Not long ago, simple large language models were the pinnacle of AI. Today, they can feel almost rudimentary, as the domain of artificial intelligence is rapidly evolves. Lately, we are seeing a push trying to move beyond one-off prompts and towards AI agents.
It only makes sense that businesses are eager to incorporate AI agents into their workflows, and one domain particularly primed for such transformation is the data team. AI agents can automate repetitive tasks, streamline operations, and enhance data analysis and allow data professionals to focus more on the business side.
Future-Proofing your Data Platform and Unlocking its value as an AI Asset
Many companies investing in enterprise AI find success is limited by the quality of their data platforms. A key issue is “architectural debt,” which hinders the performance and scalability of AI initiatives. This session will provide guidance on how to identify and address these architectural challenges, helping organizations transform their data platforms into reliable assets that support AI agent workflows. Register for our free webinar, October 21st, 2025!
In this article:
- AI Agents: A Brief Introduction
- The Anatomy of AI Agents
- Build a Solid Data Foundation for Agentic AI
- Ensure Data Quality and Metadata Management
- Prepare for Real-Time Processing and Efficient Retrieval
- Implement Orchestration and Observability for AI Workflows
- AI Agents as Identity-Bearing Entities
- Embrace a Data Mesh for Scalable Multi-Agent Workflows
- Design for Modularity and Scalability
AI Agents: A Brief Introduction
AI agents are autonomous software systems that perceive their environment, reason over data, and take actions to achieve specified goals. They leverage large language models, tool‑use frameworks, and API integrations to connect with external services from CRM platforms and cloud storage to data platforms and real‑time event streams. Unlike static models, agents can maintain memory across sessions, chain multiple model calls, and adapt their workflows based on real‑time feedback from connected systems.
The Anatomy of AI Agents
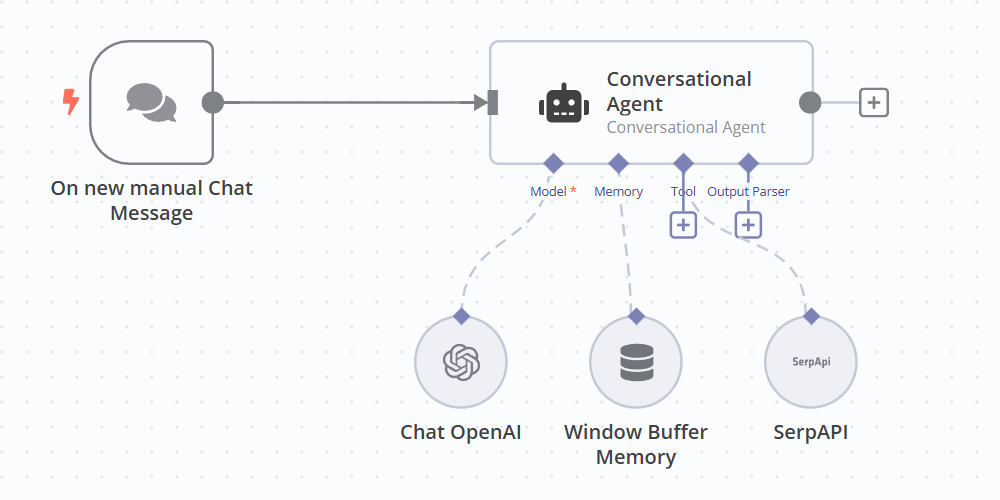
Figure 1: A conversation agent built in low-code automation tool n8n.
An AI agent is typically centered around a large language model that serves as its core reasoning engine, interpreting user inputs, generating plans, and orchestrating decision-making through chain-of-thought or self-prompting techniques. Surrounding this core is a memory structure that can span across immediate working memory, episodic logs, and semantic knowledge stores that persistently captures and condenses interaction histories. To provide durable, structured storage and enable symbolic multi-hop reasoning, agents integrate databases (e.g., SQL, graph, or vector stores) as their internal memory substrate, issuing queries to organize, link, and evolve knowledge beyond the context window of the LLM. Finally, AI agents orchestrate a suite of external tools ranging from RESTful APIs and code execution environments to web scrapers and domain-specific plugins to act upon the world, extend their cognitive reach, and execute actions in both digital and physical domains.
