Raw Data Vault
This question might be as old as the Data Vault: Can it generate the Raw Data Vault using artificial intelligence (AI)? Until recently, the prevailing expectation in the industry was that an AI, if ever existing, might only be able to assist the data modeler, for example, by identifying and suggesting business keys or modeling parts of the model.
The question arises out of need: in the past, data volume and shape have risen exponentially. And there is no sign that it should flatten out in the future. But who should analyze all the data required for today’s data platforms? We already have a shortage of qualified data engineers. And this situation will only become worse in the future because university students don’t rise exponentially.
Generating the Raw Data Vault Using Flow.BI and dbt
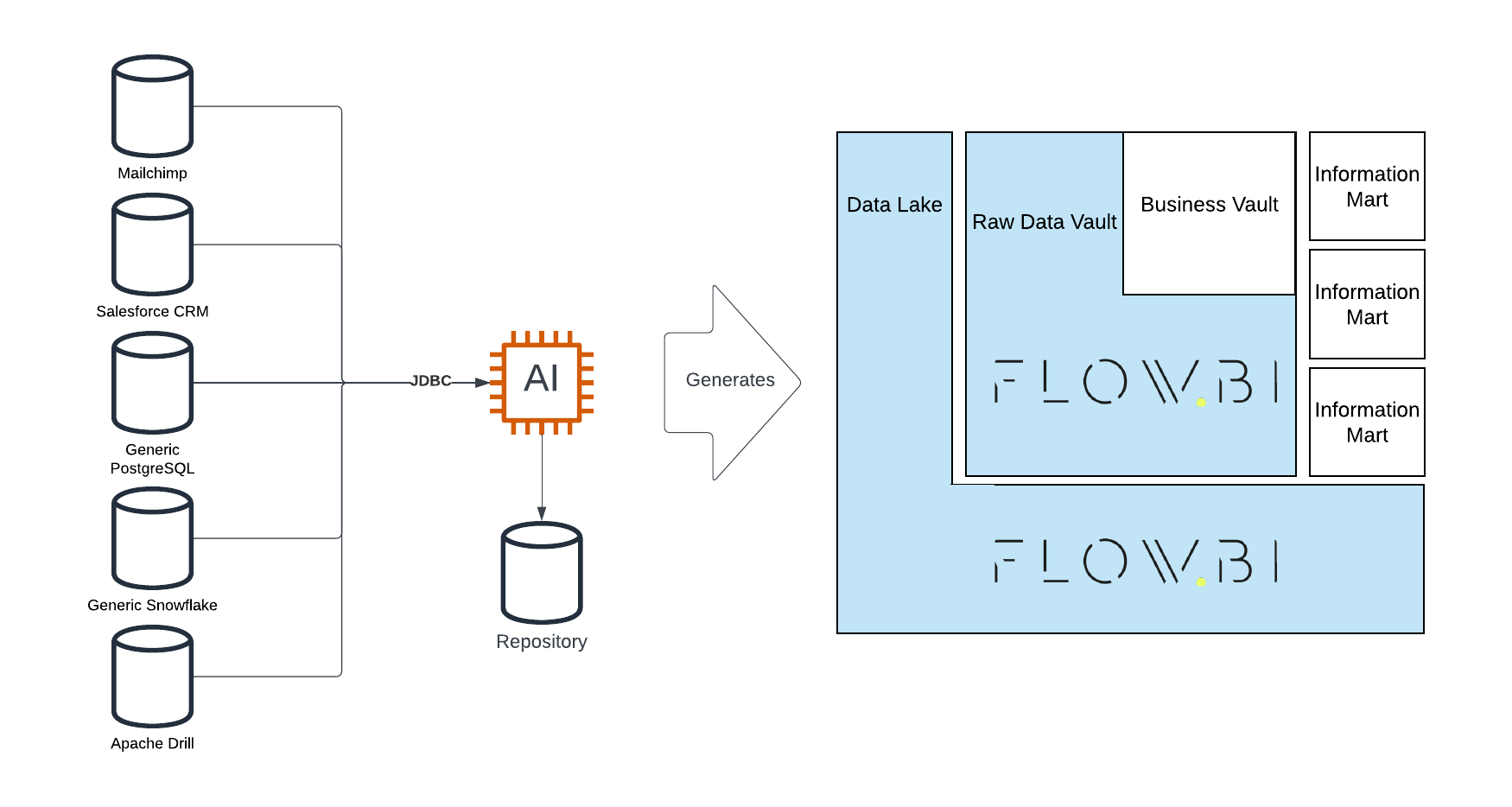
We present the integration between datavault4dbt and Flow.BI which is used to generate the Raw Data Vault. Flow.BI is an artificial intelligence capable of defining all the hubs, links, and satellites for enterprise data. This includes determining the business keys and special entity types such as effectivity satellites, hierarchical links, multi-active satellites, non-historized links, and reference tables. The work-sharing is simple: the advanced AI of Flow.BI defines the Raw Data Vault with all required entities, and datavault4dbt generates the code, including CREATE TABLE and INSERT INTO statements for both the model and the Raw Data Vault loading procedures.
