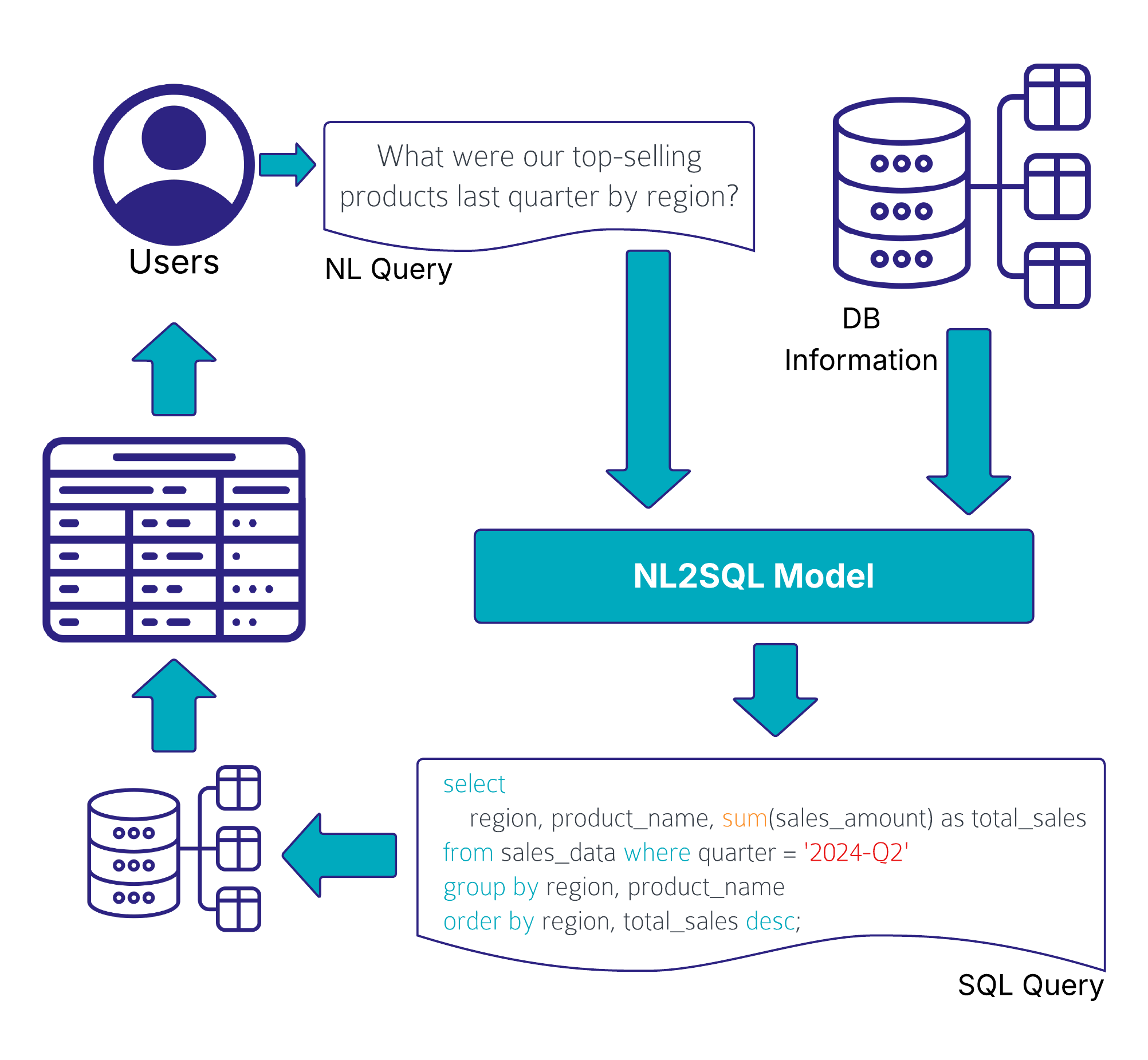
Of course, translating natural language to SQL at an enterprise scale isn’t trivial. Complex schemas, ambiguous user input, and security considerations mean the LLM has to be both smart and careful. Uber has built such an AI system that works on an enterprise scale level.
Uber’s QueryGPT is an NL2SQL system that uses a multi-step, RAG-based pipeline combining LLMs with retrieval and agent modules. It fetches context via similarity search over a vector database of example queries and schema information for SQL generation. To manage Uber’s vast data ecosystem, QueryGPT employs specialized agents:
- an Intent Agent classifies requests by business domain
- a Table Agent suggests tables for the query
- a Column Prune Agent trims irrelevant columns to reduce prompt length. The LLM then produces the SQL query and an explanation.
This layered design allows QueryGPT to handle large schemas and reliably generate complex multi-table queries. It’s a hybrid architecture where multiple transformer calls specialize in sub-tasks, enabling scalable, accurate NL2SQL as a production service, saving thousands of Uber employees significant time by mid-2024.
AI-Augmented Data Discovery and Insights
Beyond simply fetching results for user queries, LLMs can augment data discovery by revealing insights that users might not have explicitly asked for. Traditional dashboards show you what is happening, but a smart LLM-based system can tell you why it’s happening and highlight patterns you might not notice. This is often called augmented analytics – using AI to automatically find important correlations, trends, outliers, and drivers in your data.
LLMs excel at interpreting data outputs and providing additional context. For example, rather than just displaying a chart or a table, an LLM can generate a written summary pointing out key trends or anomalies. They can explain which metrics are up or down and suggest potential reasons (for instance, detecting that “conversion rates dipped in July, possibly due to seasonality or inventory issues”), enabling quicker and more informed decision-making.