A key limitation of relying on custom APIs as connectors in an AI agent framework is scalability: as you add more agents, tools, and integrations, maintaining a separate API connection for every tool and action soon becomes unmanageable. That’s where MCPs come in.
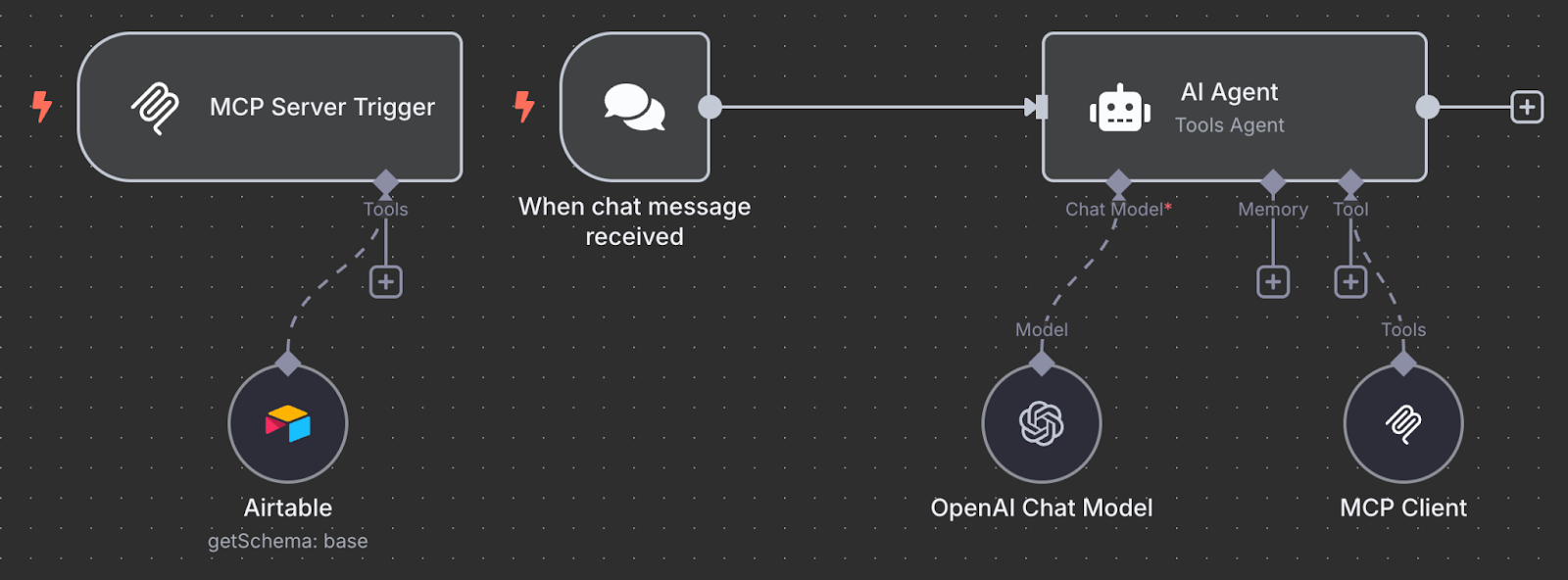
Figure 2: A diagram showcasing Model Context Protocols (MCP)
Developed by Anthropic and open-sourced in November 2024, the Model Context Protocol (MCP) functions as a standardized integration layer that enables the reasoning engine to interface with external resources. It accomplishes this by defining a uniform client–server protocol whereby MCP clients (the AI agents) discover available services via a registry, authenticate, and invoke capabilities such as database queries, function calls, or file retrieval through RESTful endpoints. By decoupling the LLM from tool-specific protocols, MCP fosters a modular ecosystem in which new services can be plugged in dynamically, making AI agent development much more scalable.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsBuild a Solid Data Foundation for Agentic AI
Enterprises that aim to integrate AI agents into their data workloads must first build a solid data foundation. According to a cybersecurity report, 72% of professionals state that IT and security data are siloed within their organizations, creating corporate misalignment and increased security risks. Likewise, an industry study found that in three out of four companies, data silos hinder internal collaboration, and more than 40% report a growing number of such silos.
