Hash Keys in DV2.0
Data Vault 2.0 introduces hash keys to enhance the traditional Data Vault model, bringing several advantages to data warehousing. Hash keys do not only speed up the loading process; they also ensure that the enterprise data warehouse can span across multiple environments: on-premise databases, Hadoop clusters, and cloud storage.
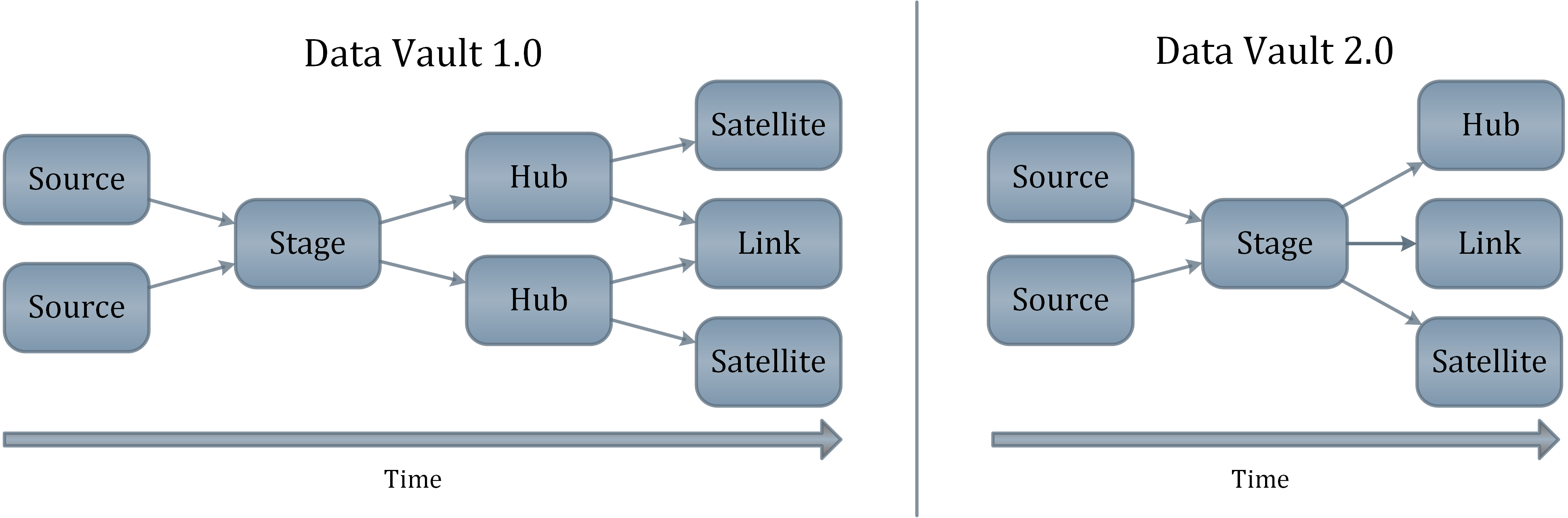
Let’s discuss the performance gain first: to increase the loading procedures, dependencies in the loading process have to be minimized or even eliminated. Back in Data Vault 1.0 sequence numbers were used to identify a business entity and that had to include dependencies during the loading process as a consequence.
These dependencies have slowed down the load process which is especially an issue in real-time-feeds. Hubs had to be loaded first before the load process of the satellites and links could start. The intention is to break these dependencies by using the hash keys instead of sequence numbers as the primary key.
Business Keys vs Hash Keys
In advance, business keys may be a sequence number created by a single source system, e.g. the customer number.
But, business keys can also be a composite key to uniquely identify a business entity, e.g. a flight in the aviation industry is identified by the flight number and the date because the flight number will be reused every day.
In general: a business key is the natural key used by the business to identify a business object.
While using the business keys in Data Vault might be an option, it is actually a slow one, using a lot of storage (even more than hash keys).
Especially in links and their dependent satellites, many composite business keys are required to identify the relationship or transaction/event in a link – and to describe it in the satellite.
This would require a lot of storage and slow down the loading process because not all database engines have the capability to execute efficient joins on variable-length business keys.
On the other hand, we would have too many columns in the link because every business key must be a part of the link.
