Data Vault 2.0 Definition
Data Vault 2.0 is a hybrid approach to EDW solutions that was conceived by Dan Linstedt, co-founder and shareholder of Scalefree, in the 1990s.
As a hybrid architecture, it encompasses the best aspects of the third normal form and a star schema. This combination results in a historical-tracking, detail-oriented, uniquely-linked set of normalized tables. All of which help support one or more functional business areas.
Additionally, it is an open standard and is based on three major pillars:
- Methodology
- Architecture
- Modeling
Meeting With an Expert

What is Data Vault 2.0?
Adding to the above, the implementation patterns are considered a sub-pillar of the methodology, focused on increasing agility.
As such, the Data Vault 2.0 model is designed to explicitly meet the needs of today’s enterprise data warehouses. This is achieved by enabling outstanding scalability, flexibility, and consistency. Data Vault 2.0 catapults the original Data Vault modelling concepts into a modern environment.
While modernizing the approach, Data Vault 2.0 still also covers topics like implementation, methodology, and architecture.
Why Data Vault 2.0?
Flexibility
To facilitate a more flexible approach, Data Vault 2.0 handles multiple source systems and frequently changing relationships by minimizing the maintenance workload.
This means that a change in one source system that creates new attributes can be easily implemented by adding another satellite to the Data Vault model. Simply put, new and changing relationships just close one link and create another one.
These examples show the level of high flexibility provided by Data Vault 2.0.
Scalability
As a business grows, the requirements for data grow as well.
In a traditional environment, this would require long implementation processes, high costs, and an extensive list of service-wide impacts.
Though with Data Vault 2.0, new functionalities are able to be added easily and more quickly while having less impact on the downstream systems.
Consistency
Data is used to make important business decisions more frequently.
To ensure that this data can be trusted, data consistency is critical.
To this end, Data Vault 2.0 embeds data consistency in the Data Vault model. In that way, it is possible to capture data in a consistent manner even when the source data, or its delivery, is inconsistent.
And this is all done while being able to load data in parallel with the use of hash values.
This enables faster data access while improving the business user’s satisfaction.
For this reason, Data Vault’s high consistency paves the way for using automation tools to automatically model your Data Vault 2.0 model.
Repeatability
Data Vault methodology follows the CMMI principle.
CMMI is a process-level improvement training and appraisal program that includes five different maturity levels of a company.
This enables it to focus on continually improving processes based on quantitative and prescriptive analysis.
It’s also why Data Vault 2.0 aims to discover the exact maturity level to implement structured development processes.
This simple yet detailed process enables easy repeatability when it comes to performing a new modification on an already planned process.
Agility
One of Data Vault 2.0’s foundational pillars is a methodology that includes several principles of agile work processes.
Therefore, Data Vault projects have a short, scope-controlled release cycle. Usually, these cycles consist of a production release every two to three weeks. This enables the development team to work closely alongside the business’s needs to create a better solution.
Adaptability
A modern business environment often includes frequent changes.
These changes can either be small, with little to no impact on the data structure, or big changes with huge consequences for the underlying data structure.
A good potential use case would be the takeover of another company.
This would create a need to integrate complex new data sources, which is one of Data Vault’s core strengths. The new sources would be modelled as an extension to the existing Data Vault 2.0 model with zero change impact on the existing model.
This lowers the required maintenance to a minimum.
Auditability
Working with data often requires detailed lineage information about the processed data. With Data Vault 2.0, there are different methods that help keep track of your data.
For example, a load timestamp and a detailed record source are required for every row that arrives in the data warehouse. The Data Vault model also historically tracks all changes in your data by using the load date as part of the satellite’s primary key. These factors push the auditability of Data Vault to better levels.
1. Methodology
The Data Vault 2.0 standard provides a best practice for project execution called the “Data Vault 2.0 methodology”. It is derived from core software engineering standards like Scrum, Six Sigma, etc., and adapts these standards for use in data warehousing.
It is comprised of:
- Software Development Life Cycle (SDLC)
- Project management techniques from the PMI Project Management Body of Knowledge (PMBOK)
- Project Management Professional (PMP)
- Capability Maturity Model Integration (CMMI)
- Total Quality Management (TQM)
- Six Sigma rules and principles
2. Architecture
1 - Staging Layer
The staging layer is used when loading batch data into the data warehouse.
Its primary purpose is to extract the source data quickly so that the workload can be reduced on the operational systems. Note that the staging area does not persist data unlike the traditional architectures.
2 - Enterprise Data Warehouse Layer
The unmodified data is loaded into the raw data vault which represents the enterprise data warehouse layer. The purpose of the data warehouse is to hold all historical, time-variant data. All of which is stored in the granularity as provided by the source systems. The data is nonvolatile and every change in the source system is tracked by the Data Vault structure.
After the data has been loaded into the Data Vault model, complete with hubs, links, and satellites, business rules are applied in the business vault. This process occurs on top of the data in the raw data vault.
Once the business logic is applied, both the raw data vault and the business vault are joined and restructured into the business model for information delivery in the information marts.
In addition, the enterprise data warehouse layer can be extended by optional vaults — a metrics vault and an operational vault. The use of the metrics vault is to capture and record runtime information. The operational vault stores data fed into the data warehouse from operational systems. All optional vaults, the metrics vault, the business vault and the operational vault, are part of the Data Vault and are integrated into the data warehouse layer.
3 - Information Delivery Layer
Unlike traditional data warehouses, the data warehouse layer of the Data Vault 2.0 architecture is not directly accessed by end-users. This is because the goal of the enterprise data warehouse is to provide valuable information to its end-users. Note that we use the term information instead of data for this layer.
Further note that the information in the information mart is subject-oriented and can be in aggregated form, flat or wide, prepared for reporting, highly indexed, redundant, and quality cleansed.