In this article:
- Exceeding Expectations with Generative AI
- Model Structure and Load Definitions
- Simplified Modeling with Flow.BI
- A Data-Driven Approach
- Raw Data Vault vs. Business Logic
- Metadata for Advanced Data Warehousing
- User Control Over AI Modeling
- Integration with Data Warehouse Automation
- Value Proposition of Flow.BI
Exceeding Expectations with Generative AI
With the release of Flow.BI, the expectation that only an assisting AI is possible has been exceeded. Flow.BI is a generative AI that fully “defines” the Raw Data Vault, including:
- Hubs and their business keys
- Links, including hierarchical links
- Satellites, including the satellite splits for privacy, security and rate-of-change
- Non-historized links and their satellites
- Effectivity satellites and multi-active satellites
- Reference hubs and their satellites
Model Structure and Load Definitions
In addition to the model structure, the advanced AI of Flow.BI also defines the load definitions, that is, the definition from where a hub’s business key or satellite’s attribute is loaded. This is later used to generate the INSERT INTO statements.
Because it is all done by the AI, it works at scale and can quickly generate Raw Data Vault models with thousands of entities.
Simplified Modeling with Flow.BI
Flow.BI drastically simplifies the modeling approach: all the user has to do is attach data sources to Flow.BI for analysis and profiling, hit the red button and Flow.BI defines at least a valid model. To achieve this, the solution identifies the concepts in the entities of the data sources first and then the business keys for those concepts. Next, it identifies the relationships and processes the descriptive data attributes into satellites. For the last finishing, the integrated natural language generator adds the entities’ documentation, attributes, and load definitions.
Users can improve the target model by adjusting the identified concepts and the rules for privacy, security, and satellite splits.
A Data-Driven Approach
The model defined by Flow.BI follows a data-driven approach and, therefore, aligns with the teaching of Scalefree’s Data Vault training.
In a data-driven approach, the Data Vault model is “modeling the raw data as the business uses it.” That means the focus is clearly on the raw data, but business keys (“as the business is using it”) integrate data across multiple data sources.
The idea behind this is that business keys are often shared keys that exist in multiple source systems and can, therefore, be used for integration purposes.
Raw Data Vault vs. Business Logic
Business logic, such as WHERE conditions or conditional logic, has no place in a data-driven Raw Data Vault. The Business Vault aims to extend the Raw Data Vault by business logic.
Therefore, the defined model doesn’t contain any business logic, which must be added later in the Business Vault. However, the Raw Data Vault model is an integrated enterprise data model that spans all attached data sources.

Metadata for Advanced Data Warehousing
The metadata produced by Flow.BI can be used not only for generating the Raw Data Vault but also for the staging area, either on a relational database or a data lake.
Flow.BI doesn’t generate the Raw Data Vault alone but defines it. That means it only indicates which hubs, links, and satellites should exist to capture the data from the source systems. But it doesn’t generate the CREATE TABLE and INSERT INTO statements for the physical model. Instead, it relies on tools such as dbt via the datavault4dbt package to generate the code. Flow.BI hands over the metadata of the defined model, and datavault4dbt generates the actual code.
With this in mind, Flow.BI is a teammate who analyzes and profiles the data sources, knows how to model the Raw Data Vault, and ingests the metadata into dbt’s SQL models.
User Control Over AI Modeling
Flow.BI is imitating the human data modeler.
But does this mean that the user has lost control over the AI? No. There are many options to influence Flow.BI’s AI to produce a “better” target model. But first, what “better” means should be defined: fewer entities in the target model? Faster queries? Faster loading? Depending on the goals, Flow.BI can be influenced, for example, by the concept classification and how source data is presented to Flow.BI.
Integration with Data Warehouse Automation
Once the metadata for the Raw Data Vault has been defined, it is handed over to the data warehouse automation (DWA) solution. There are many solutions available, but a popular option is dbt. Scalefree has developed the open-source dbt package datavault4dbt, which enjoys growing popularity in the industry.
To generate SQL models for the dbt package, the integration between Flow.BI and datavault4dbt leverages TurboVault, another open-source package by Scalefree. TurboVault is a graphical user interface that sets up the metadata for a Raw Data Vault to be generated with datavault4dbt.
Once the metadata for the Raw Data Vault has been defined, it is handed over to the data warehouse automation (DWA) solution. There are many solutions available, but a popular option is dbt. Scalefree has developed the open-source dbt package datavault4dbt, which enjoys growing popularity in the industry.
To generate SQL models for the dbt package, the integration between Flow.BI and datavault4dbt leverages TurboVault, another open-source package by Scalefree. TurboVault is a graphical user interface that sets up the metadata for a Raw Data Vault to be generated with datavault4dbt.
The best option was to ingest Flow.BI’s metadata into TurboVault to leverage its capabilities. Once Flow.BI’s metadata has been loaded into TurboVault, TurboVault generates the SQL models for datavault4dbt, which, in turn, generates the Data Vault entities and the loading procedures.
To facilitate the integration between Flow.BI and TurboVault, Scalefree has now released a dedicated Flow.BI connector that retrieves and transforms the logical data models from Flow.BI and enables the automated generation of your Data Vault.
Value Proposition of Flow.BI
Flow.BI offers many values: first, the price. Defining the model using AI is much more cost-effective than manually setting up the metadata for datavault4dbt. Another problem is that Data Vault experts are a scarce resource and not widely available, especially when quality is an essential factor, which always should be the case when dealing with enterprise data.
Another value of Flow.BI is the agility: instead of defining the Raw Data Vault in months and years, Flow.BI’s advanced AI calculates the Raw Data Vault model within minutes and hours.
This also reduces the project risk: what if the Data Vault experts produce a low-quality (or even invalid) model after years of working and millions of Euros spent? Having another attempt at modeling is often unrealistic.
But with Flow.BI, results are close to immediate; if they are unsatisfactory, the manual alternative is still available.
Therefore, the best option to get started is to contact us for a proof of concept or workshop on Flow.BI.