The issue at this point is that we also have different data types with different lengths in the links. This issue is exaggerated because it is also required to replicate the business keys into their satellites.
To guarantee a consistent join performance, the solution is to combine the business keys into a single column value by using hash functions to calculate a unique representation of a business object.
Massively Parallel Processing (MPP)
Due to the independence during the load process of hubs, links, and satellites, it is possible to do that all in parallel.
The idea is to use the fact that a hash key is derived from a business key or combination of business keys without the need for a lookup in the parent table.
Therefore, instead of looking up the sequence of a business key in a hub before describing the business key in the satellite, we can just calculate the hash key of the business key.
The (correct) implementation of the hash function ensures that the same semantic business key leads to exactly the same hash key, regardless of the target entity loaded.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Hash Keys to Join Apache™ Hadoop® Data Sets
Without hashing the load to Hadoop® or NoSQL requires a lookup on the hub or link sequence in the relational system before it can insert or attach it’s data.
Hashing instead of sequencing means that we can load in complete 100% parallel operations to all hubs, all links, all satellites, and enrich all Hadoop® or NoSQL based documents in parallel at the same time.
It also then allows to join across multiple heterogeneous platforms – from Teradata Database to ApacheTM Hadoop® for example.
Hash Difference
The hash difference column applies to the satellites. The approach is the same as with the business keys, only that here all the descriptive data is hashed.
That reduces the effort during an upload process because just one column has to be looked up. The satellite upload process first examines if the hash key is already in the satellite, and secondly, if there are differences between the hash difference values.
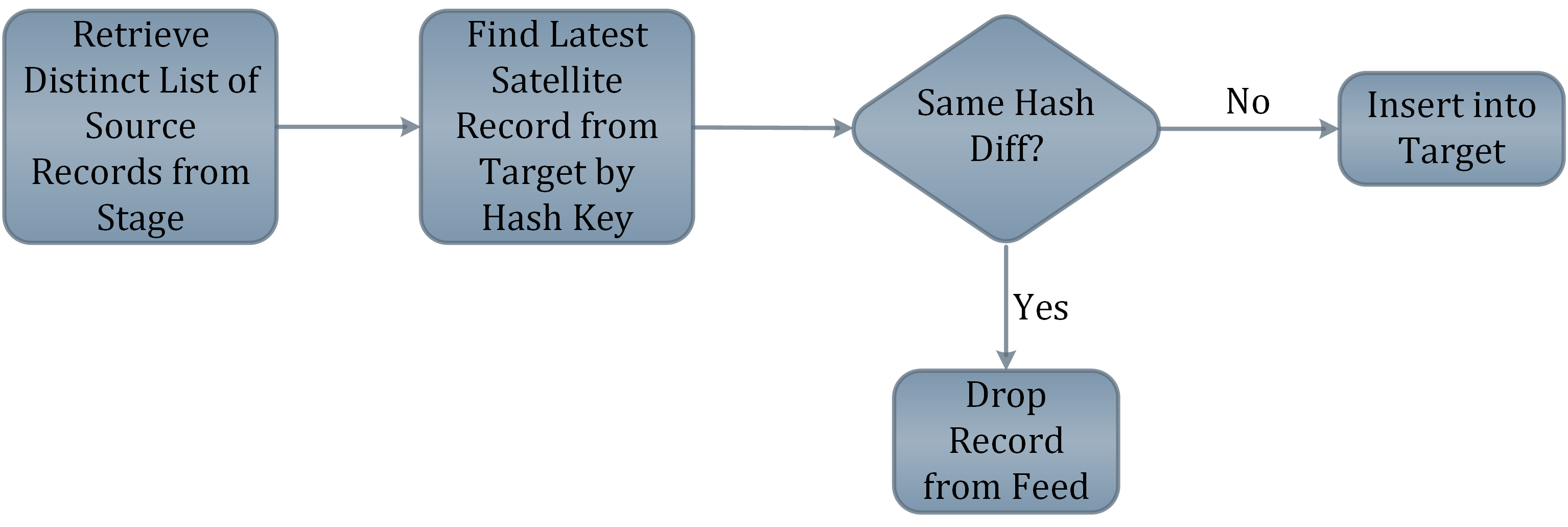
The image above shows the process if the source system sends you a full data delivery.
