
Hybride Architektur in Data Vault 2.0
Geschäftsanwender erwarten von ihren Data Warehouse-Systemen, dass sie immer mehr Daten laden und aufbereiten, was die Vielfalt, das Volumen und die Geschwindigkeit der Daten betrifft. Auch die Belastung typischer Data Warehouse-Umgebungen nimmt immer mehr zu, insbesondere wenn die ursprüngliche Version des Warehouses von den ersten Anwendern erfolgreich angenommen wurde. Skalierbarkeit hat also mehrere Dimensionen. Letzten Monat sprachen wir über Satellites, die eine wichtige Rolle bei der Skalierbarkeit spielen. Nun wird erläutert, wie mit einer hybriden Architektur strukturierte und unstrukturierte Daten kombiniert werden können.
In diesem Artikel:
Logische Data Vault 2.0-Architektur
Wie in Abbildung 1 dargestellt, wird der Data Vault 2.0 Architektur basiert auf drei Schichten: dem Staging-Bereich, in dem die Rohdaten aus den Quellsystemen gesammelt werden, der Enterprise Data Warehouses modelliert als Data Vault 2.0 und die Informationsbereitstellungsschicht mit Information Marts als Sternschemata und andere Strukturen. Die Architektur unterstützt sowohl das Batch-Laden von Quellsystemen als auch das die Echtzeitbeladung aus dem Enterprise Service Bus (ESB) oder einer anderen serviceorientierten Architektur (SOA).
Das folgende Diagramm zeigt die grundlegendste logische Architektur eines Data Vault 2.0 :
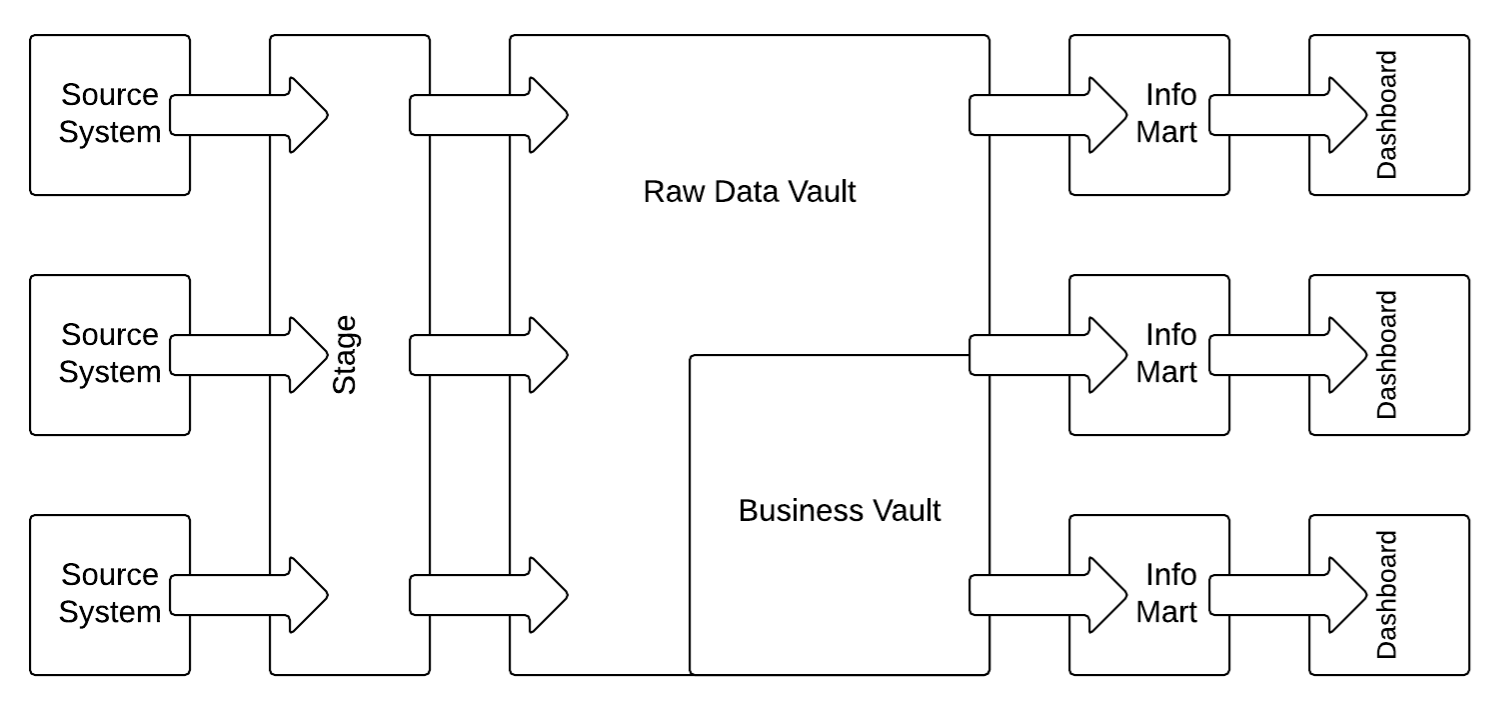
In diesem Fall werden die strukturierten Daten aus den Quellsystemen zunächst in den Staging-Bereich geladen, um die operationale und Leistungsbelastung der operativen Quellsysteme zu verringern. Anschließend werden sie unverändert in den Raw Data Vault geladen, der die Enterprise Data Warehouse-Schicht darstellt. Nachdem die Daten in dieses Data Vault-Modell (mit Hubs, Links und Satelliten) geladen wurden, werden die Geschäftsregeln im Business Vault auf die Daten im Raw Data Vault angewendet. Sobald die Geschäftslogik angewendet wurde, werden sowohl Raw Data Vault als auch Business Vault zusammengeführt und in das Geschäftsmodell für die Informationsbereitstellung in den Information Marts umstrukturiert. Der Geschäftsanwender verwendet Dashboard-Anwendungen (oder Reporting-Anwendungen) für den Zugriff auf die Informationen in den Information Marts.
