
Implementing Data Vault 2.0 ghost records
During the development of Data Vault, from the first iteration to its latest Data Vault 2.0, we’ve mentioned the two terms “ghost records” and “zero keys” in our literature as well as in our Data Vault 2.0 Boot Camps. And since then, we’ve noticed these concepts oftentimes being referenced interchangeably.
In this blog entry, we’ll discuss the implementation of ghost records in Data Vault 2.0. Please note, that this article is part one of a multi-part blog series clarifying Ghost Records vs. Zero Keys.
Why implement ghost records?
The concept of ghost records is usually brought up together with the implementation of point-in-time (PIT) tables. PIT tables are used as query assistant objects as part of the Business Vault, in which snapshots of data are created for certain time intervals specified by the data consumers. It’s important to note that these intervals can be daily, weekly, even real-time, etc. Each entry in a PIT table materializes joins from a Data Vault spine object (either a Hub or a Link) to its surrounding Satellite structures to reduce joins while querying against the Data Vault and thus boosting query performance.
In some instances, however, upon joining e.g. a Hub to one of its Satellites, there can be no corresponding Satellite delta for certain snapshots. The reason behind this could be that the business key was not available or unknown by the data source at that given time.

Reference to a ghost record in a PIT table
To combat this issue, ghost records are added to Satellite entities to virtually fill up gaps in the beginning of the timeline, so that equal joins are made possible in ad-hoc queries against the Raw Vault. Equal joins (a.k.a. equi-joins) are joins that only use equality comparators and are arguably the most efficient/fastest SQL-join type.
What does a ghost record look like?
A ghost record can be understood as a dummy record that contains default values. In the previous iteration of Data Vault (DV1), the solution was to create a ghost record per key per satellite structure. This would still do the job of filling up gaps at the beginning of the timeline. However, this solution didn’t scale well on higher volumes of data. Imagine a hub that contains 10 million business keys and there are three satellites attached to it. Every satellite then contains 10 million ghost records, resulting in 30 million records across all three satellites. In addition, every time a business key is added to the hub, a corresponding ghost record needs to be added to each satellite. The sheer amount of ghost records in this case would defeat the whole purpose of trying to achieve equi-joins, to enable faster queries.
Thus, since the introduction of DV2.0, it is only required to insert one single ghost record per Satellite structure.
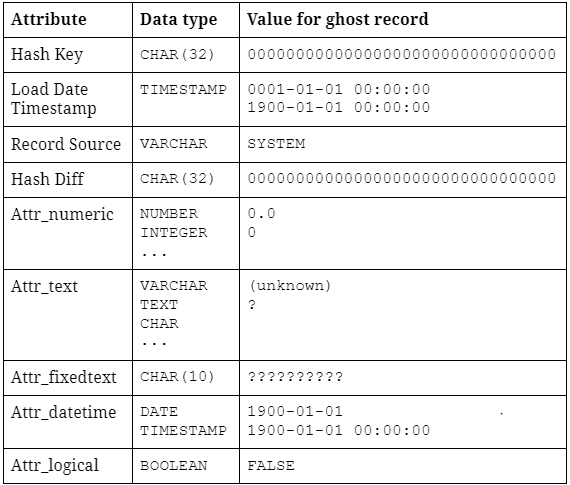
Example: Ghost record with attributes of different data types
The ghost record typically contains a constant hash key 00000000000000000000000000000000 (32 times the character “0”). This hash key is also known as a Zero key – more on Zero keys coming up in the next part of this blog series. Its load timestamp is usually set to the earliest possible timestamp within the DBMS, indicating the “beginning point of time”. The record source “SYSTEM” simply means the record is artificially generated.
Then, follows a list of default NULL values for every descriptive attribute within the Satellite structure. For each data type, we define a default value for the ghost record. For example, attributes with numeric data types can be filled with (numeric) zero, string attributes can be filled with either “(unknown)” or “?” depending on the length definition of the attribute.
It is recommended that the ghost record is filled with default values, as opposed to filling it with NULL/empty values, since these default values can be used and displayed further downstream. A good example of this can be seen in dimensions, an “(unknown)” string is arguably way more descriptive than a mere NULL value.
How to insert ghost records
There are a couple of ways to insert ghost records into Satellite structures.
The first variation is to insert the ghost records upon object creation as a one-time operation and then forget about it. Simple as that!
Another way is to insert the ghost record during the process of loading Satellites. The loading procedure should start with inserting a ghost record into the target object, if it does not yet exist. Then, the procedure can proceed with loading the Satellite with incoming data as normal. This variation might be viewed as rather excessive. However, it ensures that the ghost record is always available and that it gets inserted back into each Satellite – in case for whatever reason, objects are truncated or the ghost record itself is accidentally deleted, for example during development.
Both variations can be fully automated within your project’s Data Vault automation tool of choice.
Conclusion
We hope that this blog post helps to clarify the implementation of ghost records in a Data Vault 2.0 solution. Coming up next, we’d like to discuss with you “the-other-technical-term” Zero keys and the difference between Ghost records and them – which has been rather confusing to many fellow Data Vault practitioners.
Feel free to share this blog post with your colleagues and make sure to leave a comment on how your project implements ghost records!
-by Trung Ta (Scalefree)
Is it really recommended to set default values for the ghost record attributes?
Read somewhere on the forum where Dan advised against putting anything other than NULL, especially for numerical fields. https://datavaultalliance.com/discussions/postid/1813/
The reasoning made sense to me, that if you assign a default value based on the data type you can quickly run into issues downstream. E.g. if you put FALSE as the default for boolean, then the columns IS_ACTIVE or IS_INACTIVE will have VERY different meaning.
You could also consider if you had a employee satellite with a numerical salary column, then setting the default to 0 might affect downstream calculations.
I get that it’s easier to just set the default values in the satellite, rather than in the information mart, but it sounds to me like the default values can be based on a lot of assumptions.
Hello Jeppe,
Thank you for reaching out with the question! It is indeed recommended by Data Vault 2.0 to set default values for ghost record attributes. In the end, the ghost record will end up being only the default member in a dimension, of which the content doesn’t matter much. Moreover, when working with aggregations, you can identify, whether the parent of a hash key is an actual object or a ghost record, through the hash key – i.e. zero key in the case of ghost record (“0000…”).
Thank you kindly
Trung Ta
Hi, by using ghost records we avoid outer joins which i guess shall be more perfomant.
Just a remark, doesnt PIT only needs SATs load_dates ? I dont see reason to duplicate the HUB hask key 3 times in your example, HK_HUB should be sufficient right ?
Thanks,
Emanuel
Hello Emanuel,
Thank you for reaching out with the question! Since you can have either the parent hash key, or the zero key of the ghost record (“0000…”) coming from a Satellite, we recommend having multiple hash key columns in a PIT table structure. Not only does this simplify the management of PIT table structure, but also queries joining PIT table with descriptive information from Satellites – since you have the combination of parent hash key and load date timestamp for each satellite ready for the join.
Thank you kindly,
Trung Ta