The point where to hash the values should be on the way into the staging area because at this point there is time to check for “hash collisions”, and handle hashing issues before continuing with the data in the Data Vault.
What Hash Function to Use
There are many hash functions to choose from: MD5, MD6, SHA-1, SHA-2, and some more.
We recommend using the MD5 algorithm with a length of 128 bits in most cases, because it is most ubiquitously available across most platforms, and has a decently low percentage chance of hash collision with an acceptable storage requirement.
An additional advantage hashing brings is that the hashes have the same length and are from the same data type, from which a performance improvement arises.
Furthermore, hash values are generated, so they never get lost and can be recreated.
The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Collision
Hashing has a very small risk: the collision. That means, two different data will get the same hash value.
But, the risk is very small, for example: In a database with more than one trillion hash values, the probability that you will get a collision is like the odds of a meteor landing on your data center.
Summary
Hash Keys are not mandatory in the Data Vault, but they are highly recommended. The advantages of
- massively Parallel Processing (MPP),
- data load performance,
- consistency and
- auditability
are indispensable and can not be reached with Sequences or Business Keys.
Hash keys are no silver bullet…but they provide (much) more advantages than they introduce disadvantages (storage).
We are planning to do a POC on data vault for a datamart project. We are currently using SQL Server 2016 and per microsoft docs, the MD5 function is deprecated. Can you please guide on how to circumvent this problem?
One option is to switch to compatibility level lower than 130. The other option is to create the md5 hash algorithm as a database function by your own: http://binaryworld.net/main/CodeDetail.aspx?CodeId=3600#copy.
Kind regards,
Your Scalefree Team
It’s interesting that data sources are not included in the hashing calculation. Suppose we have two accounting systems: SAP and Quickbooks. If both systems have the same invoice number to represent different invoices, wouldn’t we want a different hash value for these? I suppose an argument could be made for using two different sets of links against the hub for different numbers, but it sounds like queries would get complex here. What’s the best practice for situations like this?
Hi Brad,
you are right – if business keys are overlapping across multiple source systems, we do add such source identifier.
But only in this case – if the same business keys are identifying the semantically same business object, the hub should actually integrate the data across systems. In this case the source identifier would prevent the integration.
Hope that helps,
Mike
No need, as context are stored in separate satellite. Adding source indicator in the hashkey makes it more source specific, and complex
Actually Dhriti, this may be too late to help you, but may help someone else looking at this. Your point about separate Satellites by Source is absolutely correct according to the Data Vault 2.0 standard, however, what is being mentioned above by the Scalefree team is concerning the Hub. The HUB hash key is very important though to the HUB Satellite record (all Satellites across the sources tied to the same HUB entity). Scalefree is pointing out two important points about HUB keys.
The original point made about the same account number for instance across two or more source systems which applies to completely different accounts is one instance. And the same account number across two or more source systems that applies to the SAME account is another instance. Both situations are handled in DV 2.0, but the first instance is handled by adding a concept known as BKCC to the HUB record (Business Key Collision Code). It is simply another field added to the HUB that is filled in with the source system that provided the account number in this example. Then both the BKCC and account number business key are concatenated together (make sure you put a delimiter character between these two concatenated fields) and then hashed (with MD5 or another desired hashing algorithm). This will allow you to distinguish one account from another across source systems (even though they have the same account number). Then each Satellite by source will use the same Hub entity but a different record from the HUB. This is a DV 2.0 standard mechanism.
The second scenario where the same account number across different sources is the same AND is the actual same account, means you can’t use a BKCC for this type of account. You only have the account number in business key of the HUB that you are hashing. Thus the same hash value is used across the different Satellites representing the different sources.
This is what Scalefree was trying to point out in their response.
Now the one circumstance that could get a little more difficult to handle is if the account number is the same account across Sources A and B, but is a different account for sources C and D that is the same account number. There are two ways to handle that, one of them is in the Raw Vault (likely not preferred because is kind of bends the DV 2.0 Raw Vault rules doing it because it involves applying a soft business rule which you aren’t supposed to do until the Business Vault), and the other is in the Business Vault (basically an MDM “Same As” process or HUB record collapsing operation).
If anyone would like more information on any of this or the more difficult account number mixed scenario, feel free to email me and I’ll try to explain in more detail.