How Data Vault Supports AI and ML Readiness
Most organisations today are not failing at AI because they chose the wrong model. They are failing because they built on the wrong foundation. The model is rarely the bottleneck — the data underneath it is.
At Scalefree, working with clients across Europe, we see this consistently: AI workflows will never succeed at scale without proper data support. Not eventually. Always.
This article explains why, and what a mature, AI-ready data architecture actually looks like — with Data Vault 2 at its core.
In this article:
- Where Most Companies Are Right Now
- Reasons That Stop Companies From Scaling with AI
- Why AI Workflows Fail Without a Data Foundation
- The Enabling Data Platform: What It Looks Like
- How This Architecture Directly Solves the AI Scaling Problem
- Data Vault 2 as the Foundation for AI Readiness
- Starting the Journey: Three Things to Do in Parallel
- Want to Go Deeper?
Where Most Companies Are Right Now
The journey most organisations follow with AI looks roughly the same. It starts with discovery — the first time someone opens a chatbot, enters a prompt, and gets a result that genuinely surprises them. That moment creates momentum.
What follows is an extended period of experimentation. Prototypes are built. Some use cases work. Others fail — not because AI is incapable, but because the setup was wrong, or the use case was not worth the complexity it introduced. This phase is characterised by learning, and by a growing realisation that surfaces quickly: the same problems data engineers have been solving for 20 or 30 years have not gone away. They have simply reappeared under a new name.
Structured processes are needed. Governance is needed. Data integration is needed. The foundation matters — and for many organisations, that foundation is not ready.
The companies that move beyond experimentation into genuine AI maturity are not the ones that found a better model. They are the ones who built a better platform first.
Reasons That Stop Companies From Scaling with AI
Two patterns emerge consistently when AI projects reach the limits of their initial setup.
The first starts innocently. A workflow tool is connected to a data source and a language model. It works. Results are impressive. Then a second data source is added, then a third. A quality control step is introduced. A loop is needed. A second agent handles edge cases. What started as a clean prototype becomes a tangled, fragile system that is expensive to maintain and nearly impossible to debug. When errors appear — and they will — fixing them means untangling months of accumulated complexity. Multiply this across ten, twenty, or forty processes in an organisation, and the maintenance burden alone consumes any efficiency the AI was supposed to create.
The second pattern emerges from urgency. Business users want to move quickly, and internal IT is often a bottleneck. The response is shadow AI: tools adopted outside governance controls, company data uploaded to external platforms without authorisation, processes built that bypass audit trails, GDPR compliance, and data ownership rules. It produces results fast. It also creates legal exposure, data leakage risk, and a complete loss of organisational visibility into what AI is actually doing with company data. For many organisations today, if asked honestly what AI processes are running and what data they are using, the honest answer is: we do not know.
Both patterns are understandable in how they start. Both become critical problems at scale.
Why AI Workflows Fail Without a Data Foundation
The root cause in both cases is the same: attempting to solve data problems inside an AI workflow rather than before it.
When an AI agent needs to access 20 different types of information — personal contact data, past purchase history, product catalogue, past email correspondence, website behaviour, and company context — and that data lives in disconnected source systems with no integration layer, every new data point added to the workflow increases complexity. Quality issues compound. Costs rise with every additional token consumed. And because AI systems produce different results every time they process inconsistent input, errors are unpredictable and difficult to reproduce.
Clean, integrated, well-described data does not make AI smarter in a general sense. It makes AI consistently useful — which is what actually matters when deploying at enterprise scale.
