
Point in Time Tables
Point in time tables are useful when querying data from the Raw Vault that has multiple satellites on a hub or a link:
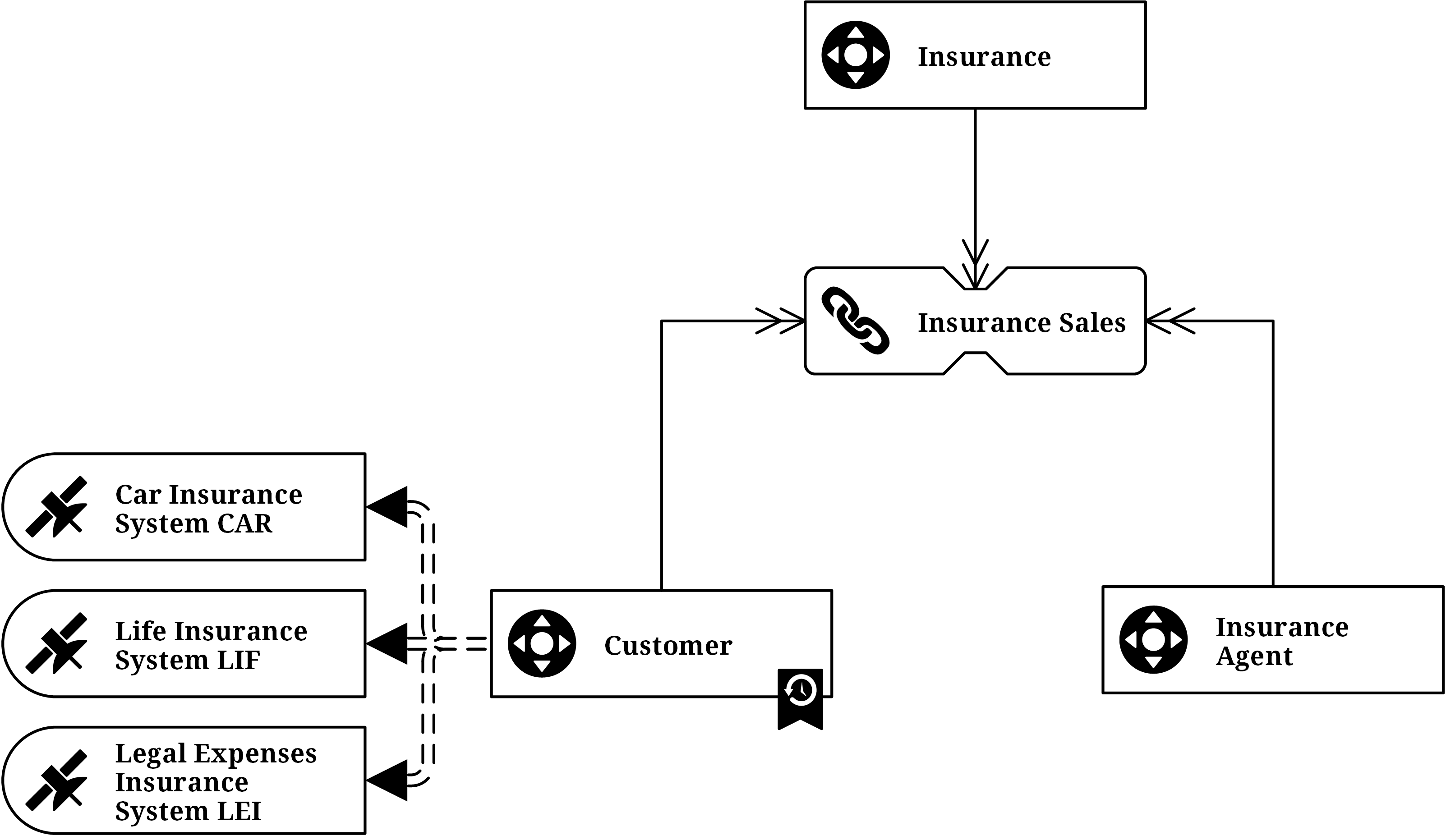
About Point In Time Tables Tables
In the above example, there are multiple satellites on the hub Customer and link included in the diagram. This is a very common situation for data warehouse solutions because they integrate data from multiple source systems. However, this situation increases the complexity when querying the data out of the Raw Data Vault. The problem arises because the changes to the business objects stored in the source systems don’t happen at the same time. Instead, a business object, such as a customer (an assured person), is updated in one of the many source systems at a given time, then updated in another system at another time, etc. Note that the Point-in-time table (PIT) is already attached to the hub, as indicated by the ribbon.
Changes came in at various times, not related to each other. Most updates would be added when insurance is concluded, but they did not affect all operational systems at the same time. As a consequence, the change did not affect all satellites. Instead, it affected only the satellite that was supposed to cover the change (which is an advantage).
When building a data mart from this raw data, querying the customer data on a given date becomes complicated: the query should return the customer data as it was active according to the data warehouse delta process on the selected date. It requires outer join queries with complex time range handling involved to achieve this goal. With more than three satellites on a hub or link, this becomes complicated and slow. The better approach is to use equal-join queries for retrieving the data from the Raw Data Vault. To achieve this, a special entity type is used in Data Vault 2.0 modeling: point in time tables (PIT). This entity is introduced to a Data Vault 2.0 model whenever the query performance is too low for a given hub or link and surrounding satellites.

Because the data in a PIT table is system-computed and does not originate from a source system, the data is not to be audited and not in the Raw Vault, so the structure can be modified to include computed columns.
