Delete and Change Handling Approaches in Data Vault 2.0
In this article, we will show you how to use counter records for change or delete practices in Data Vault 2.0. In January of this year, we published a piece detailing an approach to handle deletes and business key changes of relationships in Data Vault without having an audit trail in place.
This approach is an alternative to the Driving Key structure, which is part of the Data Vault standards and a valid solution.
However, at times it may be difficult to find the business keys in a relationship which will never change and therefore be used as the anchor keys, Link Driving Key, when querying. The presented method inserts counter records for changed or deleted records, specifically for transactional data, and is a straightforward as well as pragmatic approach. However, the article caused a lot of questions, confusion and disagreements.
That being said, it is the intention of this blogpost to dive deeper into the technical implementation in which we could approve by employing it.
In this article:
Technical Implementation in Data Vault 2.0
The following table shows a slightly modified target structure of the link from the previous blog post when using counter records in Data Vault 2.0.
In this case, we are focusing on transactions that have been changed by the source system without delivering any audit data about the changes as well as no counter bookings by the source itself.
It is important to note that the link stores the sales positions by referencing the customer and the product. Thus, the Link Hash Key, as well as the Load Date, are the primary keys as we are not able to gather a consistent singular record ID in this case. Being so, the Link Hash Key is calculated by the Customer Business Key, the Product Business Key, the sales price, and the transaction timestamp.
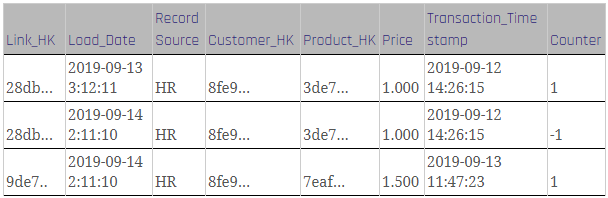
Figure 1: Link with counter records
To load the link, the following steps are required:
Firstly, insert and check as to whether a counter booking is necessary at all as the former step loads new data from the staging area into the link. Please note that the loading logic in this step is similar to that in the standard link loading process, with some differences:
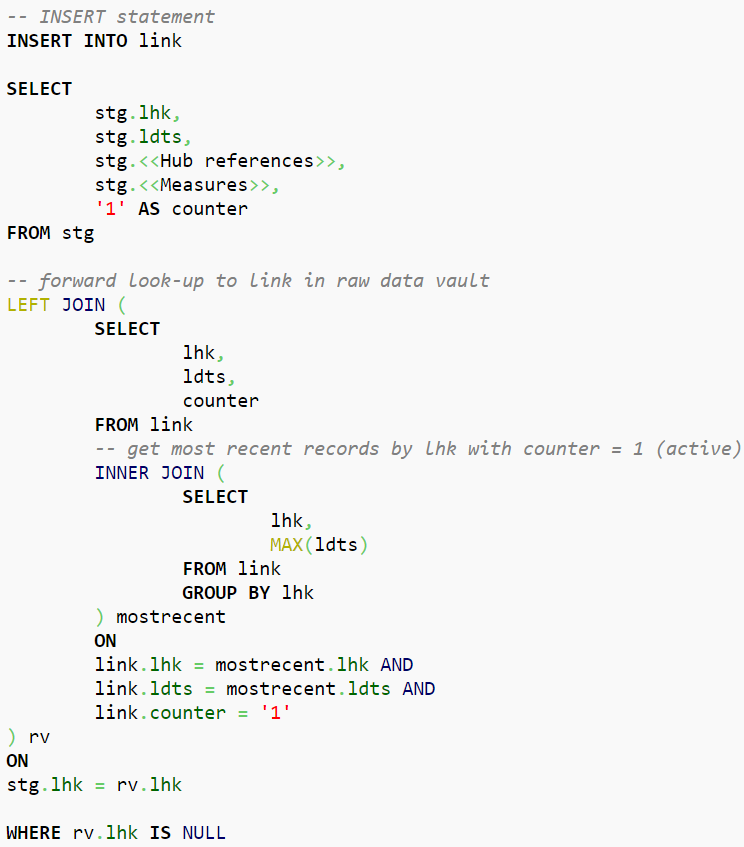
Figure 2: Insert Logic
In Data Vault 2.0, the counter record should identify records, the most recent records by Link Hash Key, that exist in the link but don’t exist in the staging area due to deletion or changes made to the record. Thus, query results will be “countered” with a value for “counter” set to -1, which indicates that these records are not able to be found at this stage. Note that in this query we selected the existing record from the link table in the raw vault, however, further note that the record’s time of arrival should be the LDTS of the actual staging batch. Therefore, within the shown statement, the LDTS is a variable with the load date of the staging batch:

Figure 3: Counter Logic
In instances in which it changes back to the original record, the same procedure applies: The current missing value will be countered by the new one inserted again with a new LDTS.