When data remains in isolated, non-integrated environments, AI agents cannot establish a holistic overview of the data landscape of an enterprise, hence severely limiting its abilities in making meaningful impact.
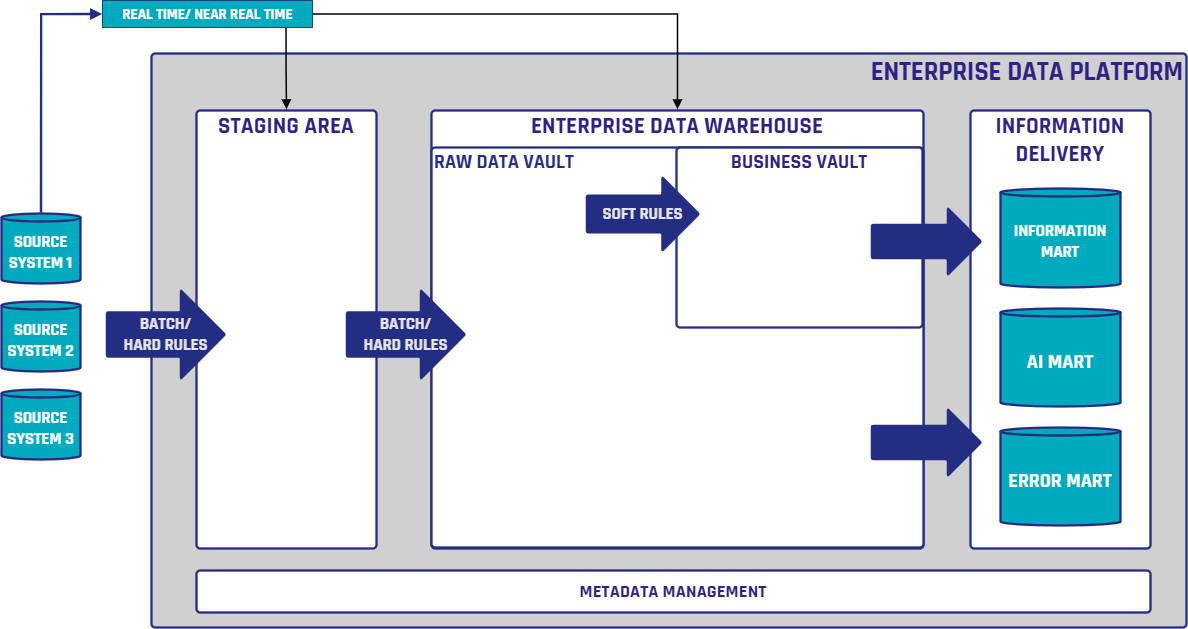
Figure 3: An Enterprise Data Platform diagram, with an EDW
To overcome this, it is best to unify data sources into an enterprise data warehouse (EDW). The EDW must provide both current and historical data in a single data platform. By functioning as a true EDW, the data platform provides a single source of facts for all agents and analytics engines. This means that the AI agents across the enterprise are empowered to create what is needed with the increased availability of data. At Scalefree, we believe that a robust and well-designed data model is foundational to building a scalable and resilient EDW, that supports both operational efficiency and long-term analytical agility.