It often follows the star schema and forms the basis for both relational reporting and multidimensional OLAP cubes. Other examples for information marts include the Error Mart and the Meta Mart. They are the central location for errors in the data warehouse and the metadata, respectively.
Due to the platform independence of Data Vault 2.0, NoSQL can be used for each data warehouse layer, including the stage area, the enterprise data warehouse layer, and information delivery. Therefore, the NoSQL database could be used as a staging area that can load data into the relational Data Vault layer.
4 - Hard Business Rules
Any rule that does not change the content of individual fields or grain. Instead it only modifies the structure of the incoming data.
5 - Soft Business Rules
Any rule that modifies the content of the data such as turning data into information.
6 - Information Marts
Any structure which the end-user has access to and can be used to produce reports.
7 - Raw Data Vault
The raw data modeled as hubs, links and satellites as well as the content of these artifacts which are provided by the source.
8 - Business Vault
Data that has been modified by the business rules and is modeled in DV style tables; sparsely created.
9 - Realtime Loading
Realtime Data loads as a flow of transactional data.
3. Data Vault Modeling
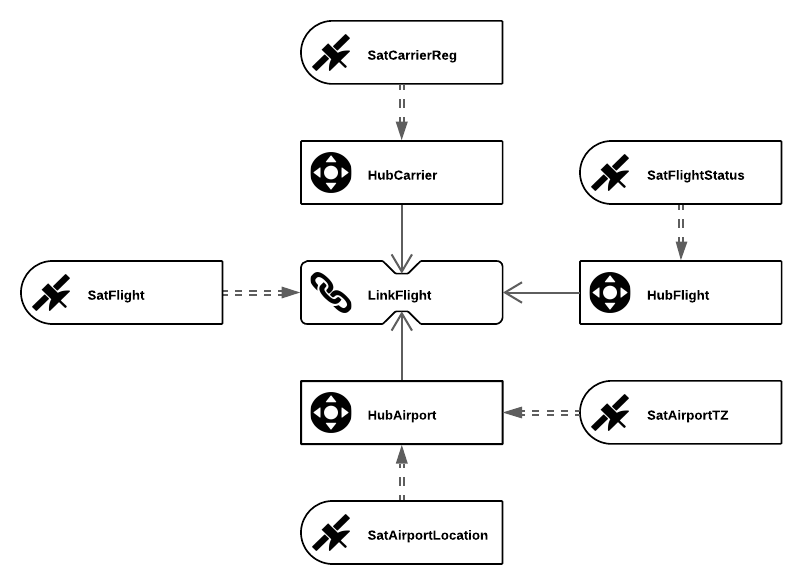
The Data Vault model is based on three basic entity types. These entities are hubs, links and satellites.
Each entity type serves a specific purpose: the hub separates the business keys from the rest of the model; the link stores relationships between business keys; and satellites store the attributes of a business key or relationship.
Hubs
When business users access information in an operational system, they use a business key that refers to a given business object.
Note that business keys can be an invoice number, a vehicle identification number or a customer number. Sometimes, a combination of keys is required to uniquely identify an object.
Business keys are of central importance for the Data Vault model. For that reason they are kept separated from the rest of the model. That separation is performed via hubs.
Each type of business keys is implemented as a different hub. The central elements in an aviation scenario (shown above) are airports, carriers and flights. Therefore, these business keys are modelled as three different hubs HubAirport, HubCarrier & HubFlight.
Links
That said, no business object is entirely separate from other business objects. Instead, they are connected to each other by referring to their business keys. In Data Vault, these relationships are modelled with links that connect two or more hubs.
These hub-link-constructs typically represent purchasing, manufacturing, advertising, marketing and sales.
Links contain the business keys for the connected hubs along with additional metadata.
Though, note that there are still no describing attributes modelled.
In the presented aviation example, a link is used to connect the three hubs HubAirport, HubCarrier and HubFlight. This link is called LinkFlight and represents a complete flight with all its information.
Satellites
A Data Vault model with hubs and links alone would not provide us with sufficient information. The missing piece is the context of these business objects and links. For a flight transaction, this might be the air time of the plane or the security delay of a flight.
Satellites add this functionality to the Data Vault model. Attributes that belong to either a business key of a hub or a relationship/transaction of a link. The change of attributes is also stored inside satellites to keep track of an object’s history.
As you can see with HubAirport, there can be multiple satellites on one hub or link, SatAirportLocation and SatAirportTZ. Reasons for distributing the attributes include multiple or changing source systems or different frequency of changes in data.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Read it for Free
What is a Business Vault?
There are many terms used at times that often cause confusion. So, to give proper definition:
Business Vault = Business Data Vault
and
Raw Vault = Raw Data Vault
and
Raw Data Vault + Business Vault = Data Vault
So, the raw vault is the raw, unfiltered data from the source systems that has been loaded into hubs, links and satellites based on business keys.
The business vault is an extension of a raw vault that applies selected business rules, denormalizations, calculations and other query-assistance functions.
It does this in order to facilitate user access and reporting.
A Business Vault is modeled in DV style tables, such as hubs, links, and satellites, but it is not a complete copy of all objects in the Raw Vault. Within it, there will only be structures that hold some significant business value.
The data will be transformed in a way to apply rules or functions that most of the business users find useful, as opposed to doing these repeatedly into multiple marts. This includes things like data cleansing, data quality, accounting rules, or repeatable calculations.
In Data Vault 2.0, the Business Vault also includes some special entities that help build more efficient queries against the Raw Vault. These are Point-in-Time and Bridge Tables.

Marc Winkelmann
Managing Consultant
Phone: +49 511 87989342
Mobile: +49 151 22413517
Schedule Your
Free Initial Consultation