Point in time tables serve two purposes:
Simplify the combination of multiple deltas at different “point in time”
A PIT table creates snapshots of data for dates specified by the data consumers upstream. For example, it is often usual to report the current state of data each day. To accommodate these requirements, the PIT table includes the date and time of the snapshot, in combination with the business key, as a unique key of the entity (a hashed key including these two attributes, named CustomerKey in Figure 2). For each of these combinations, the PIT table contains the load dates and the corresponding hash keys from each satellite that correspond best with the snapshot date.
Reduce the complexity of joins for performance reasons with point in time tables
The point in time table is like an index used by the query and provides information about the active satellite entries per snapshot date. The goal is to materialize as much of the join logic as possible and end up with an inner join with equi-join conditions only. This join type is the most performant version of joining on most (if not all) relational database servers. In order to maximize the performance of the PIT table while maintaining low storage requirements, only one ghost record is required in each satellite used by the point in time table. This ghost record is used when no record is active in the referenced satellite and serves as the unknown or NULL case. By using the ghost record, it is possible to avoid NULL checks in general, because the join condition will always point to an active record in the satellite table: either an actual record that is active at the given snapshot date or the ghost record.

The table above (Table 1) shows an assured person with frozen data states, one from the 8th, and one from the 9th of October 2018. On the 8th there was no record for this customer in the legal expenses insurance satellite. For that reason both the hash key and the load date timestamp are NULL. For better query performance, these NULL values are pointed to the ghost record in the related satellite table to avoid searching for a record which not exist.
When customer data must be deleted for one business only and PII information is used as Business Key, just the Link entry and the descriptive attributes in the specific Satellite have to be deleted. The activity history is still available, can be used for analytical reasons, and is not traceable to the customer itself. The additional advantage of this “business split” is when only one business is affected in case of deleting customer data, i.e. each business comes from different subsidiaries, and only the car insurance data must be deleted. Furthermore, keep in mind that deleting the Business Key only (and keeping the Hash Key) does not result in GDPR compliance (and does not meet the Data Vault 2.0 standard anyway as the Business Key is used in link tables). The Hash Key in Data Vault 2.0 is not used to encrypt data but for performance reasons. The key in the Links and the business-driven Hubs, as we are talking about, can not be calculated back as it is a complete surrogate key. As soon as the customer wants to be deleted completely as he/she is no longer a customer in any of your business, you delete the record from the main Hub as well.
Otherwise, if there is no additional artificial key for the customer, after deleting PII data, you can not tie your data back to an object (an anchor point), which makes them (in many cases) useless.
Conclusion
The purposes of point in time tables are to improve the query performance by eliminating outer joins and allowing inner joins with equi join conditions (best performance). Additionally, point in time tables enhance partitioning and enable full scalability of star schemas (which should be completely virtualized) on top of the Data Vault. Furthermore, end users don’t have to join through all satellite tables, but join just one table for one business object which reduces the query complexity for ad-hoc queries.
Hi @Michael,
Amazing and Important insight.
But as the systems are becoming more and more heterogeneous where DWH is on 1 environment and MART is on another, I think its time to grow the Data Vault objects too.
So PIT is essentially storing the Load Dates for each BK from all the SATs.
How about having a PIT_SAT where we have all the Attributes from SATs. This will be child table of PIT.
Advantage:
1. My Virtual Dimension (in Mart) is simply inner join from PIT and PIT_SAT.
2. If my DWH is HIVE (managed) and MART is on Teradata or Exasol or Oracle, then I only have to sync PIT and PIT_SAT (2 tables) and not all the DWH SATs.
Please let me know if this sounds good?
Angad
Hi Angad,
thanks for your comment.
Actually, as the PIT is not part of the Raw Data Vault, you can extend the table to your own advantages, what also means to either create an additional PIT (PIT_SAT) table where the descriptive attributes are part of, or hanging these attributes directly in the main PIT table. As soon as the business keys and the load dates from the satellites are in, it’s up to you to extend the PIT.
Best regards,
Marc (Solution Manager)
Hi,
Very good article! 🙂
Could you please share the idea behind having additional hash key columns in the PIT table?
For example, CustomerCAR_HashKey has the same value as the Customer_HashKey for the corresponding line.
When joining PIT with CustomerCAR_SAT, couldn’t we use PIT.Customer_HashKey = CustomerCAR_SAT.Customer_HashKey (+ join on LDTS) ?
Thank you,
Hi Slavon,
this would work from logical perspective, but for performance reasons we don’t recommend this approach (and this is why we use PIT tables). Searching Hash Keys in satellites will reduce query performance as the query would try to search a value which not exists. Additionally, an outer join has to be used what reduces the performance.
You have to add a ghost record in the satellite. This is the first entry in a satellite table where the PIT points to by using an inner join with equi condition, if the Hash Key does not exist in one of the satellites. This is the best way from performance perspective.
Best regards,
Your Scalefree Team
Hi Slavon,
the Customer HashKey is the same in the Hub/Link and its Satellites WHEN the customer exists in a Satellite.
If you put in the PIT only the Cust_HKey from the Hub/Link and the LDTS for each satellite, then when you use the results from the PIT to join on a satellite (on Cust_HKey and LDTS) you have two choices: (1) to use outer join to handle the null OR (2) to “post process” the PIT data entering the join to replace BOTH the Cust_HKey and LDTS with the ones for a ghost record whenever you get a null LDTS from the PIT.
It looks to me way simpler and more performant to put this substitution logic in one place only (when creating the PIT) where the result of the substitution is stored, instead having to add this logic in every query that will ever use the PIT and having to re-evaluate the substitution logic ad every query.
Ciao, Roberto
Hi Roberto
Yes, I agree! We actually go with the second choice here at Scalefree, and use ghost records for null values.
Cheers
Obaid