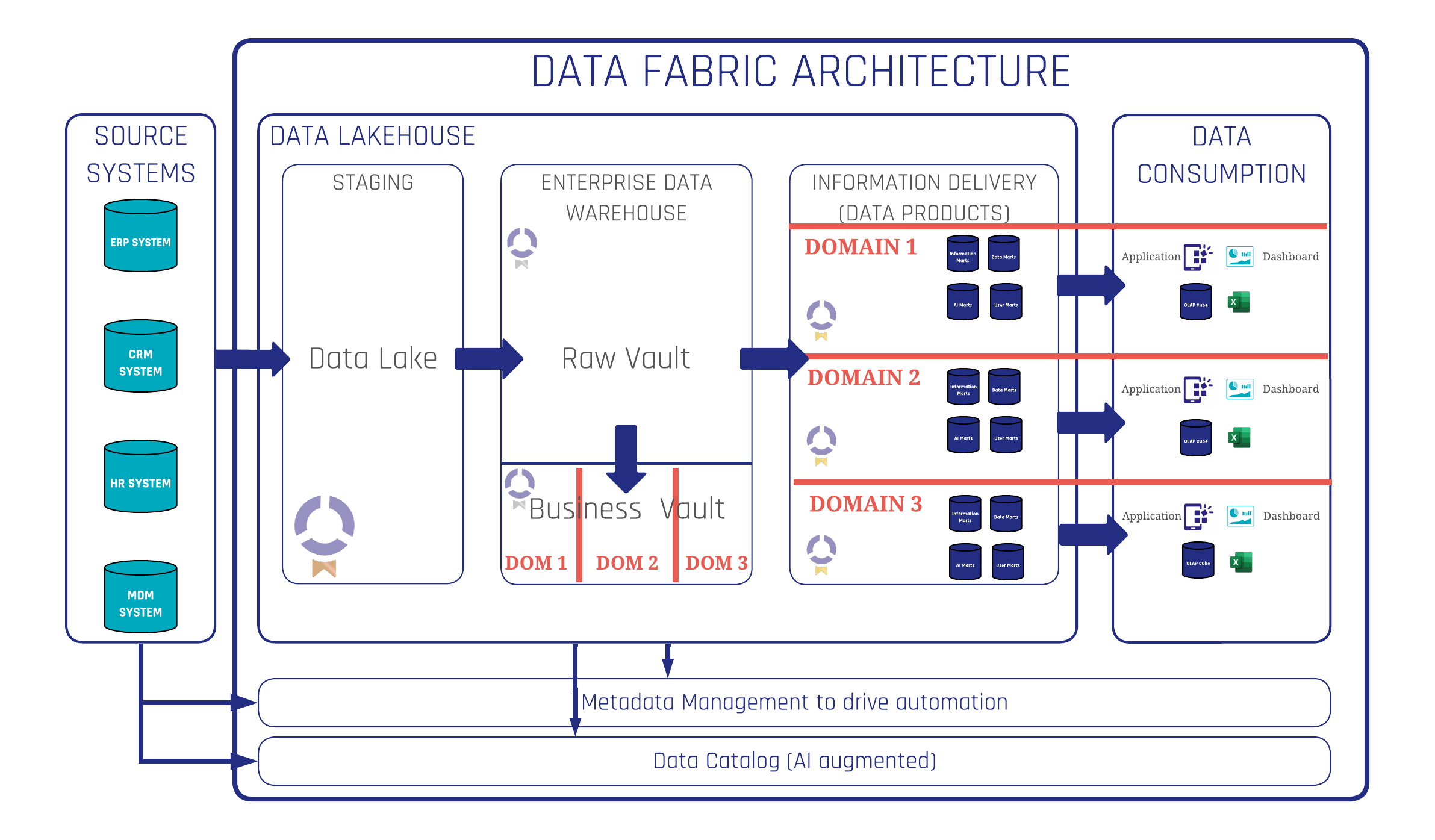
The Enabling Data Platform: What It Looks Like
The architecture Scalefree recommends for AI-ready data platforms follows a clear logical structure, regardless of which specific tools an organisation uses.
