In this article, we will try to explore the practical considerations of implementing Data Vault on Databricks, by analyzing Databricks’ ecosystem and its alignment with Data Vault’s core principles. We will go over the fundamentals of Databricks’ architecture, its compatibility with Data Vault’s layered approach, and how some of Databricks’ features can be leveraged to simplify, optimize, or even replace certain traditional aspects of a Data Vault implementation.
This article aims to provide a strategic perspective on how Databricks can support Data Vault principles such as historization, scalability, auditability, and modular design. We’ll discuss opportunities, such as using Delta Lake for time travel and schema evolution, and challenges, like the performance trade-offs introduced by Data Vault’s high number of joins.
Bridging EDW and Lakehouse: Implementing Data Vault on Databricks
Join us in this webinar as we explore the process of implementing Data Vault on Databricks. We will go over different integration strategies and potential challenges, as well as technical aspects like data modeling, performance considerations, and data governance. Register for our free webinar, June 17th, 2025!
Understanding Data Vault 2.0
Data Vault is traditionally defined as a methodology encompassing implementation practices, an architectural framework, and a data modeling approach for building a business intelligence system. However, this article focuses on the architectural and modeling aspects of Data Vault, as these are most relevant topics for the implementation of Data Vault on Databricks.
The main advantage of adopting Data Vault’s architecture and modeling are:
- Preservation of Historical Integrity and Auditability.
- Insert-only historization
- Reconstruction of data source deliveries
- Simplified Governance and Compliance
- Flexible and Scalable Architecture Data Model
- Modular Data Model (Hub & Spoke)
- Scalable
- Decoupling of Hard and Soft Business rules
- Tool Agnosticism
The Databricks Ecosystem
Databricks is a leading platform for data analytics, offering a unified environment for data processing, machine learning, and collaborative data science. Its lakehouse architecture, built on Apache Spark and Delta Lake, combines the flexibility of data lakes with the structure and performance of data warehouses. This approach allows organizations to store all types of data while enabling efficient SQL-based analytics and AI/ML workloads.
For Data Vault implementation, Databricks can be a practical choice. Delta Lake’s ACID compliance and transaction logs ensure data integrity and enable Time Travel for historical analysis. As we will see next, features like Delta Live Tables and Unity Catalog optimize data ingestion, transformation, and governance, making Databricks a compelling platform for implementing Data Vault.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsDatabricks and Data Vault: Do they work together?
To assess the combination of Databricks and Data Vault, we need to analyze their common ground: architecture and data modeling. Both are designed to handle large scales of volume and data processing, and a successful integration of both relies on understanding how they can complement each other.
Architectural Compatibility
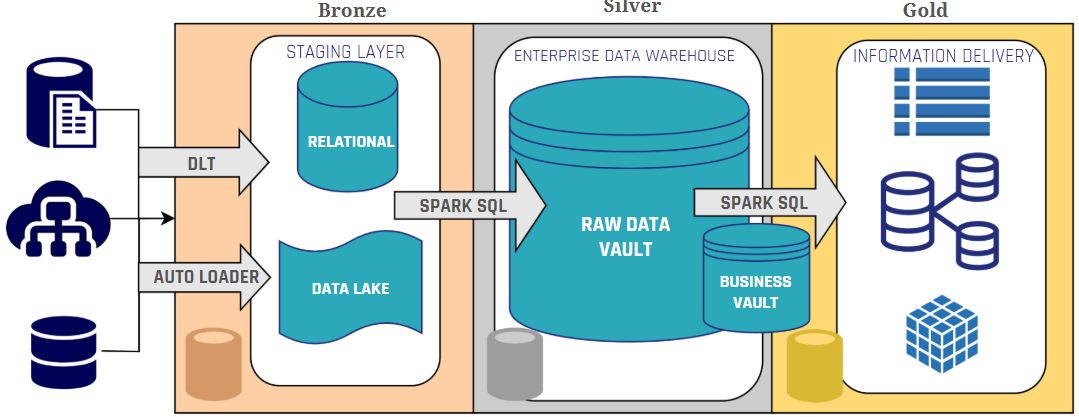
Databricks, built on Apache Spark and Delta Lake, follows the Medallion Architecture, a layered approach designed to structure and refine data. Their Medallion Architecture provides a best practice for managing data within a lakehouse environment, utilizing a three-layered approach (Bronze, Silver, Gold) to progressively structure and refine data. This approach aligns well with Data Vault’s multi-layered architecture (Staging, Raw Data Vault, Business Vault, Information Marts).
