Databricks and dbt
Selecting the appropriate technology stack is a critical factor in the successful delivery of a Data Vault 2 architecture. Two technologies that work effectively together at a large scale data solutions are Databricks and dbt. When combined, they provide a practical way to implement Data Vault models while addressing performance, governance, and auditability requirements.
It can be argued that dbt’s role in a Databricks-based architecture is not always essential, since many of its core capabilities (such as transformation scheduling, lineage tracking, and documentation) can also be implemented using native Databricks features. Understanding the specific role each tool plays helps clarify where they complement each other and where functionality overlaps.
In this article:
Databricks as the Processing and Storage Platform
Databricks’ Lakehouse architecture combines the scalability of a data lake with the reliability of a warehouse. Its Delta Lake technology offers ACID transactions, schema enforcement, and time travel, enabling precise historical querying, which are relevant aspects when it comes to Data Vault’s historization requirements.
With Unity Catalog, Databricks centralizes metadata management and enforces fine-grained access control, ensuring sensitive attributes are protected without introducing unnecessary satellite splits. This alignment between governance and performance is particularly relevant in Data Vault environments.
dbt as the Transformation and Orchestration Layer
dbt manages and automates SQL-based transformations in a modular and version-controlled manner. In a Data Vault context, dbt enables:
- The creation of Hubs, Links, and Satellites through templated, reusable models. Here, different packages can be leveraged, like our datavault4dbt package, which is constantly updated to be fully compliant with the most recent Data Vault standards.
- Integrated testing to validate business keys, relationships, and data quality.
- Automated documentation that directly reflects the structure and dependencies of the Data Vault.
This structured approach makes transformations transparent and repeatable, supporting the auditability requirements inherent to Data Vault.

Integration in a Data Vault Workflow
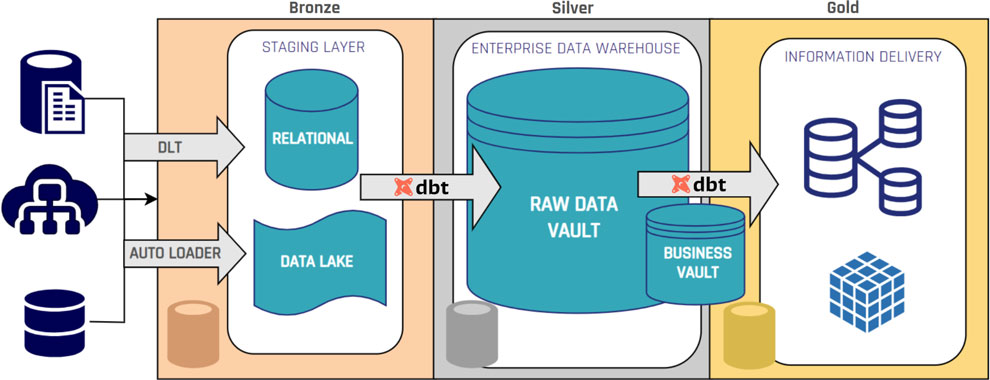
When Databricks and dbt are deployed together:
- Data ingestion occurs in Databricks, storing raw datasets as Delta tables, usually in the Bronze layer.
- dbt transformations generate Raw Vault entities and Business Vault objects in the Silver layer.
- Governance and security controls are enforced via Unity Catalog without altering the Data Vault model structure.
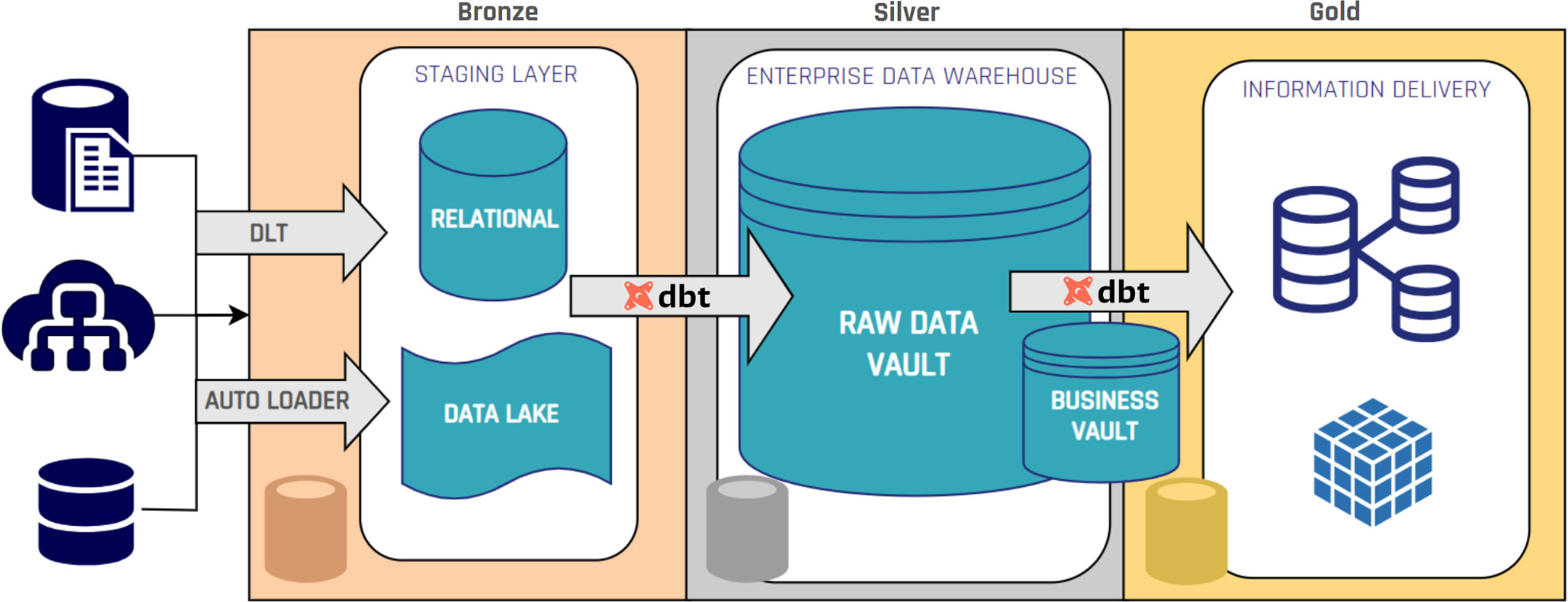
This approach preserves Data Vault’s methodological structure while using Databricks’ distributed compute and storage capabilities.
Business Value when combining dbt and Databricks
The combined use of Databricks and dbt offers:
- Scalable processing of large, complex datasets: Databricks handles enterprise-scale data efficiently, while dbt structures transformations into modular, reusable components.
- Consistent governance across all layers of the Data Vault: dbt’s lineage and documentation, plus Unity Catalog’s access control, ensure compliance and transparency end to end.
- Lower operational risk through tested, version-controlled transformations: Git-based versioning and automated tests in dbt reduce errors before execution on Databricks.
- Improved query performance for information marts and analytics: Delta Lake optimizations and dbt’s pre-aggregated tables with business logic minimize expensive joins.
For organizations building Data Vault on Databricks, dbt strengthens structure and quality while Databricks ensures scalability and performance.
