Data Vault and Data Mesh
Few topics generate more confusion in enterprise data architecture than the relationship between Data Vault, Data Mesh, and Data Fabric. Online discussions often frame these as competing approaches — as if an organisation must choose one and abandon the others. This framing is wrong, and understanding why matters for anyone building a serious data platform in 2025 and beyond.
These three concepts operate at different levels. They address different problems. And when combined correctly, they complement each other in ways that none of them can achieve alone.
In this article:
Data Vault, Data Mesh, and Data Fabric Are Not Competing
The confusion starts because all three terms appear in similar conversations — data platform architecture, enterprise data strategy, scalability. But they are not alternatives to each other.
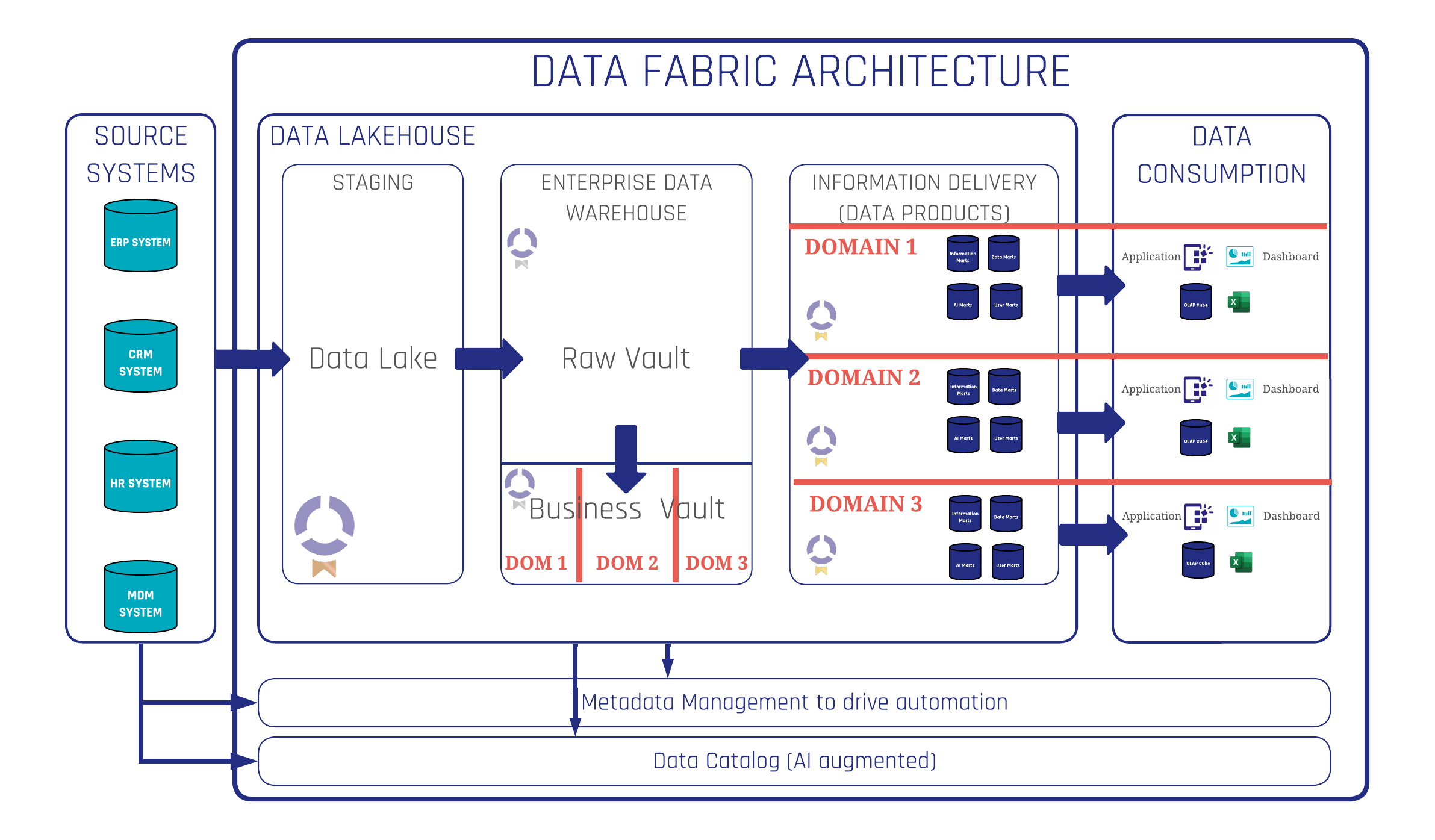
Data Fabric is a technical approach. It defines the architecture of a data platform — how data moves from source systems through integration layers to delivery, how metadata drives automation, how access is governed, and how the platform scales. It is the engineering blueprint.
