Data Vault 2.0 auf Microsoft Azure
In diesem Newsletter erhalten Sie einen Überblick darüber, was Echtzeitverarbeitung ist und welche Möglichkeiten sie für Ihre Data Vault 2.0-Implementierung bietet.
Echtzeitverarbeitung mit Data Vault 2.0 auf Azure
In diesem Webinar erörtern wir die neuen Data-Warehouse-Anforderungen an Daten und gehen auf die Echtzeitverarbeitung (Real-Time Processing) ein. Für einen ersten Überblick behandeln wir verschiedene Architekturen zur Echtzeitverarbeitung. Der zweite Teil konzentriert sich auf die Echtzeit-Datenarchitektur mit Data Vault 2.0 und beinhaltet einen kurzen Überblick über Microsoft Azure. Zudem sehen Sie eine Implementierung der Echtzeitverarbeitung mit Data Vault 2.0 in Azure. Dieses Webinar richtet sich an alle, für die Echtzeitdaten in Data Vault 2.0 neu sind und die an einem Überblick sowie der Implementierung in Azure interessiert sind.
Was Sie erwartet
Sie erfahren, wie Ihnen die Echtzeitverarbeitung ermöglicht, schneller Wert aus Daten zu schöpfen, stets die aktuellsten Daten in Ihren Reporting-Tools zur Verfügung zu haben und präzisere datenbasierte Entscheidungen zu treffen. Dadurch ist Ihr Unternehmen in der Lage, sich schneller an Marktveränderungen anzupassen, indem Entwicklungen anhand neuester Daten sofort sichtbar werden.
Zudem können Sie Kosten sparen, indem Sie sich vom klassischen Batch-Loading verabschieden: Die normalerweise dafür benötigte Spitzenrechenleistung wird reduziert und gleichmäßiger über den Tag verteilt. Dies gilt insbesondere bei der Nutzung von Cloud-Umgebungen, da dort starre beziehungsweise zugesagte Umgebungen ersetzt werden und die benötigte Rechenleistung bedarfsgerecht bereitgestellt werden kann.
Der traditionelle Weg – Batch-Loading
Batch-Loading ist eine traditionelle Methode, um Daten in großen Blöcken (Batches) – meist über Nacht – in ein Data-Warehouse-System zu laden. Die Daten aus den Datenquellen werden bis zu einem bestimmten Zeitpunkt in der Nacht geliefert, um anschließend transformiert und in den Core-Data-Warehouse-Layer geladen zu werden.
Diese Methode führt über Nacht zu einer Spitze (Peak) bei der Datenverarbeitung. Unternehmen müssen ihre Infrastruktur entsprechend auslegen, um diese erwartete maximale Spitze an benötigter Rechenleistung bewältigen zu können.
Der neue Weg – Echtzeitdaten
Echtzeitdaten werden sofort verarbeitet und bereitgestellt, sobald sie entstehen, anstatt über Nacht schubweise geladen zu werden. Bei der Nutzung von Echtzeit-Ansätzen erweitert sich das Ladefenster auf 24 Stunden. Damit entfallen die nächtlichen Lastspitzen und deren Nachteile.
Bei der Nutzung von Echtzeitdaten werden diese stets als Non-Historized Link oder als Satellite modelliert.
Mögliche Anwendungsfälle für Echtzeitdaten sind das Vitaldaten-Monitoring im Gesundheitswesen, die Bestandsverfolgung (Inventory Tracking), das Nutzerverhalten in sozialen Medien oder die Überwachung von Produktionslinien.
Verschiedene Arten von Echtzeitdaten
Es gibt verschiedene Arten von Echtzeitdaten, basierend auf der Ladefrequenz sowie dem Grad der Dringlichkeit beziehungsweise Unmittelbarkeit der Daten.
„Near Real-Time Data“ (nahezu in Echtzeit) bezieht sich auf Daten, die mindestens alle fünfzehn Minuten in Mini-Batches geladen werden, wobei die Daten bis zum Laden in die Datenanalyseplattform in einem Cache gespeichert werden.
Echte Echtzeitdaten („Actual Real-Time Data“), auch Message Streaming genannt, beinhalten das direkte Laden jeder einzelnen Nachricht in die Datenanalyseplattform ohne Cache.
Diese Art von Echtzeitdaten ist nützlich, wenn Daten sofort nach ihrer Erzeugung für Dashboards oder weiterführende Analysen verfügbar sein müssen.