Ensure Data Quality and Metadata Management
Data quality is already a key issue in data warehousing. Poor data quality can lead to inaccurate insights, flawed decision-making, and ultimately compromise business success. The effectiveness of AI agents is also directly influenced by the quality of the data they consume. Issues such as duplicate records, missing values, and inconsistent schemas can result in erroneous behavior or reduced performance. These issues can be addressed through systematic data cleaning processes and the implementation of data quality tests across ingestion and transformation pipelines. Ongoing monitoring should be in place to detect anomalies and trigger remediation actions where necessary.
Metadata management also plays a role in agent effectiveness. Shared taxonomies and ontologies provide agents with a consistent framework for understanding data definitions across domains. Without standardized metadata, agents may cause errors in reasoning or communication due to misinterpreted values. Establishing a well-maintained data catalog and promoting organization-wide metadata standards supports both data discoverability and semantic consistency, which are essential in multi-agent environments.
Prepare for Real-Time Processing and Efficient Retrieval
AI agents do not strictly require real-time data, but having access to it can significantly enhance their performance and decision-making capabilities. Real-time data allows AI agents to be informed in quickly changing conditions and provide more accurate and relevant responses. To support this, data platforms can be set up to process streaming data or near-real-time updates.
Additionally, indexing strategies must accommodate both structured and unstructured data. When needed, structured data can continue to rely on traditional indexing methods such as inverted indexes. For unstructured content, embedding-based vector search provides agents with the means to identify semantically similar data points.
Large data objects should also be broken into manageable segments through chunking. This practice enables agents to retrieve and reason over smaller, contextually meaningful portions of data, which improves both performance and interpretability. Determining appropriate chunk sizes may require tuning to balance context with precision.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsImplement Orchestration and Observability for AI Workflows
The introduction of AI agents into business processes necessitates a layer of orchestration that governs how agents collaborate, pass information, and handle dependencies. A multi-agent orchestration system should trigger the right agents for a given task, coordinate their outputs, and manage error handling or fallback logic. Orchestrators also need to support asynchronous communication where agents operate independently but contribute to a shared goal.
Monitoring and testing these workflows is essential. Agents can fail, drift from intended behavior, or interact in unintended ways. Logging, alerting, and automated feedback loops can be integrated into orchestration frameworks to surface and correct such deviations. Performance metrics such as response time, accuracy, and success rates should be tracked to ensure continued alignment with business objectives.
AI Agents as Identity-Bearing Entities
AI agents should be treated as identity-bearing entities within the enterprise architecture. This means granting them access only to the data and systems necessary for their assigned roles. To that end, just as any other employee, AI agents should abide by the principle of least privilege. Role-Based Access Control ensures that each agent’s data permissions are explicitly defined and enforceable. For example, an AI agent responsible for financial forecasting should not have access to sensitive HR data.
Integrating AI agents into existing identity and access management (IAM) systems can help enforce compliance and support auditability. Just as human users have roles and access policies, agents should be provisioned, monitored, and offboarded in a controlled and traceable manner.
Embrace a Data Mesh for Scalable Multi-Agent Workflows
Organizations expecting to deploy multiple AI agents concurrently should consider transitioning from a centralized end-to-end model to a data mesh. A data mesh distributes data ownership across domain teams and treats data as a product, aligning well with the modular nature of AI agents. This architecture allows agents to scale horizontally across business functions while maintaining domain-specific ownership of data pipelines and logic. Each agent can operate on a defined domain without depending on a centralized data engineering team, reducing bottlenecks and increasing agility. In environments with high agent interaction, domain-driven decentralization ensures that systems remain responsive and maintainable as usage grows.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsDesign for Modularity and Scalability
To scale the use of AI agents across business processes, data pipelines should be decomposed into independently deployable and maintainable components. This approach allows new agents or features to be added without having to duplicate or fork existing systems. Event-driven architectures, in which agents react to messages or state changes, support this level of decoupling and flexibility.
Agent-to-agent communication should be standardized using standardized protocols and contracts to allow agent-to-agent interaction predictably. By designing systems with modular interfaces and reusable components, AI agent ecosystems can grow in an agile, iterative fashion.
