Implementing GDPR
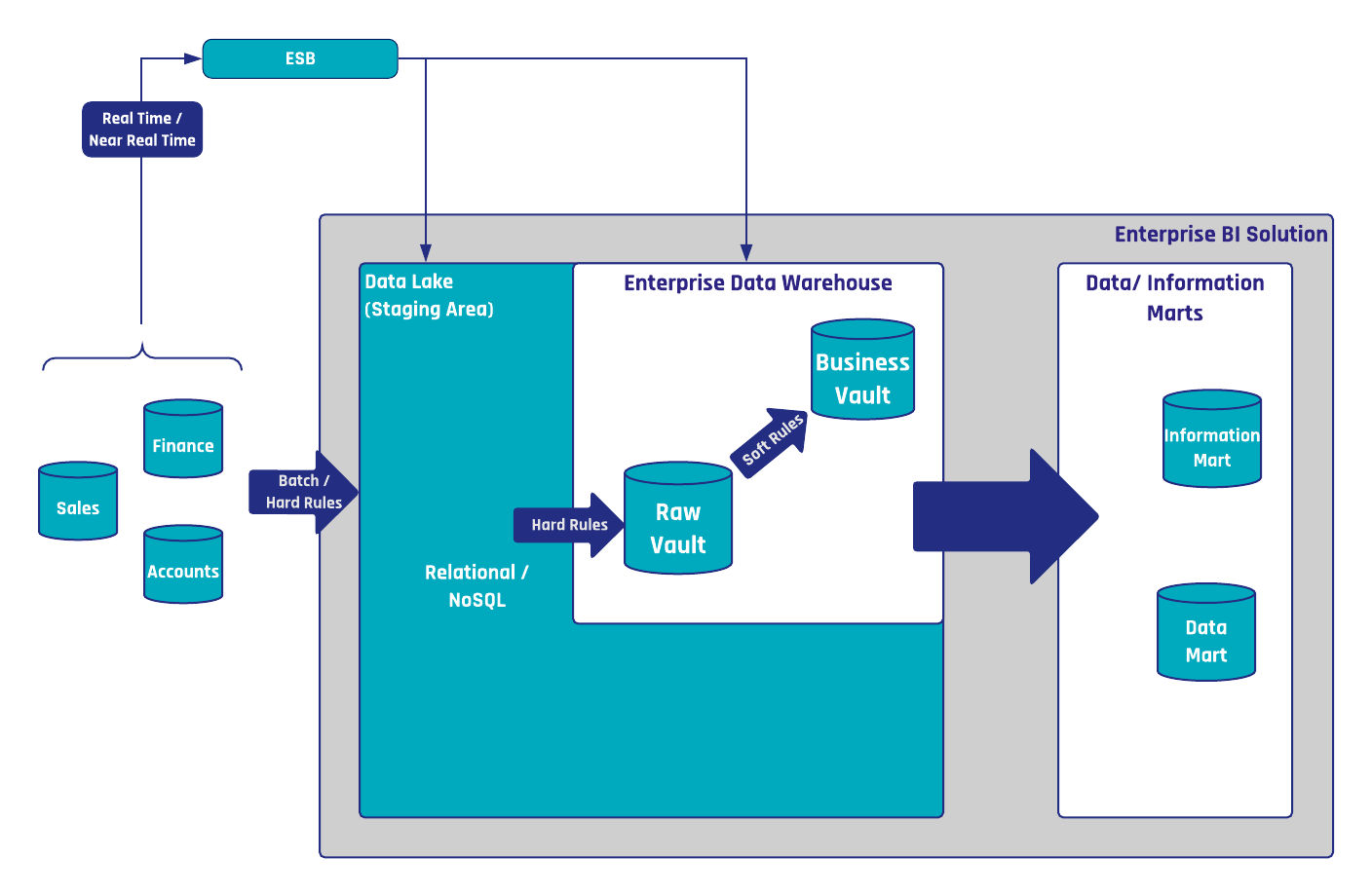
In the realm of data warehousing, whether it be Data Vault 2.0 or traditional approaches like Kimball and Inmon, data is stored and processed across multiple layers. The intricacies of privacy, particularly the application of security measures and the concept of the “right to be forgotten,” permeate every layer housing personal data.
For privacy implementation, the primary objective is the removal of Personally Identifiable Information (PII) data from each layer. This meticulous process aims to extract PII data, leaving non-PII data intact. In the ideal scenario, this ensures a reduction in consumer data proportionate to the removed PII data.
The General Data Protection Regulation (GDPR) casts a significant influence on data warehouse projects, introducing stringent requirements for data processing and storage. This impact spans across security considerations, determining who has access to what data, and privacy mandates, addressing the right to be forgotten.