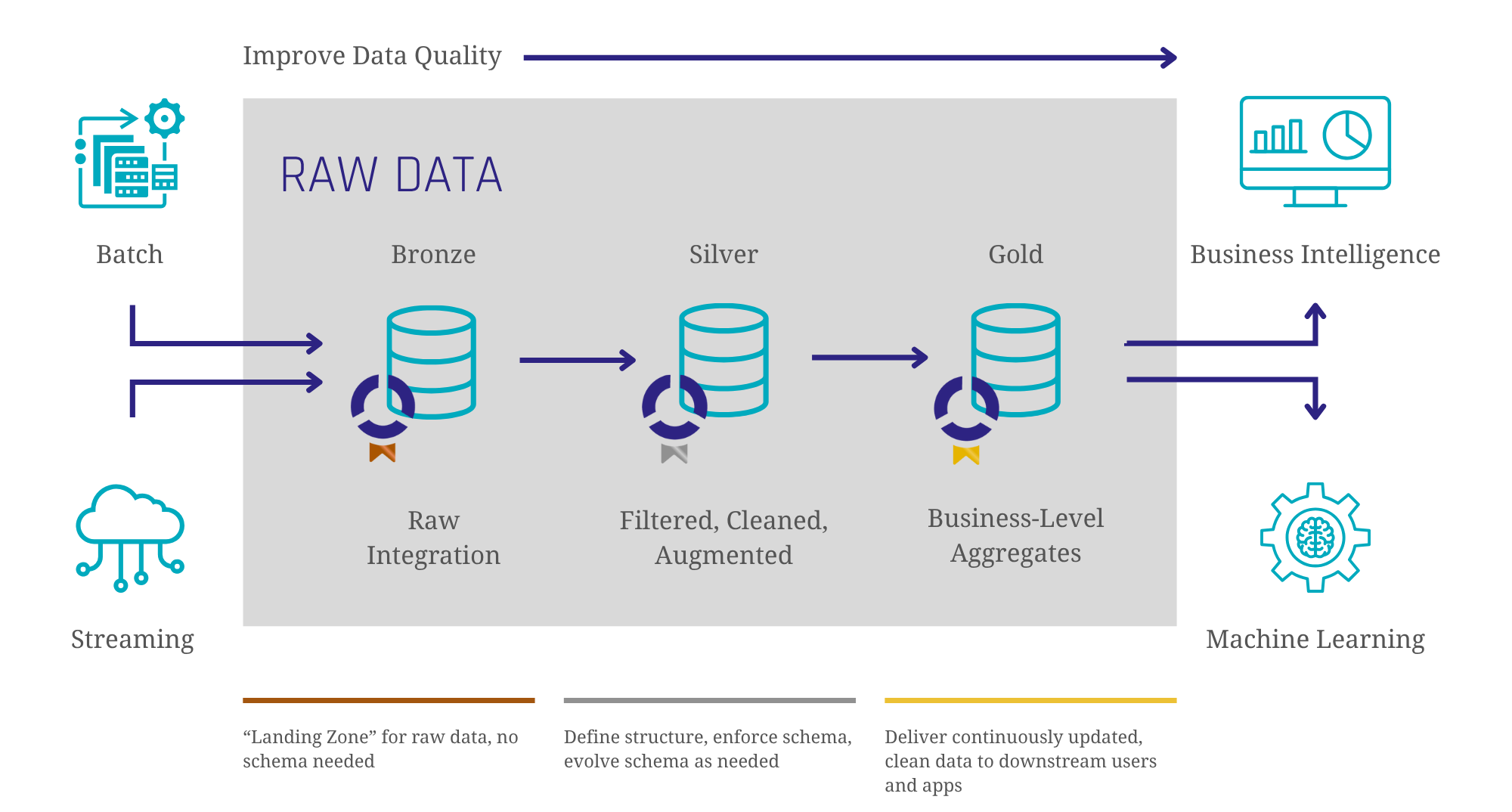
Image 1: Databricks’ Medallion architecture
Now looking at Data Vault’s architecture, we see that to some extent it is quite similar to what Databricks proposes: a multi-layer solution composed of a Staging layer, a Raw Data Vault and a Business Vault, followed by the domain-specific information marts. In the image below, we can see an example of a Data Vault architecture.