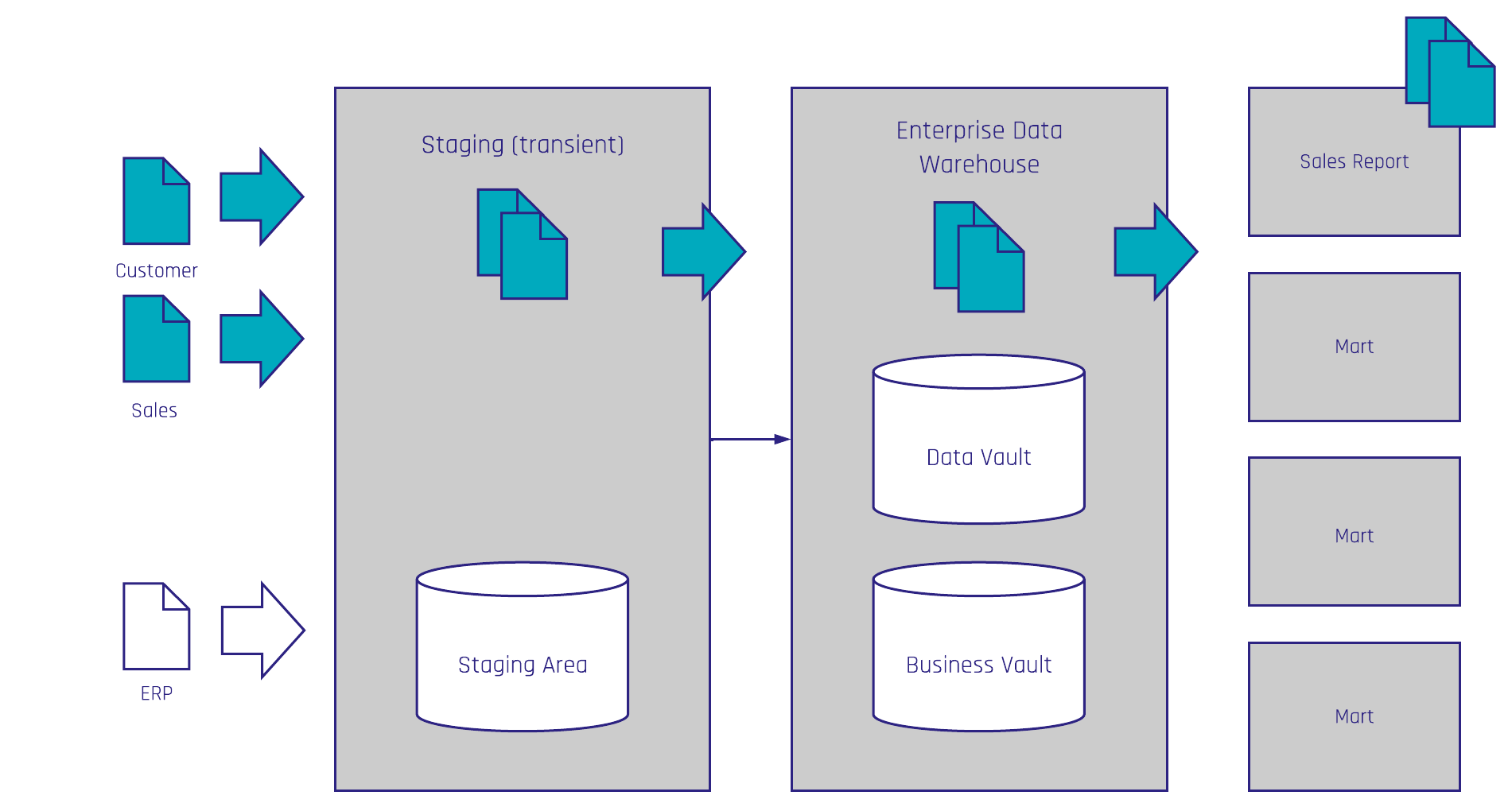
Source systems feed into a Persistent Staging Area, where raw data is collected and preserved as-is. This is not a transformation layer — it is a historical record of everything that arrived, in the form it arrived in.
From there, data moves into an integration layer. This is where a Data Vault 2 modeling standard sits. The role of this layer is to integrate data from different source systems, resolve business key conflicts, clean data, and build a single, auditable, historically complete view of the business. It can grow and evolve as new sources are added, without restructuring what already exists. It is also built piece by piece, use case by use case, which means an organisation does not need to build the entire platform before deriving value from it.
Above that, the platform builds Feature Marts. Feature Marts are the direct interface between the data platform and AI agents. They are optimised for AI consumption — sometimes flat and wide, sometimes in a dimensional modeling style, with rich semantic descriptions that help an AI agent understand not just what the data is, but what it means. A Feature Mart might contain all prospect activity data in a single unified view, ready for an agent to consume without having to navigate joins, resolve conflicts, or interpret raw table structures.
AI agents plug into Feature Marts. They do not go directly to the predecessor layers, and they certainly do not go directly to source systems. The Feature Mart is the clean, governed, role-restricted interface that makes agents reliable.
