
Multi-Active Satellites in Data Vault 2.0
In our first post about multi-active satellites, we briefly explained different implementations that can be used to solve multi-activity. Now, we’re going to go into more detail regarding the advantages and disadvantages of these approaches having delta checks on or off.
In this article:
Short Summary of Multi-Active Satellites
Multi-active satellites allow you to implement multi-active records per business key in Data Vault 2.0. To illustrate the need for the solution, let’s look at the common occurrence of a source system that doesn’t provide the needed metadata such as when working with XML files.
One solution to the above is to create a multi-active satellite by adding a subsequence number per business key. This accounts for any instance in which there is no multi-active attribute delivered by the source itself. Regarding phone numbers, this information could be a tag for a business, home, or mobile phone number. Another possibility is to create an extra hub for the multi-active attribute. However, since it doesn’t present a real business object, the first solution can be more effective.
Delta Check OFF
There are two ways to insert new records into a multi-active satellite – having delta checks active or inactive. With delta checks turned off, all records of a business key are inserted into the satellite from your source delivery.
The advantage of that is that loads are faster and have a consistent load date timestamp to the parent hash key, independent of the multi-active attribute.
Later on, it simplifies the query based on the multi-active data (see Figure 1). As a critical drawback, the ingested amount of data can increase strongly if full data loads are received.
In this case, you should partition your data by the load date timestamp.
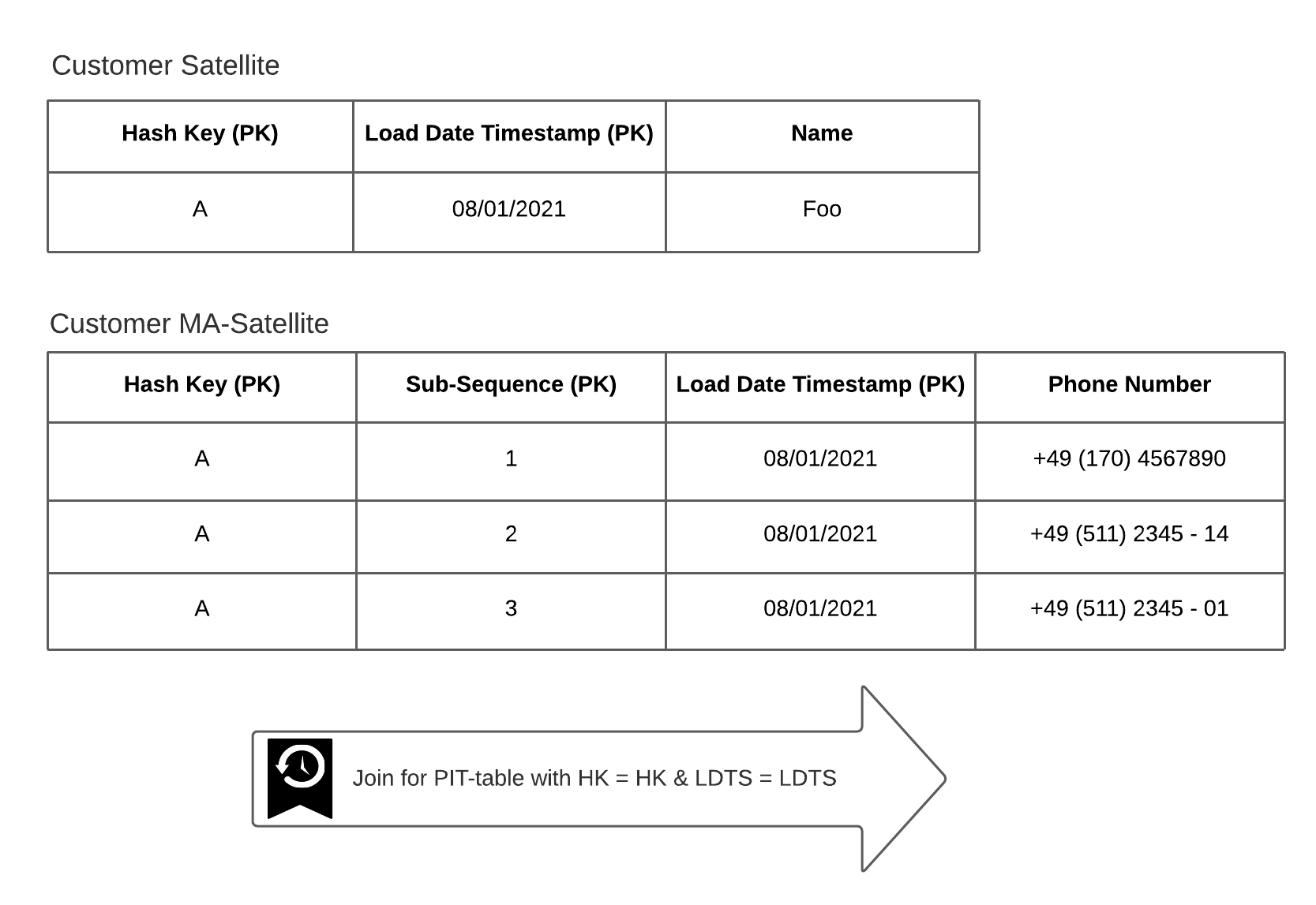
Figure 1: Joining records using one PIT-table when having one LDTS for all active records per key.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Delta Check ON
To reduce the amount of data simply use delta checks. Doing so, you match the incoming data with the latest LDTS per hash key.
