Introduction to Microsoft Fabric and dbt Cloud
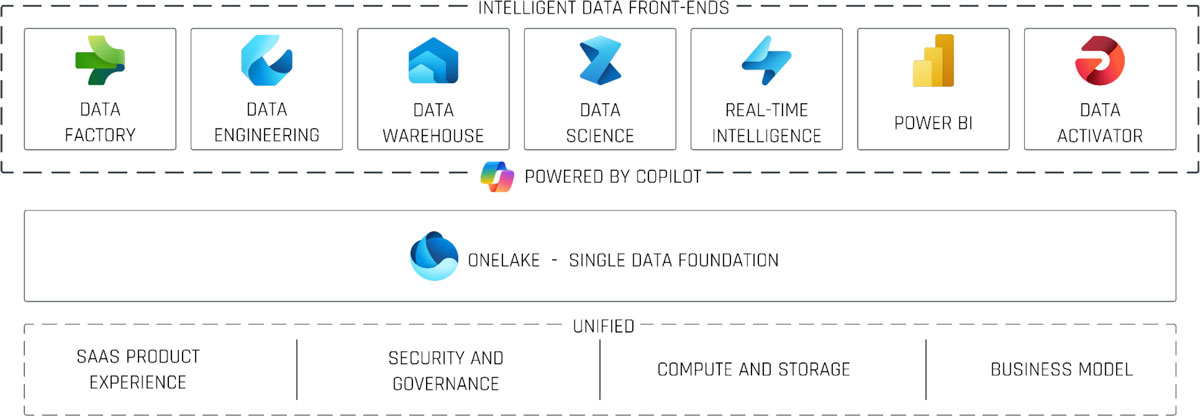
In today’s digital world, organizations need a unified, scalable, and collaborative data platform to power analytics, AI-driven insights, and business intelligence. Enter Microsoft Fabric—a comprehensive, role-based, SaaS-delivered data platform that brings together key Azure services under a single “one lake” foundation with built-in AI capabilities.
In this article, we’ll explore how Microsoft Fabric can serve as your enterprise data platform, how it integrates with data modeling tools like dbt Cloud, and a proven “medallion” reference architecture that takes you from raw data ingestion to business-ready information marts. We’ll also discuss future extensions, practical limitations, and best practices to guide your journey.
Microsoft Fabric as an Enterprise Data Platform
This webinar covers leveraging Microsoft Fabric to implement a modern, end-to-end data platform. You will learn, how the different Fabric services can be combined, to implement a medaillon architecture, supported by Data Vault 2.0 and dbt Cloud. A live demo will show lakehouses, warehouses, and Hub, Links, and Satellites in a real world scenario!
Quick Primer: The Data Vault Methodology
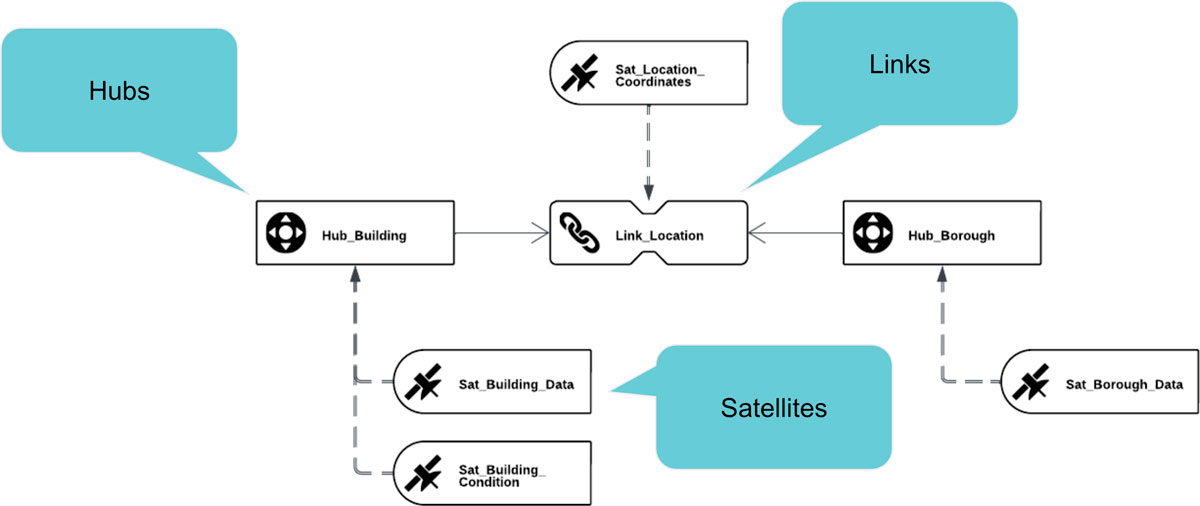
Before diving into Fabric, it’s helpful to understand the Data Vault approach—an architecture pattern that brings agility, auditability, and scalability to your data warehouse. It comprises three core components:
- Business Keys: Unique identifiers of business objects (e.g., customer number in a CRM).
