

Whats new in Data Vault?
Attendees of our Data Vault 2.0 trainings often ask us what the difference between the book “Building a Scalable Data Warehouse with Data Vault 2.0” and our current consulting practice is. To give a definitive answer, at least for now, we have written this article.

Data Vault 3.0?
First of all, there is no Data Vault 3.0. We like to refer to the version of Data Vault that we teach and apply in our consulting practice, as “Data Vault 2.0.1”. Therefore, there are only slight differences to the version we used in the book. Some of these changes look big, but they don’t really modify the underlying concept and that is what matters regarding version changes. So, based on the concept, we only see minor changes or enhancements. However, they might have some larger impact on the actual implementation, but that is only due to technology changes.
How to Fit Data Vault 2.0 Between Two Covers
On top of the minor changes to the concept, there is also another factor at play here: when writing the book, we had to scope the book to make it fit between the covers as the publisher had a page limit (which we actually exceeded a bit). Therefore, we did not apply all Data Vault 2.0 concepts in the book: for example, real-time concepts are not covered by the book, and we did not use a data lake or cloud computing in our examples. Instead we only briefly covered these concepts for completeness but focused on on-premise technology which was more used in actual projects back then. In 2012, cloud computing was already available and widely used, but it was easier to tailor the book to more readers by the use of on-premise technologies.
With that in mind, what has changed since the book came out?
Removal of Load End Date
The most obvious change is the removal of the Load End Date. Well, in our actual projects, we don’t completely remove it from the Data Vault 2.0 model, we just virtualize it by removing the Load End Date from the underlying satellite table and virtually calculating it in a view on top of the satellite table using a window function (typically LEAD, but LAG is also possible). This way we can get rid of the update procedure to maintain the Load End Date (the so-called end-dating process) while preserving the query patterns downstream. Keep in mind that it might also be more efficient to use the window function when loading PIT tables or satellites, and therefore the query layer is actually only for power users when they query the Data Vault model directly.
That’s actually not an update: even in 2012 (and before) we used these approaches but they didn’t work on SQL Server 2014, which was used in the book as the analytical window function required for this approach is ways too slow. However, it improved in 2016. To get rid of the Load End Date in such scenarios where the window function is too slow or just don’t exist, a new solution has emerged: the use of a snapshot partition in the PIT table. The end of all times is used in the PIT table to refer to the latest delta in each satellite for the delta check. Once the PIT table is available, it can also be used to produce SCD Type 1 dimensions (without history) and therefore the need for the Load End Date (or a fast replacement as described above) only exists in loading.
Hybrid Architecture
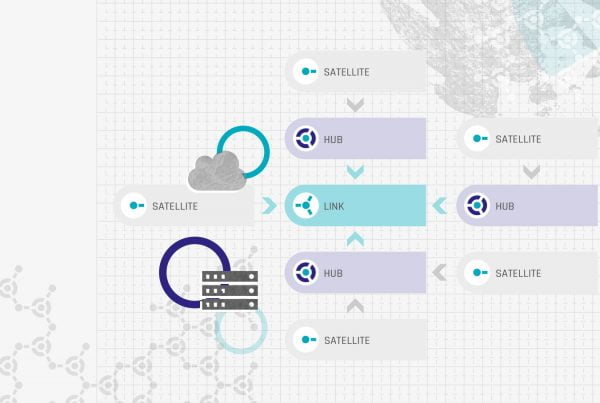
The next obvious change is the use of a hybrid architecture where a data lake is used for staging purposes. In the book, we focused on the on-premise Microsoft SQL Server stack that didn’t include a distributed file system. We already recommended to clients to use a data lake for staging purposes, in an architecture we called the “hybrid architecture.” Back then, only a few followed the advice, but today most clients use the hybrid architecture for their data warehouse. We actually consider a relational staging area an anti-pattern and do not recommend it anymore to clients (with some exceptions).
Multi Temporal Data Vault 2.0
The book describes a temporal PIT (TPIT) for building multi-temporal solutions. While the pattern is still valid and relatively flexible compared to other solutions, today we typically move the business timelines into the dimensional model for highest flexibility. This is discussed in more detail in the Multi-Temporal Data Vault 2.0 class. TPITs are less flexible but have higher performance.
Snapshot Date
Satellites in the Business Vault might use a Snapshot Date Timestamp instead of a Load Date Timestamp. The idea is that, as a general practice, a Business Vault entity should always reuse an existing granularity. It just becomes much easier to develop Business Vault solutions. With the Snapshot date in the primary key of the satellite, this becomes much easier for business rules on the outgoing information granularitiy. This is discussed in more detail in the Data Vault 2.0 Information Delivery class.
A Confession
And finally, we also made some mistakes. We are willing (not happy) to admit it in our errata page for the book – this link is directly from our internal Wiki and we promise to keep it updated (however, we didn’t receive additional reports lately).
Get Updates and Support
Please send inquiries and feature requests to [email protected].
For Data Vault training and on-site training inquiries, please contact [email protected] or register at www.scalefree.com.
To support the creation of Visual Data Vault drawings in Microsoft Visio, a stencil is implemented that can be used to draw Data Vault models. The stencil is available at www.visualdatavault.com.


I recently purchased the book “Building a Scalable Data Warehouses with Data Vault 2.0” and have found it very useful for understanding the details of Data Vault, and maybe more importantly, the methodology for approaching the agile practices associated with it.
I have been searching for any errata on the book without success. Today, I ran across this page on the “scalefree.com” site:
What’s new in Data Vault? | Experts in Consulting and Training (scalefree.com)
It incudes a confession section:
A CONFESSION
And finally, we also made some mistakes. We are willing (not happy) to admit it in our errata page for the book – this link is directly from our internal Wiki and we promise to keep it updated (however, we didn’t receive additional reports lately).
Would you please provide that link?
Hi John,
of course, here is the link: https://scalefr.ee/LPm8BT
Hope this help.
Mike