Another area where LLMs can significantly reduce manual effort is in the creation and maintenance of data catalogs. Documenting data models, table structures, and especially individual column descriptions is often time-consuming and easily skipped due to missing resources, despite being crucial for an effective use and accessibility of the data. LLMs can automate large parts of this process by generating descriptions based on data profiling, SQL logic, naming conventions, and metadata.
dbt Cloud has recently released their dbt Copilot AI Agent that supports the developer in various ways, for example by letting the AI analyzing the SQL code and schema metadata to automatically generate model and column descriptions.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsLLMs in Your Data Pipeline: Enrichment and Efficiency
LLMs don’t just enhance how users interact with the Data Warehouse; they can also improve the data itself and the efficiency of data engineering processes. In modern ELT (Extract-Load-Transform) pipelines, a lot of time is spent cleaning, enriching, and preparing data for analysis. Here, LLMs offer new tools to automate and augment these steps.
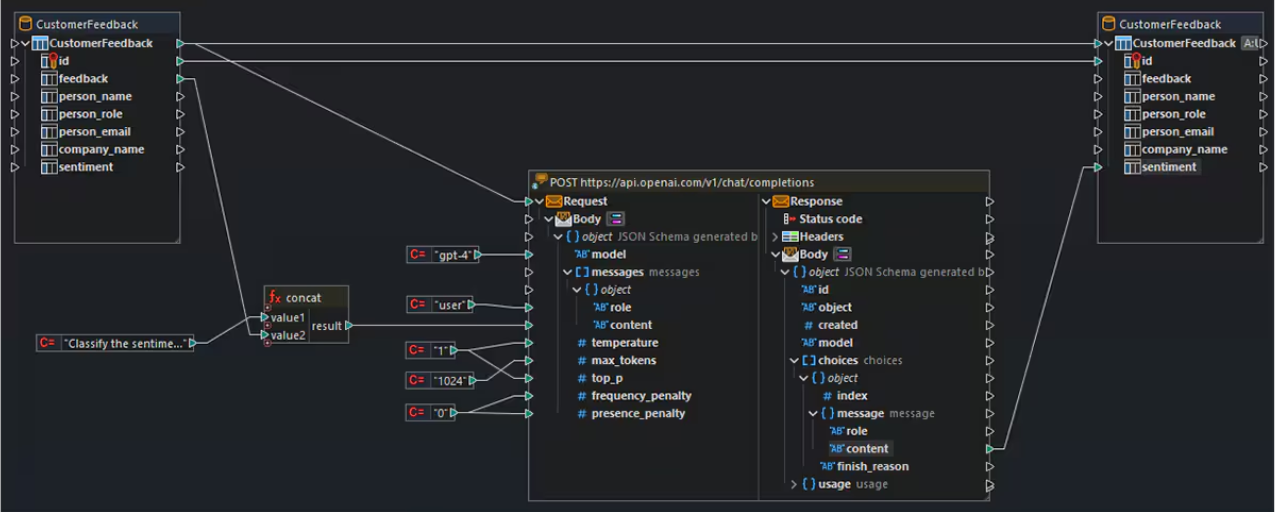
One promising use case is the semantic enrichment of data. Large Language Models have absorbed a vast amount of world knowledge and language patterns, and they can use that to fill gaps or add context to your raw data. For example, imagine you have a dataset of customer feedback where each entry is a text comment. An LLM could automatically classify the sentiment of each comment (positive/negative), extract key themes, or even generate a summary of common issues. In this way, unstructured data becomes structured insights without manual effort. The image below illustrates how an LLM is integrated into a data pipeline: text inputs from a CustomerFeedback table are passed to an OpenAI API endpoint, where the model returns structured sentiment labels that are then stored back in the database.
In a practical case study, LLMs were used to enrich an academic dataset by inferring missing attributes (like guessing a person’s gender from their name with high accuracy), which outperformed dedicated API services. This showcases how LLMs can bring external knowledge and reasoning to enhance your data.
Another area is metadata enrichment and semantic enrichment of unstructured data. Enterprise data is often filled with cryptic column names and jargon that prevents usability. LLMs can intelligently expand abbreviations and annotate fields with business-friendly descriptions. For instance, an LLM-driven catalog might take a column labeled “CUST_ID” and annotate it as “Customer Identifier, unique ID for each customer record”.
LLMs can also assist in the coding and transformation process itself. Data engineers can leverage LLMs to generate boilerplate code or SQL for transformations, document pipeline logic in plain English, or even detect anomalies and data quality issues through pattern analysis. By automating tedious parts of data preparation and providing AI-generated suggestions, LLMs free up engineers to focus on higher-level architecture and problem-solving.
Conclusion
While the promise of an LLM-powered intelligence layer is exciting, it’s important to approach it with a clear strategy. Successful implementation requires considering a few key challenges and best practices. Data quality and governance are more crucial than ever. If your underlying data is inaccurate or poorly structured, the AI’s answers will be unreliable. As the saying goes, “garbage in, garbage out.”
Ensuring clean, well-organized data (and maintaining a robust data governance program) will help the LLM produce meaningful and correct insights. Additionally, organizations may need to fine-tune or configure their LLMs to understand industry-specific terminology or business context. This reduces the chance of the AI misinterpreting what a user asks or generating an incorrect query.
Privacy and security are another important consideration. If your data includes sensitive information, you must ensure that any AI tool accessing it complies with your security requirements. This might involve using self-hosted models or secure APIs, and setting up proper access controls.
The dream of a self-service analytics experience: “just talk to the data and get answers” is quickly becoming a reality. This evolution may redefine roles (enabling analysts and engineers alike to focus on higher-value tasks) and open up analytics to a wider audience than ever before. It’s an exciting time to be a data professional, but also one that demands staying informed and ready to adapt.
– Ole Bause (Scalefree)