- Descriptive Data: Attributes that describe business keys (e.g., customer name, birthdate), which evolve over time.
- Relationships: Linkages between business keys (e.g., customer–order relationships in a CRM).
By separating these elements into hubs, satellites, and links, Data Vault provides a repeatable, auditable framework for loading and tracing data lineage, perfectly suited for modern cloud platforms.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsMicrosoft Fabric: Core Front-Ends and Services
At its heart, Microsoft Fabric brings together seven role-based “front-end” experiences, but three of them are key to enterprise data engineering and warehousing:
Data Factory
- Data Flows: Low-code transformations (joins, aggregations, cleansing) via a Power Query-like interface.
- Data Pipelines: Petabyte-scale ETL/ELT workflows with full control-flow constructs (if/else, loops).
Use case: Ingest raw data from relational, semi-structured, or unstructured sources into your landing zone lakehouse.
Data Engineering
- Lakehouses: Unified storage for structured/unstructured data in Delta-Parquet format, with SQL endpoints for analytics.
- Notebooks: Interactive Python, R, or Scala environments for data prep, analysis, and data science exploration.
- Spark Job Definitions: Batch and streaming ETL jobs on Spark clusters.
- Data Pipelines: Orchestrated sequences of collection, processing, and transformation steps.
Use case: Land raw data and expose it to data scientists or further transformation processes.
Data Warehouse
- Warehouses: Relational-style databases with Delta-Parquet storage, instant elastic scale, and full transactional support.
- Support for cross-warehouse queries and seamless read access to lakehouses.
Use case: Implement Data Vault’s Raw Vault, Business Vault, and Information Marts for BI consumption.
Workspaces
All Fabric resources live inside workspaces, which group lakehouses, warehouses, notebooks, pipelines, and more. Workspaces enable:z
- Role-based access control and collaboration
- Integration with Git for versioning and CI/CD
- Cross-workspace data access via shortcuts
Integrating dbt Cloud with Microsoft Fabric
dbt Cloud is an industry-leading transformation framework that brings software engineering best practices to your data models: modular SQL, testing, documentation, and CI/CD. In Fabric, dbt Cloud:
- Connects to a Fabric workspace as a data warehouse endpoint
- Generates SQL models (SELECT statements), reading from lakehouses or warehouses
- Executes those models natively on Fabric warehouses
Key benefit: dbt manages your Data Vault layers (hubs, links, satellites, and information marts) with clear lineage, testing, and version control—while Fabric handles execution, storage, and compute elasticity.