Image 2: Data Vault Architecture
Integrating Data Vault with the Medallion Architecture allows for a synergistic approach, as we can see in image 3.
Image 3: Data Vault and Medallion Architecture
The Bronze layer serves the same purpose as Data Vault’s Staging Area, where raw data is ingested from the different sources and stored in a single place. From then on, the Silver layer will store the Raw Data Vault, source tables will be split into hubs, links, and satellites. Here we can already consider some Databricks’ features, such as schema enforcement for integrity; and also Delta Live Tables and Spark SQL to maintain steady loading processes and automate quality checks. The Business Vault, which derives additional business-relevant data structures, sits between Silver and Gold layers, assisting with the information delivery process.
In the Business Vault, Databricks features such as Z-Ordering and data skipping can optimize performance by organizing data more efficiently. Additionally, Spark SQL can be used for aggregations and transformations supported in PIT and Bridge tables. Finally, in the Gold layer, we can start creating our Information Marts with Flat & Wide structures that improve the performance when querying the information out of the Vault.
Privacy and Security
Databricks’ data governance features included in Unity Catalog can optimize Data Vault implementations by simplifying security and privacy controls. Unity Catalog’s fine-grained access control and data masking capabilities can eliminate the need for satellite splits traditionally used to manage sensitive data. Additionally, the lakehouse architecture enables direct data querying, which facilitates compliance with GDPR and data privacy regulations, particularly for responding to data subject access requests (DSAR) and right-to-be-forgotten requests. These data governance features help to simplify the Data Vault model and reduce the final amount of tables in the Vault.
Historization
While both Data Vault and Databricks offer mechanisms for data historization, relying solely on Delta Lake’s Time Travel for historization in a Data Vault implementation on Databricks might not be the best choice. In Databricks, the VACUUM command can permanently delete older data files, potentially removing historical data needed for auditing, lineage analysis and regulatory compliance. Hence, alternative historization methods should be considered, such as maintaining traditional historization with Data Vault’s modelling insert-only approach, or leveraging Databricks’ Change Data Feed to capture a stream of changes made to Delta Lake tables. This ensures a complete and auditable history, even if older data versions are removed by the VACUUM command.
Performance Considerations
When implementing Data Vault on Databricks, performance optimization requires architectural considerations that comprehend the characteristics of both systems. The modular design of Data Vault can create numerous tables with complex join patterns, which can be challenging in Databricks’ Spark environment, since Delta Lake’s column-based Parquet files can struggle with extensive joins. To address this challenge, practitioners should minimize satellite splits (leveraging Databricks’ native security and privacy features instead), implement virtualization in the Business Vault through views, and utilize Point-in-Time and Bridge tables to precompute historical snapshots that reduce join complexity and aid in achieving the target granularity.
For optimal performance, information marts should adopt Flat & Wide structures that prioritize query speed over storage efficiency (an acceptable trade-off given today’s relatively low storage costs). Additional performance gains can be achieved by strategically applying Delta Lake features like Z-Ordering and data skipping to enhance the information delivery process. The decision between views and fully materialized information marts is also an aspect to consider; while views reduce redundancy and simplify management, materialized marts with denormalized tables provide substantial performance benefits for complex reporting scenarios that would otherwise require resource-intensive joins across multiple Data Vault structures. A balanced approach combining views and materialized views should be based on query complexity, data volume, and update frequency, ensuring that reporting, and analytics workloads remain performant. This way we ensure that a Data Vault implementation on Databricks can maintain both the modeling flexibility of Data Vault and the performance capabilities of the Databricks platform.
Data Vault on Databricks: The Best of both Worlds
Implementing Data Vault on Databricks represents a practical and effective combination that merges Data Vault’s tool-agnostic architecture with Databricks’ technical capabilities. To optimize this integration, organizations should make thoughtful adjustments that create synergies between the modeling methodology and platform, including leveraging Unity Catalog for security and privacy satellite management, combining architectural designs while maintaining historization and data lineage, and virtualizing queries in the downstream layers with Flat & Wide structures with PIT and Bridge tables as underlying elements to enhance performance. This balanced approach allows organizations to improve governance and simplify data management, while preserving the core strengths of both systems.
– Ricardo Rodríguez (Scalefree)