Data Mesh is an organisational approach. It defines who is responsible for data, how teams are structured, how data products are owned and maintained, and how to avoid the bottlenecks that emerge when a single central IT team is responsible for everything. It is the operating model.
Data Vault is the methodology that sits between the two. It provides the modeling technique, the reference architecture, the implementation standards, and the agile delivery framework that make both a high-quality Data Fabric and a functional Data Mesh possible. It is the glue.
None of these replaces the other. An organisation can have a Data Fabric architecture without Data Vault — but it will lack the standardisation and automation that make the platform scalable. It can adopt Data Mesh principles without Data Vault — but the integration layer will be fragile and inconsistent. Data Vault without a clear architectural vision and organisational operating model delivers solid modeling but leaves the surrounding platform undefined. For a deeper look at how these three approaches fit together architecturally, Scalefree’s guide on Data Vault, Data Mesh, and Data Fabric covers the full modern architecture picture.
Why Data Vault Is the Foundation Data Mesh Needs
Data Mesh’s central argument is that centralised IT teams become bottlenecks as data platform requirements grow. The solution is to distribute ownership — giving domain teams (sales, finance, operations, logistics) responsibility for their own data products rather than routing every requirement through a central team.
This is a sound organisational idea. But it creates a serious technical problem: if every domain team builds its own data pipelines from scratch, organisations end up with redundant data, conflicting definitions of the same business objects, and a proliferation of unmaintained pipelines. The very inefficiency Data Mesh was designed to solve reappears in a different form.
Data Vault solves this problem at the architecture level. The key insight is that not all layers of a data platform benefit equally from decentralisation.
The Raw Data Vault — the layer that absorbs raw data from source systems and integrates it using business keys — should remain centralised. This layer contains no business logic. It simply records what arrived, when, and from where. Because it is standardised and highly automatable, a small central team can maintain it with minimal overhead. And because it is centralised, every domain team draws from the same single source of facts — the same customer records, the same product data, the same account structures — rather than each team pulling its own version from disconnected pipelines.
The Business Vault and Information Marts, by contrast, are exactly where domain knowledge matters. Business rules, calculated metrics, KPI definitions, and data product shaping all require the kind of deep domain understanding that lives in business teams, not in central IT. This is where decentralisation makes sense — and where Data Mesh principles directly apply.
The result is a practical middle ground: centralise the Raw Vault where standardisation creates efficiency, decentralise the Business Vault and Information Marts where domain knowledge creates value. This is not a theoretical compromise — it is the architecture that enterprise Data Vault implementations demonstrate works at scale.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
The Problem With Going “Full Data Mesh”
Fully decentralised Data Mesh — where every domain team manages its own data end to end, from source ingestion to delivery — sounds attractive in theory. In practice, it replicates the problems of the pre-data-warehouse era, where every department ran its own shadow IT, built its own pipelines, and maintained its own version of business objects that nobody else could join reliably.
When domain teams each ingest their own version of a source system, the same Salesforce data gets pulled ten times by ten different teams with ten slightly different transformation approaches. The same customer appears as ten different records with ten different definitions of “active.” Joining across domains becomes a project in itself. The governance that Data Mesh promises — through federated standards and data contracts — is extremely difficult to enforce when no shared foundation exists.
Full centralisation has its own problems, of course. A single IT team responsible for all data products across a large organisation will always struggle with prioritisation, domain knowledge gaps, and delivery speed. The bottleneck that Data Mesh identifies is real.
The architecture that resolves this tension uses Data Vault’s layered structure as the boundary between centralised and decentralised work. Central team: source ingestion, Raw Vault, automation infrastructure, platform governance. Domain teams: Business Vault logic, Information Marts, data product definition, and ownership.
How This Architecture Works in Practice
Organisations that implement this combined approach typically follow an evolution rather than a big-bang restructuring. Teams begin working together on a centralised platform, building the Raw Vault and establishing the automation patterns and tooling. As the platform matures and team members develop deep platform knowledge, those people move into domain teams — bringing their technical expertise with them, closer to the business knowledge that domain work requires.