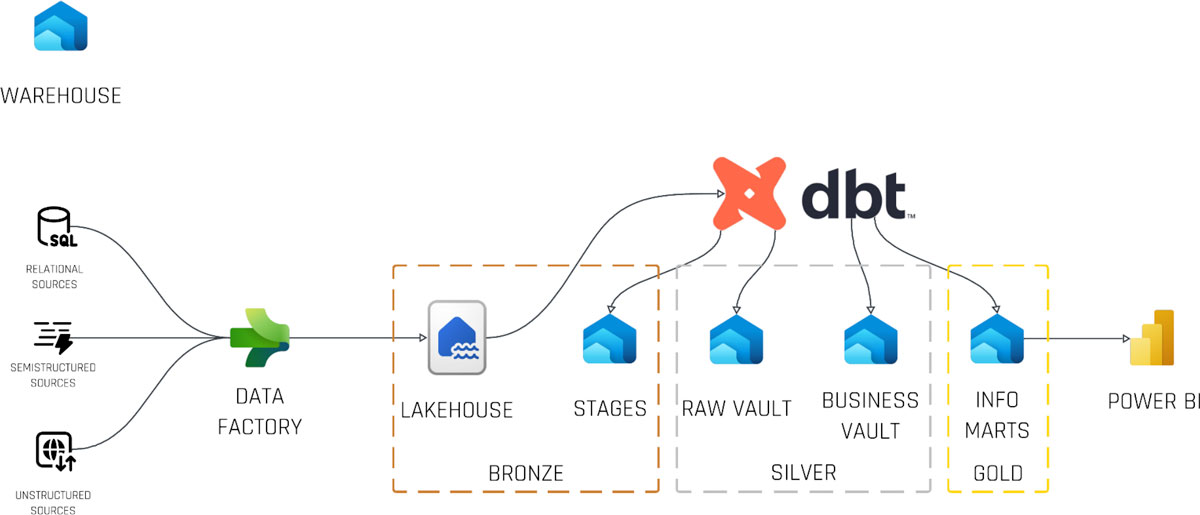
Reference Architecture: The Medallion Approach on Fabric
The modern “medallion” architecture separates data into three refinement layers—Bronze (raw), Silver (conformed/business), and Gold (BI-ready). Here’s how it maps onto Fabric:
Bronze (Landing Zone Lakehouse)
Data Factory pipelines copy raw relational, JSON, and unstructured files into a lakehouse. This fully persisted, immutable history remains read-only for most users.
Silver (Raw & Business Vault Warehouses)
- Raw Vault Warehouse: dbt models generate staging views/tables with hash keys, load dates, and audit metadata.
- Business Vault Warehouse: dbt builds hubs, links, and satellites based on business keys and relationships.
Gold (Information Mart Warehouse)
Information marts—star or snowflake schemas—are created via dbt models as optimized, query-ready tables for BI tools (Power BI, Tableau, etc.).
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsLive Demo Highlights
During our webinar demonstration, we walked through:
- Setting up a Fabric workspace and viewing lakehouse tables via SQL and the Windows Explorer integration
- Using a Data Factory pipeline to ingest sample Snowflake data into a landing zone lakehouse
- Authoring dbt models in dbt Cloud to create staging (hashing, load dates), hub tables, link tables, and satellites
- Executing dbt runs that generate and run SQL in Fabric warehouses, and previewing results directly in the Fabric UI
- Accessing all data files and Delta-Parquet tables seamlessly in Windows Explorer for multi-cloud portability
Outlook: Next-Gen Enhancements
Beyond the core implementation, here are exciting ways to evolve your Fabric-dbt platform:
- Workspace Segmentation & Data Mesh: Create dedicated workspaces for medallion layers or business domains, and stitch multiple dbt projects together with dbt Mesh for a true data mesh design.
- Real-Time Data Integration: Leverage Fabric’s built-in streaming capabilities to blend real-time feeds into your warehouses alongside batch data.
- Enhanced Governance & Semantic Layers: Define and enforce semantic models both in dbt and in Fabric (via semantic models) to ensure consistent metrics across all BI tools.
- Data Science Collaboration: Grant read-only access to bronze lakehouses and empower data scientists to use Fabric notebooks (Python, R, Scala) for ad-hoc analysis and advanced ML experiments.
- Simplified Migration: Existing dbt projects on on-prem or other cloud warehouses can be repointed to Fabric with minimal code changes—especially when using community macros for Data Vault deployments.
Considerations & Limitations
While Fabric is powerful, be mindful of:
- Write Support: Lakehouses currently support only SQL writes—transformations must target Fabric warehouses.
- Shortcut Management: Cross-workspace shortcuts must be manually maintained; frequent schema changes can add overhead.
- Multiple Overlapping Tools: Data Factory, Data Engineering pipelines, notebooks, and dbt all offer ETL—establish clear standards to avoid confusion.
- Product Maturity: As a relatively new platform, UI changes and minor bugs may appear; plan for iterative improvements.
- Capacity Transparency: Compute and storage share capacity; monitor and size your Fabric capacity carefully to meet SLAs.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsConclusion
Microsoft Fabric, coupled with dbt Cloud, delivers an end-to-end Enterprise Data Platform that unifies data ingestion, storage, transformation, and consumption. By applying proven patterns like the medallion architecture and Data Vault methodology, you can build a scalable, collaborative, and governed environment, empowering both data engineers and business users to unlock insights faster.
Ready to take your data platform to the next level? Reach out for a tailored workshop, architecture advisory, or hands-on implementation support.
