Watch the Webinar

What are common mistakes when applying Data Vault 2.0 in enterprise data warehouse projects? Do you have questions regarding modeling in Data Vault and the realization of GDPR causes you great difficulties or is your project stuck because you are delivering no business value?
This webinar describes common Anti-patterns of Data Vault, their consequences, and the solution to eliminate them from your current or in your future projects.
Tune in and learn more to avoid bad practices and apply simple solutions.
Watch Webinar Recording
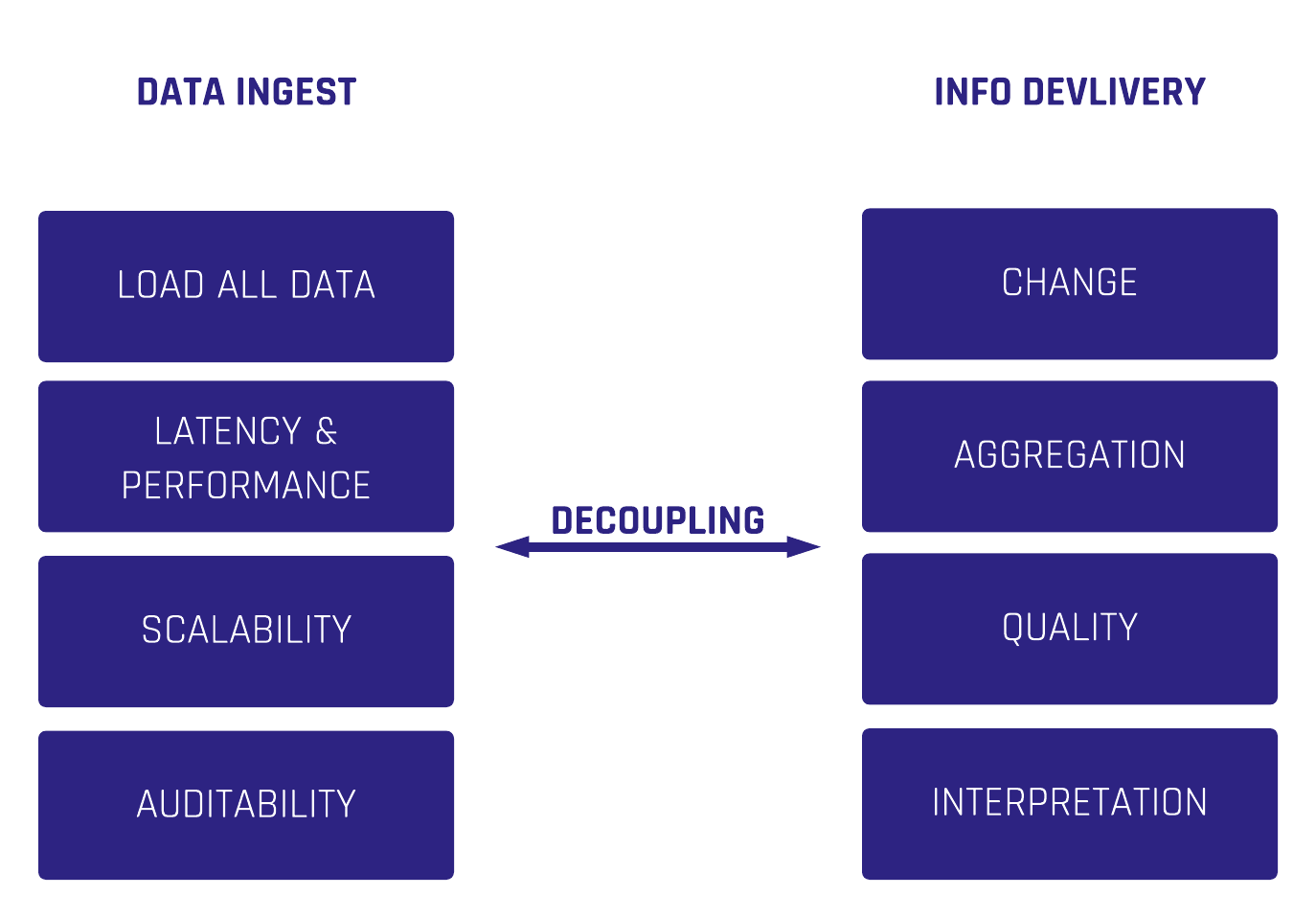
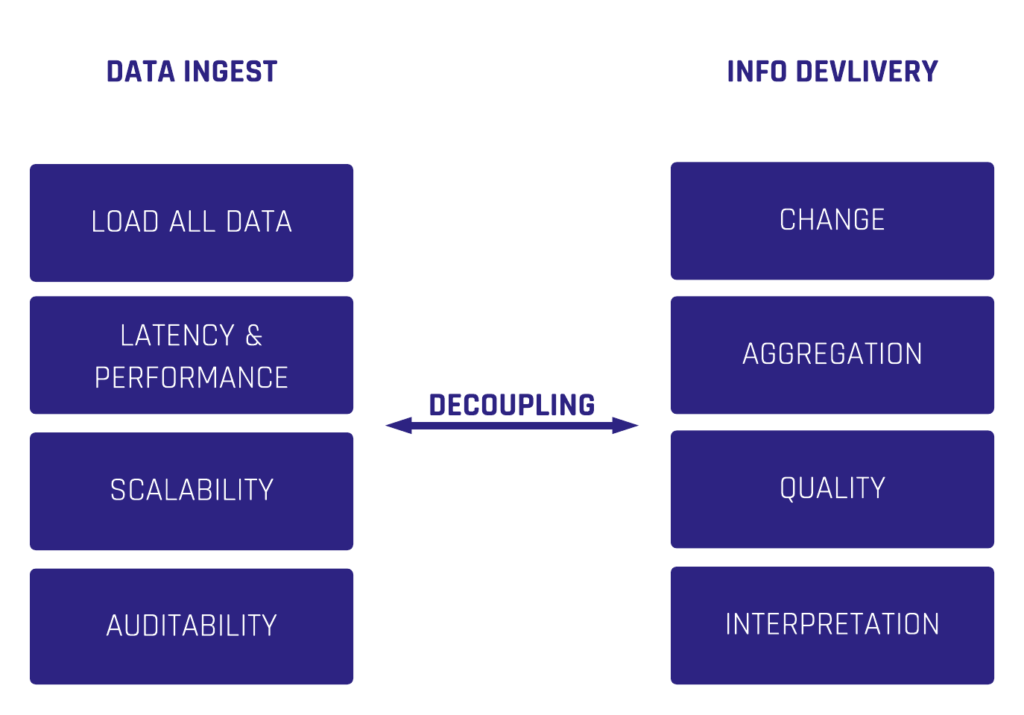
Webinar Agenda
1. How to use Data Vault for modeling business information
2. How to avoid the pitfalls of being unable to deliver business value
3. How to mask Business Keys from Hubs for privacy