Data Warehousing
A data warehouse is a subject oriented, nonvolatile, integrated, time variant collection of data to support management’s decisions
Inmon, W. H. (2005). Building the Data Warehouse. Indianapolis, Ind.: Wiley.
Data Warehousing provides the infrastructure needed to run Business Intelligence effectively. Its purpose is to integrate data from different data sources and to provide a historicised database. Through a DWH, consistent and reliable reporting can be ensured. A standardized view of the data can prevent interpretation errors, improved data quality and leads to better decision-making. Furthermore, the historization of data offers additional analysis possibilities and leads to (complete) auditability.
Data Warehousing – Why we need it
This webinar delves into how a data warehouse integrates data from various sources to support business intelligence by providing a centralized, historical database. This integration ensures consistent and reliable reporting, improves data quality, and facilitates better decision-making. Additionally, maintaining historical data enables comprehensive analysis and complete auditability.
Why do we need Data Warehousing?
“Why do we need data warehousing for reporting, we have excel sheets?!”
Yes, excel is a great tool… to use and lose control over your data as well as your reports.
You can report directly from a data source but you are massively limited in functionality and governance. Furthermore, you can only generate reports from one source system and don’t have a delta-driven history of your data. By creating reports directly from the source system and storing them on a local pc you lose track of which user pulled the data, as well as at what time, to build the report. Thus, the reports are no longer reliable. To prevent this, data warehousing comes into play.
Let’s imagine our goal is to build a sales revenue dashboard based on a timeline, a customer group, your products and regions. Without a DWH you have to collect all data manually from all necessary source systems. This data is most likely a mix of structured, unstructured and semi structured data. The challenge then becomes how to prepare and visualise the data in addition to creating an easily repeatable method of doing so. This is very time-consuming and can be very costly.
By the time all data is collected and prepared, the data may already be out of date causing the need to start again.
With a DWH, all data is collected at one single point. The Data is aligned to the business (integrated & subject-oriented) with standardised definitions e.g. of KPI’s so that every report interprets the data equally. The access to the DWH is read only (non-volatile), once loaded you can’t change the data (auditable). This leads to a complete historization of the data (time variant). With all data available, the needs of the users can be satisfied (structured data, integrated by business terms). For business users, there is also the option of using Self-Service BI.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsWhat about a Data Lake?
As the “data lake” was introduced a couple of years ago, there was the assumption that it would replace a data warehouse.
A data lake is a great environment when used as a first landing zone for your data in your IT infrastructure but it does not “integrate” the data as a data warehouse does.
A data lake can be used to process the data further downstream into your data warehouse and an information delivery area. Structure becomes very important at this point so that your data lake doesn’t turn into a data dump and you are always able to query the data you need in an easy way.
To this end, you must create an architectural design dependent upon how you process the data from your data lake into your data warehouse. This could also happen in a completely virtualized way, depending on the amount of data as well as respectively the performance necessary to process the data towards the point of the end-users.
A data lake is also a good place for data scientists to gain access to the data as soon as possible, even if it is the native format. For end users who are working with structural data for reporting, dashboarding and analysis purposes, a structured, integrated, well-performing and easy-to-access data warehouse is necessary to fulfil their requirements. They expect the data in a prepared information mart, like a star schema or a flat and wide table.
Conclusion: If you want to use a data lake, think about how you need and process the data on the way out so that you can create a suitable structure for it. If you don’t need your data integrated, subject-oriented and time-variant, then you may be fine with a data lake only. But if you need all these great properties, you definitely need a data warehouse.
How does Data Warehousing work?
It starts with the ETL process (extract, transform, and load) in which the data is extracted from the source system into your technical environment / (DWH infrastructure) called the “Staging Area”. After extracting all data from the source system, you integrate your data into a subject oriented structure. The result is an Enterprise Data Warehouse (EDW) which provides data and information about how the end user needs it.
There are several modeling techniques available to build a data warehouse. 3NF (third normal form) was invented by Bill Inmon and is also known as the top-down approach. Alternatively, Dimensional Modeling by Kimball is more aligned to the business processes (bottom-up approach). Data Vault 2.0 is a hybrid between 3NF and dimensional modeling invented by Dan Linstedt. At Scalefree, we specialize in Data Vault 2.0 modeling.