Note that a useful function to leverage the delta check is LISTAGG(). This function transforms values from a group of rows into a list of values. As a result, you are able to create a hash difference of multi-active attributes per business key (see figure 2).
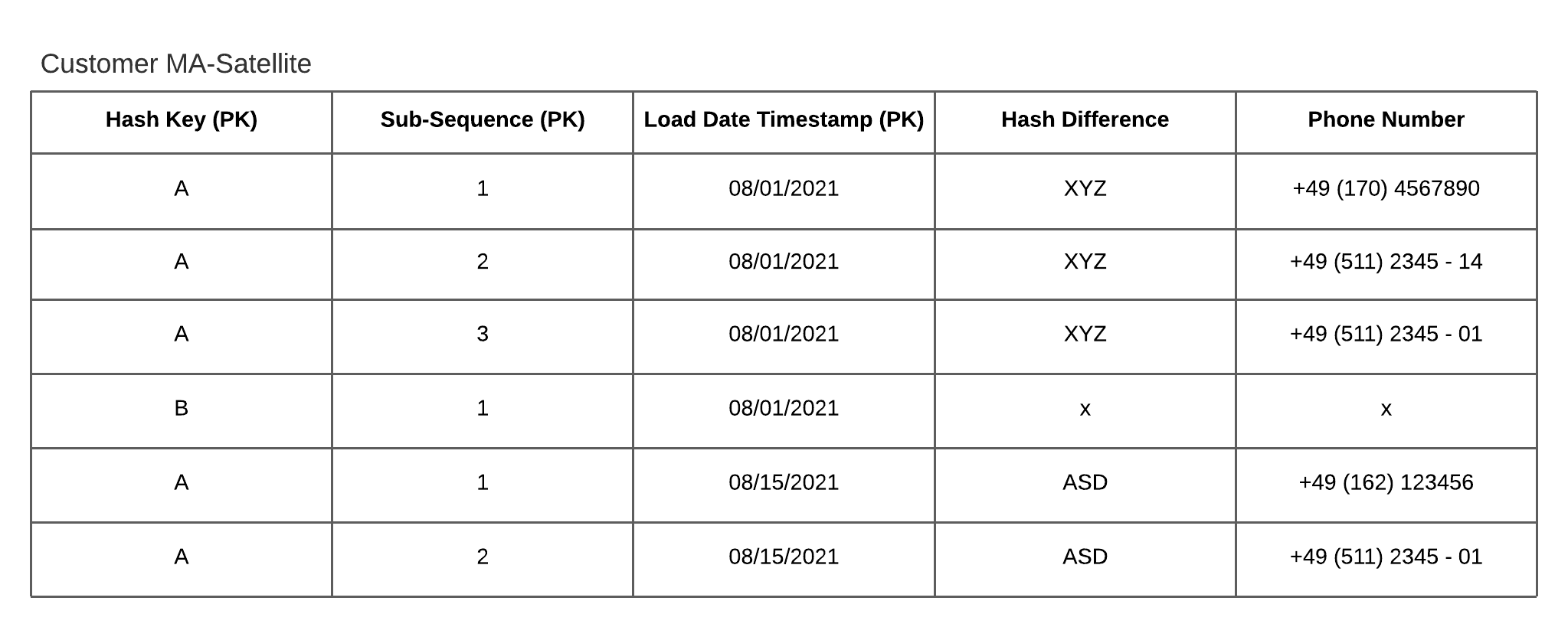
Figure 2 – Multi-row hash difference using the LISTAGG()-function
If new data arrives, it can be compared by the multi-row hash difference. Using it, a high proportion of data can be ignored. When a delta is detected, all records are inserted per hash key even if the content of the data for only one subsequence is changed. The result is that you get a consistent load date timestamp per hash key. Additionally, a delta is going to be noticed when the order of records changes as well. This approach is a trade-off to reduce the amount of records while still having a consistent load date timestamp per hash key so that only one PIT table is necessary.
Using Type Codes
Another method to address multi-activity is to use types of the attributes, granted they exist, as explained in the previous post.
If you have type codes in place, you’re able to compare row by row and load only this specific data. But consequently, you get different LDTS per multi-active attribute. Using PIT-tables in the business vault, you’ll therefore need an extra multi-active PIT-table. This scenario is shown in figure 3.