Die Architektur ermöglicht die Implementierung der Geschäftsregeln im Business Vault mit einer Mischung aus verschiedenen Technologien, wie z. B. SQL-basierter Virtualisierung (in der Regel mit SQL-Views) und externen Tools, wie z. B. Business Rule Management Systems (BRMS).
Es ist jedoch auch möglich, unstrukturierte NoSQL-Datenbanksysteme über eine hybride Architektur zu integrieren. Aufgrund der Plattformunabhängigkeit von Data Vault 2.0 kann NoSQL für jede Data Warehouse-Schicht verwendet werden, einschließlich des Staging-Bereiches, der Enterprise Data Warehouse-Schicht und der Informationsbereitstellung. Daher könnte die NoSQL-Datenbank als Staging Area verwendet werden und Daten in die relationale Data Vault-Schicht laden. Sie könnte aber auch in beide Richtungen mit der Data Vault-Schicht über einen gehashten Business Key integriert werden. In diesem Fall würde es sich um eine Lösung mit hybrider Architektur handeln und die Information Marts würden Daten aus beiden Umgebungen nutzen.
Hybride Architektur
Die Standardarchitektur für Data Vault 2.0 in Abbildung 1 konzentriert sich auf strukturierte Daten. Da es sich bei immer mehr Unternehmensdaten um semi- oder unstrukturierte Daten handelt, ist die empfohlene Best Practice für ein neues Unternehmens-Data Warehouse die Verwendung einer hybriden Architektur auf der Grundlage eines Hadoop-Clusters, wie in der nächsten Abbildung dargestellt:
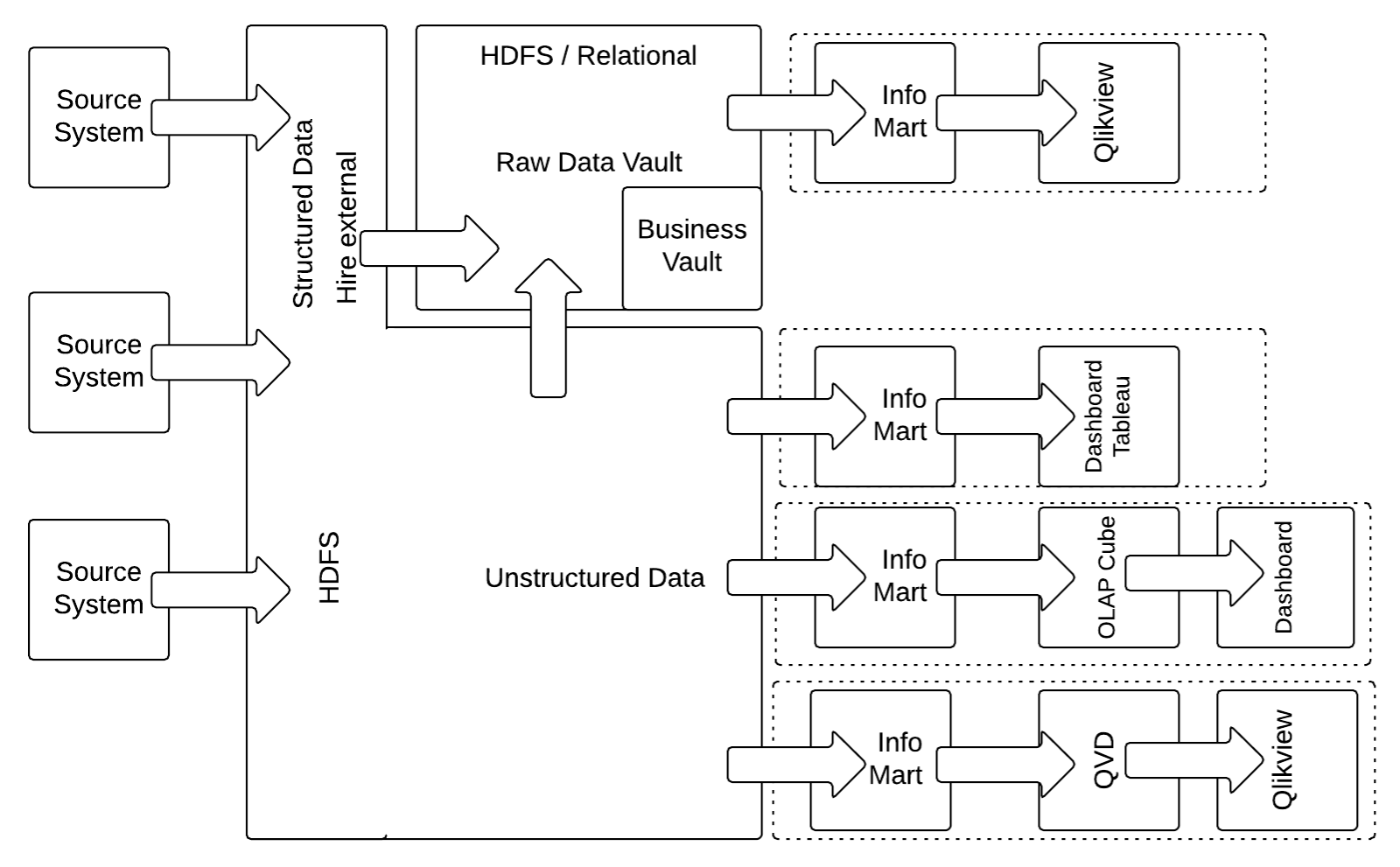