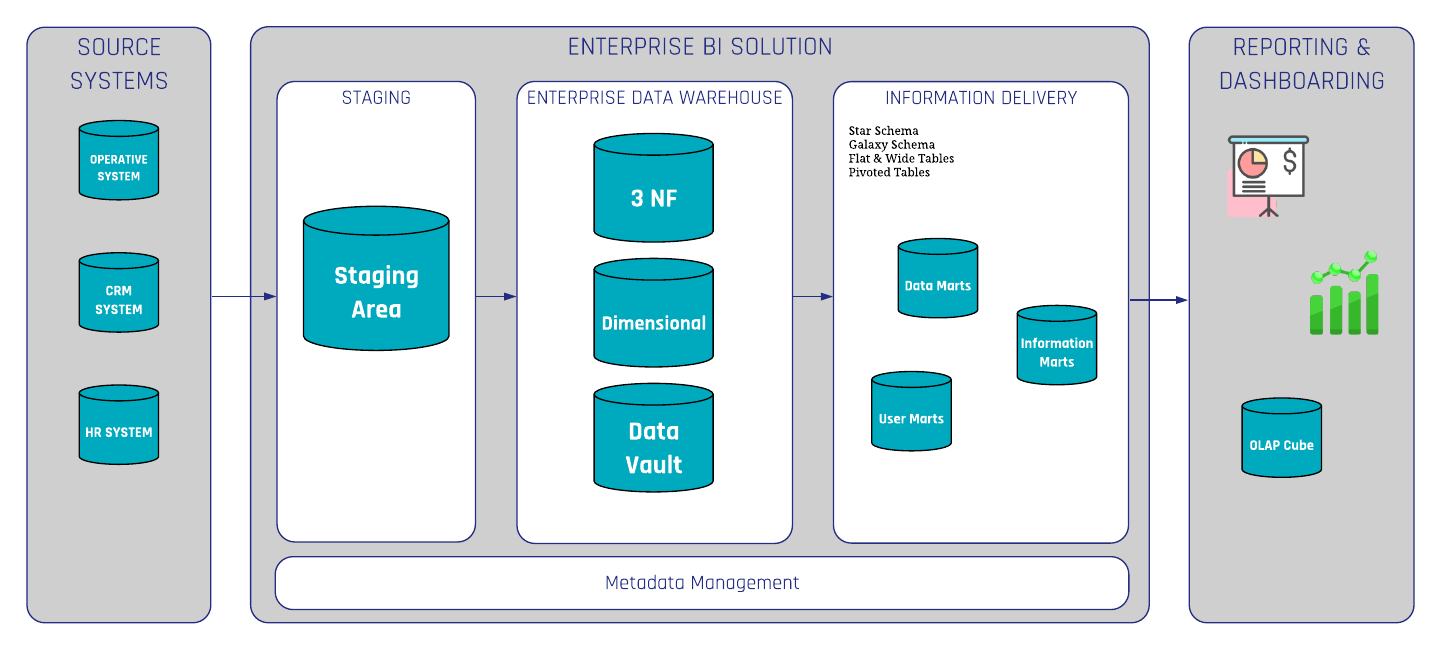
Data Warehousing Reference Architecture
Conclusion
When only utilizing this single aspect of an EDW, users are missing opportunities to take advantage of their data by limiting the EDW to such basic use cases. A variety of use cases can be realized by using the data warehouse, e.g. to optimize and automate operational processes, predict the future, push data back to operational systems as a new input or to trigger events outside the data warehouse, to simply explore but a few new opportunities available.
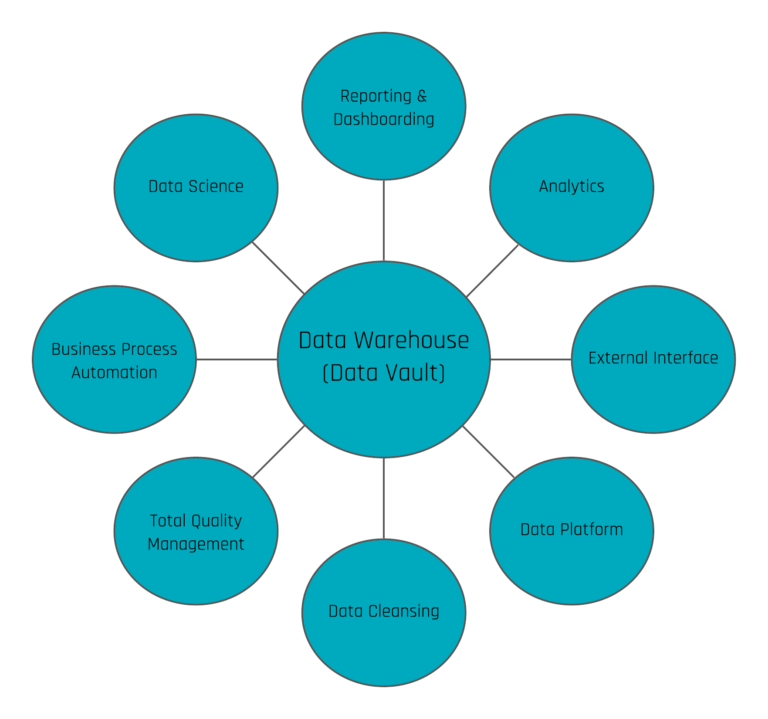
Data Vault 2.0 Use Cases
Data warehousing is ideal for centrally storing all internal and external data sources. The standardization of structured, unstructured, and semi-structured data enables faster and more reliable reporting. Historization allows additional reports and past reports can be reconstructed at any time. With the flexibility of Data Vault 2.0, organizations can apply new capabilities, which go beyond just standard reporting and dashboarding.
If you want to learn more about Data Vault 2.0 Use Cases and the latest technologies from the market, we offer a broad range of free knowledge on our blog/newsletter and webinars. Feel free to sign up for regular updates.