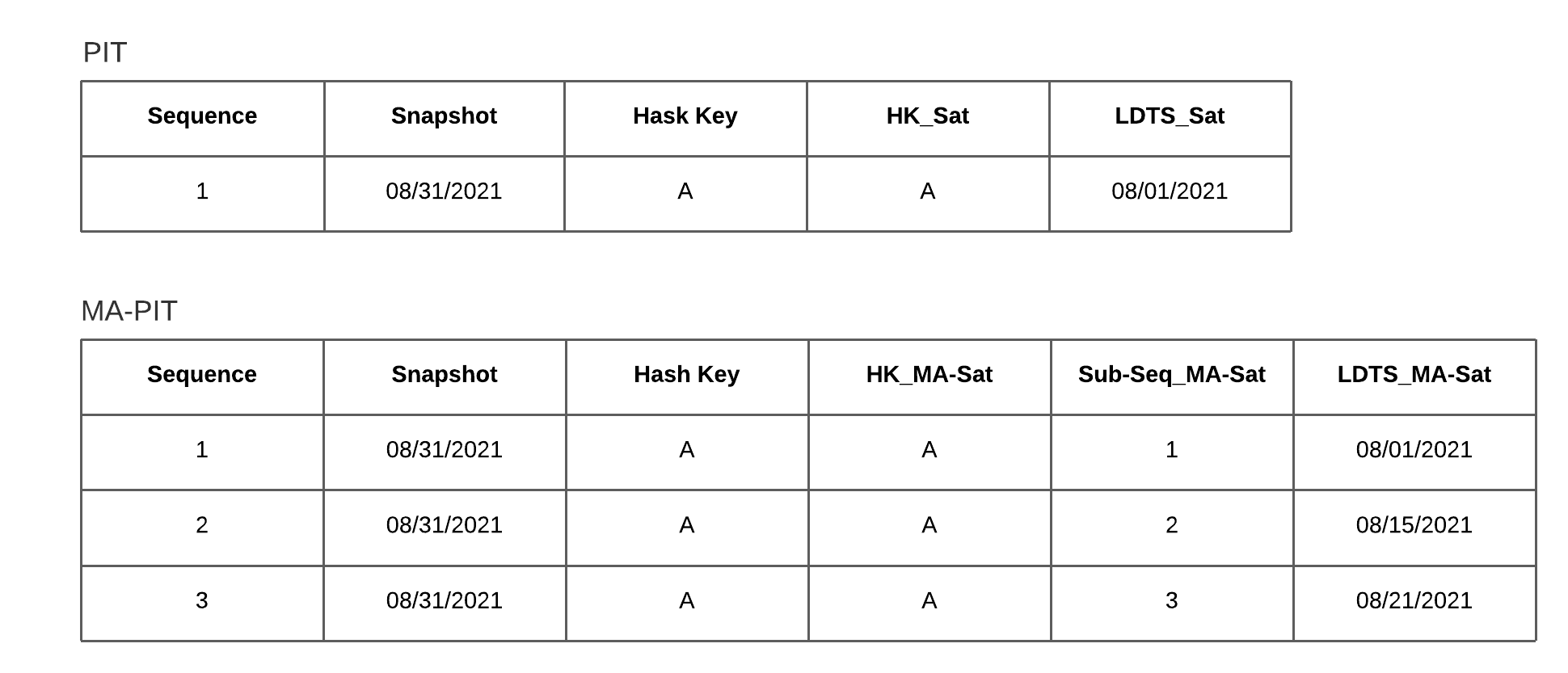
Figure 3 – The need for an MA-PIT having different LDTS of active records per key
If you can pivot the multi-active column into multiple columns, one column per characteristic, you won’t need to consider any of the above advantages or disadvantages. In this case, you turn the satellite into a standard satellite. Related to our example with the phone numbers, you would create a couple of new columns per phone type.
This solution is applicable if you can be certain that the characteristics of the phone types will not change in the future. Otherwise, you will have to reengineer your process to catch all the data you have delivered!
Conclusion
In our second post regarding multi-active satellites, we explored the backgrounds behind the different methods. You can use this information to implement your own multi-active solution depending on your present data.
Though, note that it’s often recommended limiting the loading data. For this purpose, the LISTAGG()-function becomes useful. Using a solution with potentially different LDST, remember to consider them when querying the data.
Hello,
On my actual project, we need to use a multi-active satellite and we checked this article. We are using SQL SERVER where we have the function STRING_AGG, but the fact is, the function accepts only one column. And we have more than 100 columns in the table. So is it possible to add to this article example’s queries to show HOW you use LISTAGG, STRING_AGG or other db functions to calculate your hash diff, because in your example it’s easy, you have just one column with a phone number. How do you manage the case where the number of column could make a concatenation over the max size of a nvarchar for example.
Hi Julien,
If the concatenation for the hashdiff calculation exceeds the maximum possible size you should consider splitting your attributes into multiple (multi-active) satellites (e.g. by splitting by rate of change). Also may not all attributes are multi-active and you could split the descriptive attributes into one or more standard satellites and one multi-active satellite. I would not recommend to put that high amount of columns into a single satellite table.
I hope that helped.
– Ole