Bei dieser hybriden Modifikation der Architektur wird der relationale Staging-Bereich durch einen Hadoop Distributed File System (HDFS)-basierten Staging-Bereich ersetzt, der alle unstrukturierten und strukturierten Daten erfasst. Während die Erfassung strukturierter Daten im HDFS auf den ersten Blick als Overhead erscheint, reduziert diese Strategie tatsächlich die Belastung des Quellsystems, indem sie sicherstellt, dass die Quelldaten immer extrahiert werden, unabhängig von Änderungen in der Datenstruktur. Die Daten werden dann mit Apache Drill, Hive External oder ähnlichen Technologien extrahiert.
Es ist auch möglich, den Raw Data Vault und den Business Vault (die strukturierten Daten im Data Vault-Modell) intern auf Apache Hive zu speichern.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsFazit
Durch die Integration einer hybriden Architektur in Data Vault 2.0 können Unternehmen sowohl strukturierte als auch unstrukturierte Daten effektiv verwalten, indem sie Plattformen wie Hadoop nutzen. Dieser Ansatz verbessert die Skalierbarkeit und Flexibilität und ermöglicht eine effiziente Datenverarbeitung und -speicherung. Durch das Ersetzen traditioneller relationaler Staging-Bereiche durch HDFS-basierte Systeme können Unternehmen die Belastung der Quellsysteme reduzieren und eine nahtlose Datenextraktion sicherstellen.
This article provides great insights into how hybrid architecture can enhance data warehouse systems. It’s fascinating to see how it can handle increasing data loads!
Great insights on the hybrid architecture! It’s fascinating how this approach can streamline data processing and enhance efficiency in data warehousing. Looking forward to seeing more developments in this area!
Great insights on hybrid architecture! I appreciate the clarity on how to optimize data loading in Data Vault 2.0. It’s fascinating to see how businesses can adapt to increasing data demands with innovative solutions. Looking forward to implementing some of these strategies!
I found the article on hybrid architecture in Data Vault 2.0 to be quite insightful! It really highlights the need for flexibility in data management and how hybrid approaches can enhance data warehousing capabilities. Looking forward to implementing some of these strategies at work!