Die akzeptable Verzögerung bei der Verarbeitung von Echtzeitdaten wird in der Regel durch die Konsequenzen eines versäumten Zeitfensters (Deadline) definiert. Zudem gibt es drei Arten von Echtzeitsystemen: Hard Real-Time, Soft Real-Time und Firm Real-Time.

Implementierung der Echtzeitverarbeitung
Wie implementiert man also Echtzeit-Datenverarbeitung in eine Data-Warehouse-Lösung? Es gibt hierfür viele Architekturen, wir werden uns jedoch auf die Lambda- und die Data Vault 2.0-Architektur konzentrieren.
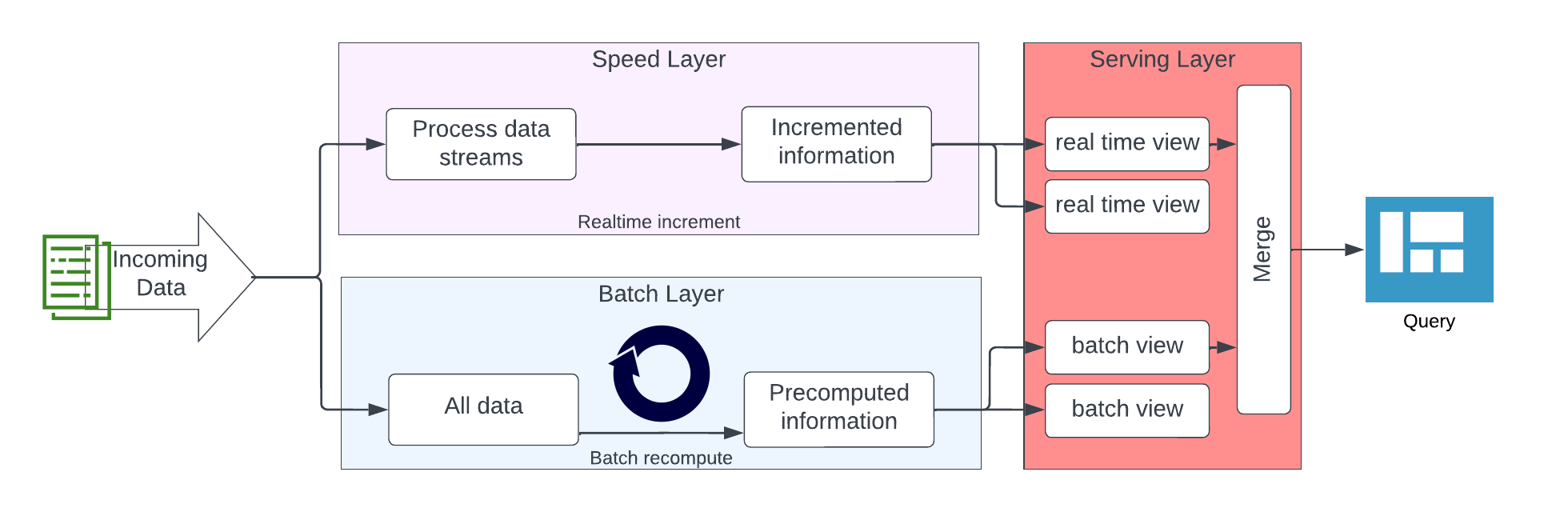
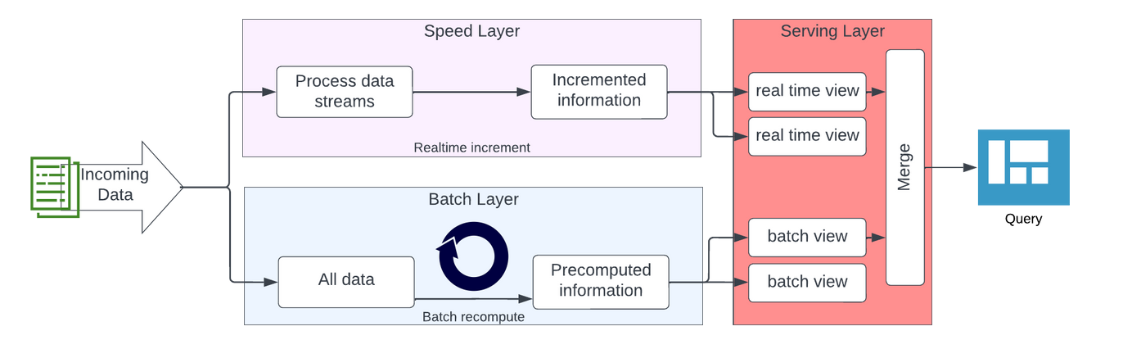
Die Lambda-Architektur unterteilt die Datenverarbeitung in einen Speed Layer und einen Batch Layer. Der Speed Layer verarbeitet Echtzeit-Nachrichten mit Fokus auf Geschwindigkeit und Durchsatz, während der Batch Layer durch die Verarbeitung großer Datenmengen in regelmäßigen Batches Genauigkeit und Vollständigkeit gewährleistet. Der Serving Layer integriert die Daten aus beiden Layern für Präsentationszwecke.