How This Architecture Directly Solves the AI Scaling Problem
Security and access control. When an AI agent connects to a Feature Mart rather than a raw database, access can be scoped precisely. The agent sees only the data it needs for its specific function. If the agent is compromised, the blast radius is limited. This is the same principle applied to any employee or system — give it exactly the access it needs, nothing more.
Data integration. An organisation’s data engineers have already done the work of cleaning, integrating, and resolving data quality issues across source systems. AI engineers do not need to rebuild this. They need to collaborate with data engineers to shape Feature Marts from data assets that already exist. This is a fundamental shift in how AI teams and data teams should work together — and it accelerates the time from idea to deployed AI use cases.
Full audit trail. With a proper data platform, every piece of data that flows into an AI decision can be traced back to its source, with a timestamp. The output can also be stored back in the platform. This means that when a compliance question arises — which data informed this decision, on which date, processed by which agent — the answer is available.
GDPR and compliance. If data deletion rules are already implemented in the platform, they extend automatically to AI agents. Data that has been deleted from the platform under GDPR rules will not be served to an AI agent via the Feature Mart. Compliance is inherited, not rebuilt for each use case.
Cost control. Providing an agent with a clean, pre-integrated Feature Mart means it processes the right data once, rather than consuming tokens navigating raw, inconsistent, or duplicated data sources. Token costs are a real and growing concern for organisations running AI at scale. A well-structured data foundation is also a cost optimisation strategy.
Semantic layers. AI agents make mistakes when they do not understand the data they are working with. A data catalog and semantic layer that provides meaningful descriptions of every data asset — what a field means, how a metric is calculated, what business context surrounds a particular entity — reduces AI hallucinations significantly. This is especially important as organisations move toward conversational interfaces that allow business users to query data in natural language.
Data Vault 2 as the Foundation for AI Readiness
Data Vault 2 is not simply a modeling technique. It is a complete methodology covering architecture, modeling, and implementation standards. Its particular strengths make it well-suited as the integration layer in an AI-ready platform.
The insert-only, historically complete nature of Data Vault means that every version of every piece of data is preserved. An AI agent working with a Feature Mart derived from a Data Vault has access to the full history of a business entity — not just its current state. This matters significantly for ML models that rely on historical patterns, and for audit requirements that demand a complete record of what was known at any point in time.
Data Vault’s business-key-centred approach means that data from multiple source systems can be integrated without losing the original context of each source. An AI agent drawing on customer data that has been properly integrated through a Data Vault model is working with a single, coherent view of that customer across every system in the organisation — rather than multiple conflicting records from disconnected databases.
Data Vault 2 also extends the original methodology to address real-time and semi-structured data patterns — JSON structures, streaming sources, event-driven loading — which are precisely the data types that AI-driven workflows increasingly depend on.
Starting the Journey: Three Things to Do in Parallel
Organisations do not need a complete data platform before they begin building AI use cases. What they need is a plan to build both in parallel, with the right teams working together.
The first priority is extending the existing data platform to serve AI applications — identifying which data assets already exist, which Feature Marts can be built from them quickly, and which source systems need to be connected next.
The second priority is identifying the right processes to automate. The most valuable targets are not tasks unique to one person, but processes that many people across the organisation perform repeatedly — the same steps, executed at scale, across departments. These are the processes where AI creates compounding returns.
The third priority is building cross-functional teams. AI engineers, data engineers, and business users need to work together from the start. Business users understand the processes. Data engineers have already solved the data integration and quality problems. AI engineers know which models fit which constraints and how to optimise for cost and performance. No single group has all three — and organisations that try to run AI projects without all three perspectives will hit the limits of that approach quickly.
Want to Go Deeper?
If your organisation is evaluating its data platform readiness for AI, or if you are already building AI workflows and hitting the limitations described in this article, Scalefree offers a free Data Vault Handbook — 60 pages covering the fundamentals of Data Vault and where it fits in a modern data architecture. Available to order to your door, free of charge within Europe.
For teams ready to take the next step, the Data Vault 2.1 Training & Certification equips data engineers and architects with the methodology, modeling skills, and CDVP2.1 credential to build and govern Data Vault implementations at enterprise scale.
To discuss how Scalefree can support your data platform or AI readiness journey, get in touch directly.