Conclusion
Thus, we can conclude that this Data Vault approach works well for tables which are a hot-spot for measured values only as well as when changes are possible, although the data represents “transactions” and is to be used when CDC is not available.
Instead of a “get the most recent record per Hash Key (Driving Key)” it is possible to run calculations as well as aggregations directly on one table which results in a better performance in the end stage.
If there are still questions left, please feel free to leave a comment. We are looking forward to an exchange and your thoughts on the topic.

Sorry if I maybe simplify it too much, but it just seems to me that the base problem is that you do not really have an identity for the rows, so you just keep or remove them as a whole.
You are building full row keys by hashing pretty much the full row and checking what is still both in stage and destination (unchanged), what is new (to be inserted) and what has disappeared (to be deleted).
This (joining stage with destination and picking where dest is null) is the only change management procedure available in this case, as there is no CDC and you can assume that a rows that disappear in stage is gone for good (or changed, that’s the same when you do not have a stable identity).
Then you decide that instead of simply tracking the disappearance with a status (in an effectivity sat or any other way to keep a binary info) you enter a new row that balances out the row that has disappeared in stage.
Of course this does not “balances out” everything, but works mostly for sums. E.g. the counts and averages are broken, unless calculated with more complex rules to remove the deleted and their countering friends.
While this is a well known pattern in event based systems (as you cannot delete an authorised credit card purchase or a plane ticket), where the semantic of the event and of its reversal is managed by the applications that embed the required logic, I see many complexities arising in the use for BI as BI tool are all but good at applying any non trivial business logic (let alone their business users at coding it).
As a result I see this as a practical solution to a very specific problem and with a very specific way of using that info. Not a generally useful solution for BI.
As an example, good luck if one of your BI users try to calculate the average price, he would get 500 instead of 1500. (and double good luck to “teach” to any BI tool how to calculate that correctly).
I would like to know your thoughts about this and in particular the general applicability of this pattern to produce BI “ready” tables.
BR, RZ
Hi Roberto,
Marc here from Scalefree.
The main reason for doing it this way is performance, to avoid the additional join into an effectivity satellite (which is delta driven) and works best when dealing with measured data. Keep in mind that this is still part of the Raw or Business Vault. For BI User (not power users) you can and should provide them a (virtualized) Information Mart where the average logic is already applied, in this case by dividing through a distinct number of the customer hash key. In other cases, especially when you deal with a lot of strings for example, the effectivity satellite is usually the better fit. Also keep in mind that this approach ignores “data aging”. It is handling measures which have a transactional character, but aren’t from a technical/delivery perspective.
BR
Marc Finger
The solution for counter or average without using distinct operator is too easy @Roberto Zagni.
We just digging it a little deeper.
for counter customer: quantity of customer = [count(customer) where counter = 1] – [count(customer) where counter = -1] = 2 -1 = 1
for counter product: quantity of product= [count(product) where counter = 1] – [count(product) where counter = -1] = 2 -1 = 1
for average price by customer: sum(price) /quantity of customer = 1500/1 = 1
for average price by customer: sum(price) /quantity of product = 1500/1 =1
I think this pattern by Marc Finger is good and we can think about the way to expand it, especially in big data world, do some process/transform to adapt the business question.