Auf den ersten Blick ähnelt die Data Vault 2.0-Architektur der Lambda-Architektur, behandelt jedoch einige Aspekte anders. Aus der Perspektive von Data Vault 2.0 weist die Lambda-Architektur Schwachstellen auf, wie etwa die Implementierung einer einzelnen Schicht in jedem Datenfluss sowie das Fehlen einer definierten Schicht zur Erfassung unveränderter Rohdaten für Revisionszwecke (Auditing).
Die Data Vault 2.0-Architektur erweitert die bestehende batch-getriebene Architektur um einen Echtzeit-Teil namens „Message Streaming“. Dabei werden mehrere Schichten zur Erfassung und Verarbeitung von Echtzeitdaten implementiert, die an mehreren Punkten mit dem batch-getriebenen Fluss integriert werden. Nachrichten werden vom Publisher downstream zum Subscriber gepusht, in den Raw Data Vault geladen und in den Data Lake abgezweigt. Der Hauptprozess ist jedoch der Push innerhalb des Message-Streaming-Bereichs. Die Architektur ist in der Lage, Daten aus Batch-Feeds zu integrieren oder die Echtzeitdaten direkt in das Dashboard zu streamen.
Nutzung von Microsoft Azure für die Echtzeitverarbeitung
Microsoft Azure ist eine Cloud-Computing-Plattform sowie eine Sammlung von Diensten von Microsoft. Die Plattform bietet eine Vielzahl von Services, darunter virtuelle Maschinen, Datenbanken, Analysen, Speicher und Netzwerke. Diese Dienste können genutzt werden, um Web- und mobile Anwendungen zu erstellen, hochvolumige Datenverarbeitungsaufgaben auszuführen, Daten zu speichern und zu verwalten, Websites zu hosten und vieles mehr.
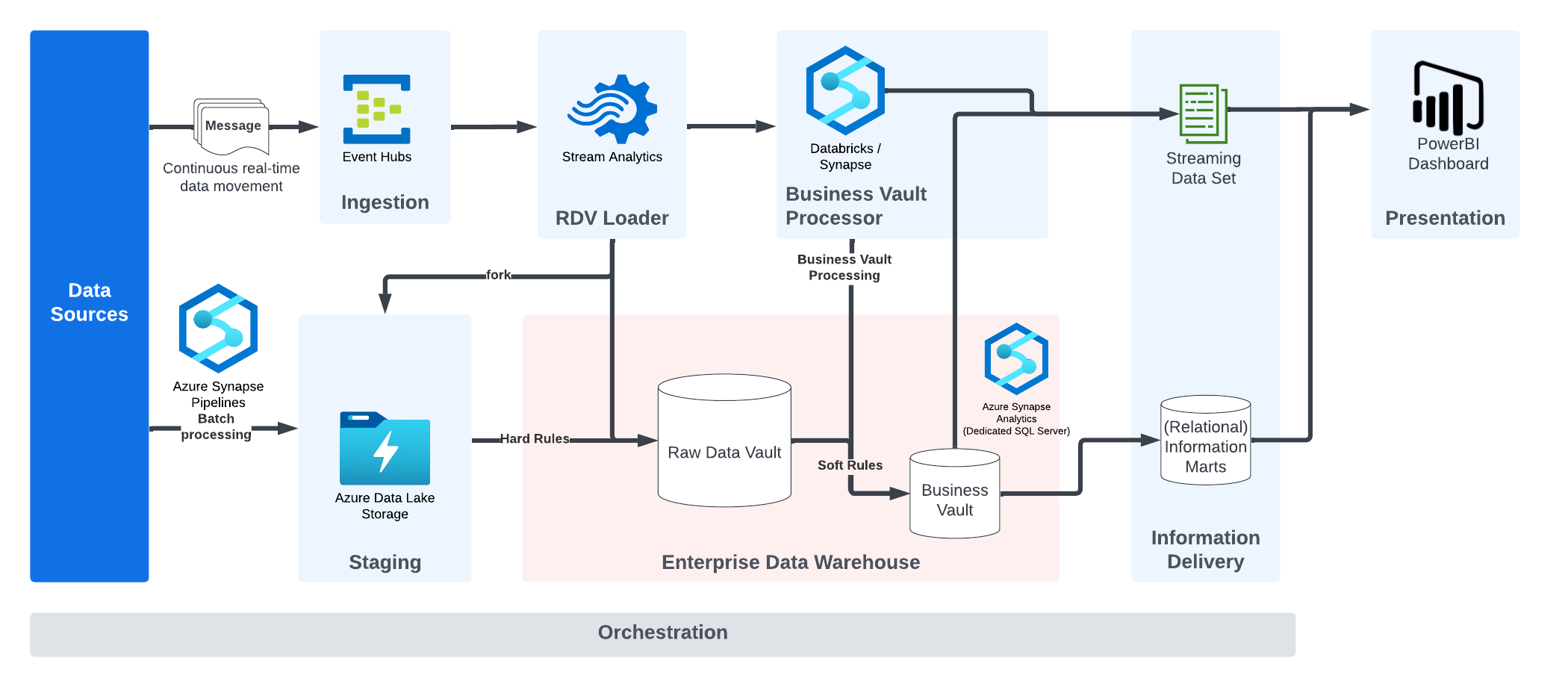
Die Abbildung beschreibt eine typische Echtzeit-Architektur, wie sie von den Beratern von Scalefree verwendet wird und der konzeptionellen Data Vault 2.0-Architektur folgt.
