Combining Managed Self-Service BI with Data Vault 2.0
This article explores how combining Managed Self-Service BI with Data Vault 2.0 enables organizations to balance data governance and agility, ensuring both control and flexibility in their analytics processes.Last month we talked about a hybrid architecture in Data Vault 2.0, where we explain how to combine structured and unstructured data with a hybrid architecture. To follow up on this topic, we now want to explain how your business users (especially power users) can take a benefit from it with the managed Self-Service Business Intelligence (mSSBI) approach in Data Vault 2.0.
About Self-Service BI
Self-service BI allows end-users to completely circumvent IT due to this unresponsiveness of IT. In this approach, business users are left on their own with the whole process of sourcing the data from operational systems, integration and consolidation of the raw data. There are many problems with this self-service approach without the involvement of IT:
- Direct access to source systems
- Unintegrated raw data
- Low data quality
- Unconsolidated raw data
- Non-standardized business rules
In many cases, end-users – even if they are power users with the knowledge to SQL, MDX, and other techniques, don’t have the right tools available to solve the tasks. Instead, much work is done manually and error-prone. But from our experience, it is not possible to completely prevent such power users from obtaining data from source systems, preparing it, and eventually reporting the data to upper management. What organizations need is a compromise between IT agility and data management that allows power users to obtain the data they need quickly, in a usable quality. To overcome these problems, the Data Vault 2.0 standard allows experienced or advanced business users to perform their own data analysis tasks on the raw data of the data warehouse.
About the Managed Self-Service BI Approach
In fact, a Data Vault 2.0 powered IT welcomes business users to take the data that is available in the enterprise data warehouse (either in the Raw Data Vault or in the Business Vault) to create local information marts using specialized tools. These tools retrieve the data from the enterprise data warehouse, apply a set of user-defined business rules and present the output to the end-user. IT might also create structures where organizational-wide business rules are applied to provide a consolidated view on parts of the model or pre-calculate KPIs to ensure consistency among such calculations. Because both types of data (raw data and business rule applied data) is already integrated, the business user can also join consolidated data with raw data from specific source systems. This approach is called Managed Self-Service BI, where IT evolves to a service organization that provides those power users with the data they want, in the timeframe they need. The data is integrated by its business key and can be consolidated as well as quality checked.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Implement MSSI in the Data Vault 2.0 Architecture