The central team shrinks to a small core — often just two or three people — responsible for maintaining the Raw Vault, the automation infrastructure, and the platform governance layer. Domain teams handle everything from the Business Vault outward, working with full autonomy on their data products while drawing on the shared, integrated foundation beneath them.
This approach has a specific advantage when organisations grow through acquisition. When a company absorbs another — bringing new source systems, new customer records, new business objects — the Raw Vault absorbs the new data without restructuring what already exists. New Hubs, new Satellites, and new integration logic are added incrementally. Existing data products continue to function. The integration project that would take a traditional data warehouse months or years can be completed in weeks.
The same scalability applies to organic growth. New business units, new products, new markets — each can be onboarded as a new domain team, drawing from existing Raw Vault entities where overlap exists, adding new entities where it does not. The platform grows with the organisation rather than requiring periodic rebuilds.
What Makes This Combination Work
Three characteristics of Data Vault make it particularly well suited as the foundation for a Data Fabric and Data Mesh architecture.
Standardisation enables automation. Data Vault’s Hub-Link-Satellite structure is highly consistent. Once the patterns are established and the metadata is defined, the loading of Raw Vault entities can be generated automatically rather than hand-coded. This is precisely what Data Fabric requires — and precisely what makes the central layer maintainable by a small team even as the number of source systems grows. For a detailed look at how datavault4dbt implements this automation approach, Scalefree’s tooling is specifically designed around this principle.
Historical completeness supports data products. Data Mesh’s concept of the data product — a trusted, documented, governed dataset that domain teams can consume and build upon — requires a reliable foundation. A data product built on a Raw Vault entity inherits complete historical data, a full audit trail, and provable lineage back to source. These are the properties that make data products trustworthy enough to use in downstream analytics, AI applications, and regulatory reporting.
The layered architecture maps naturally to organisational boundaries. Raw Vault and Business Vault are not just technical distinctions — they correspond to a meaningful organisational divide between technical data engineering work and business knowledge work. The architecture makes the organisational model explicit rather than leaving it implicit, which reduces friction when defining team responsibilities and data product ownership.
The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Data Catalogs and Governance as Connective Tissue
A combined Data Vault, Data Mesh, and Data Fabric architecture only delivers its full value when metadata is managed seriously. Domain teams need to be able to discover what data products already exist, understand their lineage, know how fresh the data is, and assess whether an existing product meets their needs before building a new one.
Without a well-maintained data catalog, teams rebuild work that already exists, queries return answers that conflict with other answers, and the governance that Data Mesh requires to function collapses into informal agreements and institutional knowledge held by a few individuals.
With a proper catalog — one where every data product is documented, every entity has clear ownership, every metric definition is visible, and lineage traces from source to delivery — the platform becomes genuinely self-service. Non-technical users can find and use data products without IT support. AI use cases that require querying data in natural language become feasible. And the platform can scale to serve a large organisation without proportional growth in support overhead.
Data Vault contributes directly to catalog quality. The Raw Vault’s record source and load date on every entity provide automatic lineage. The standardised naming conventions make entities discoverable. The separation of Raw Vault from Business Vault makes the application of business rules explicit and auditable rather than buried in opaque transformation logic.
Starting the Journey
For organisations considering this architectural direction, the starting point is almost always the same: begin with the data platform foundation before attempting to distribute ownership. Teams need to understand the platform — how the Raw Vault works, how automation is configured, how the Business Vault extends the raw layer — before they can work effectively within domain structures.
The Data Vault 2.1 Training & Certification equips data engineers and architects with the complete methodology — from Raw Vault design through Business Vault patterns to Information Mart delivery — so they can build and govern this kind of platform with confidence. For teams evaluating their current architecture and planning the move toward a more scalable and governed platform, Scalefree’s Data Platform Review provides an expert assessment and a clear recommended path forward.
The question is not whether to choose Data Vault, Data Mesh, or Data Fabric. The question is how to combine them in the sequence and proportion that fits your organisation’s current maturity and growth trajectory. The answer, in almost every case, starts with the same foundation: a clean, standardised, automated Raw Vault that every domain team can trust.
For further reading on how Scalefree approaches enterprise data platform architecture, the free Data Vault Handbook covers the core methodology, and the Data Vault consulting practice works with organisations at every stage of the implementation journey.