Datenquellen liefern Daten entweder in Batches oder in Echtzeit. Diese werden in den Azure Data Lake geladen oder vorab vom Event Hub entgegengenommen. Der Raw Data Vault Loader trennt Business Keys, Beziehungen (Relationships) und beschreibende Daten (Descriptive Data) mittels Stream Analytics und leitet die Nachricht an den Business Vault Processor weiter. Der Business Vault Processor wendet Transformationen und weitere Geschäftsregeln an, um die Ziel-Nachrichtenstruktur für die Nutzung durch die (Dashboarding-)Anwendung zu erzeugen. Die Ergebnisse können in physische Tabellen im Business Vault auf Synapse geladen oder in Echtzeit ohne weitere Materialisierung in der Datenbank bereitgestellt werden. Die Zielnachricht wird generiert und an den Real-Time Information Mart Layer gesendet, der durch ein Streaming-Dataset implementiert ist und von Power BI genutzt wird.
Der Cache des Dashboard-Dienstes läuft schnell ab, jedoch stehen in der Synapse-Datenbank alle Daten für weitere Verwendungszwecke, einschließlich des strategischen, langfristigen Reportings, zur Verfügung.
Fazit
Zusammenfassend bietet die Echtzeit-Datenverarbeitung zahlreiche Vorteile gegenüber traditionellen Batch-Loading-Methoden. Dazu gehören die Möglichkeit, schneller Wert aus Daten zu generieren, die aktuellsten Informationen in Reporting-Tools bereitzustellen und präzisere Entscheidungen zu treffen. Durch eine schnellere Anpassung an Marktveränderungen können Unternehmen ihren Wettbewerbsvorsprung sichern. Die Abkehr vom Batch-Loading kann zudem Kosten sparen, da Spitzen bei der benötigten Rechenleistung reduziert werden.
Wie bereits erwähnt, zeigt die letzte Abbildung eine Architektur, die von den Scalefree-Beratern implementiert wurde, um Echtzeitdaten zu nutzen.
Lesen Sie mehr dazu in unserem kürzlich veröffentlichten Microsoft-Blogartikel.
Wie sind Ihre aktuellen Erfahrungen mit der Echtzeit-Datenverarbeitung?
Denken Sie darüber nach, Ihr Data Vault durch den Einsatz von Echtzeitdaten auf das nächste Level zu heben?
Oder nutzen Sie diese bereits und möchten sie weiter optimieren?
Teilen Sie uns Ihre Gedanken gerne im Kommentarbereich mit!