The Data Vault 2.0 architecture provides self-service capabilities for power users in the organization:
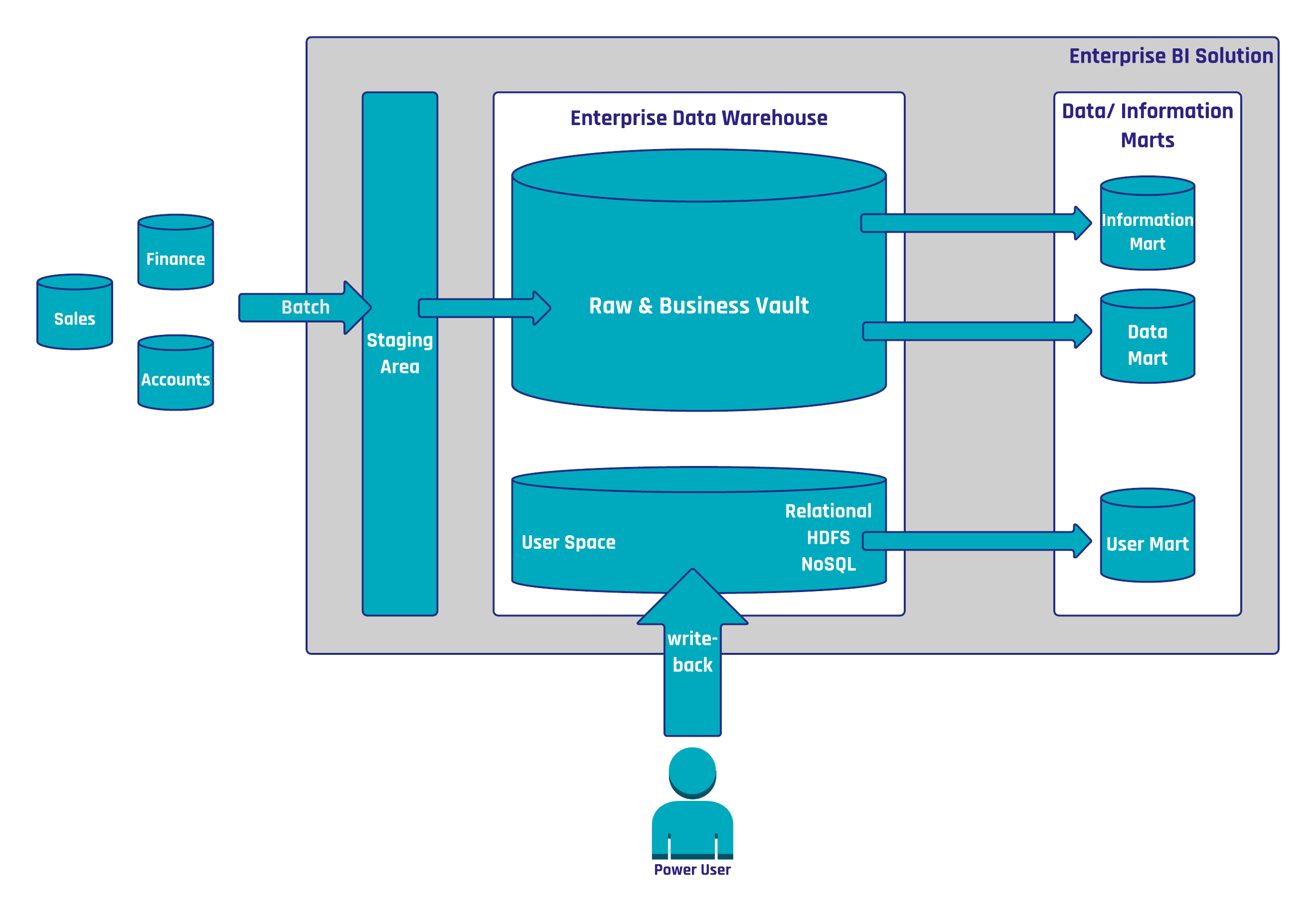
In this case, power users who build their own, custom solutions can write back data and information into the Enterprise Data Warehouse by leveraging a dedicated user space for this purpose. The write-back can then later be re-used in the solution for information delivery. Furthermore, the business users can manage their own master data by using an MDM application. It enables authorized business users to change the parameter values and therefore influence the results of the business rules.
The difference between “managed” Self-Service BI to the standard Self-Service BI approach from the general industry is that Data Vault 2.0 provides a managed environment where data and information are provided in a controlled and secure manner. Power users can only query the data they are allowed to see from a data security perspective.
Another advantage is that this approach enables organizations in security and banking industries to provide a fully auditable and traceable environment that meets the highest security requirements.
Managed Self-Service BI does require a write-back possibility in the enterprise data warehouse architecture, otherwise, it’s just plain old BI solution. Without write-back, there are no differentiators. Beyond that, write-back is necessary in order for enriching or enhancing the quality of the data being put forward. Data scientists, for example, do this all the time: when using Hadoop they create a new target file as a result of their processing output. This is a direct write-back in the Hadoop space. We have required write-back in Self Service BI for years, otherwise, master data, and hierarchy management don’t work properly.
In this modification of the architecture from the previous section, the relational staging area is replaced by a HDFS based staging area which captures all unstructured and structured data. While capturing structured data on the HDFS appears as overhead at first glance, this strategy actually reduces the burden of the source system by making sure that the source data is always being extracted, regardless of any structural changes. The data is then extracted using Apache Drill, Hive External or similar technologies. It is also possible to store the Raw Data Vault and the Business Vault (the structured data in the Data Vault model) on Hive Internal.
Conclusion
Combining Managed Self-Service BI with Data Vault 2.0 empowers organizations to strike a balance between governance and agility in their data ecosystems. By leveraging Data Vault’s structured, auditable architecture alongside self-service BI’s flexibility, businesses can ensure data accuracy, security, and scalability while enabling users to gain faster insights. This approach enables collaboration between IT and business users, driving more informed decision-making and accelerating data-driven innovation.
