Business Use Cases in Data Vault
In the world of data management and integration, businesses face many challenges. Data Vault is a methodology designed to address these challenges, offering a flexible and scalable solution for integrating and managing data across an enterprise. But when is it the right time to use Data Vault? Are there specific business scenarios where Data Vault’s power truly shines? This article explores the core benefits of Data Vault, its use cases, and how it can solve complex data integration problems.
Understanding the Pain Points
Before diving into when and where Data Vault is most beneficial, it’s important to understand the underlying pain points businesses face in their data management processes. According to Michael Olschimke, CEO of Scalefree, understanding the business pain points is crucial. If there is no significant problem, there may be no need for a new solution like Data Vault. The key is identifying situations where current methods fall short in handling data integration, privacy regulations, and evolving business rules.
The most common pain point is the challenge of data integration. Modern businesses typically operate with data spread across multiple sources, from internal systems to external data feeds. Integrating these data sources into a single, unified view is one of the biggest challenges. Whether you’re trying to generate reports, create dashboards, or analyze data for business insights, you need a consistent and reliable method to integrate data from diverse systems. This is where Data Vault excels.
The Core Strength of Data Vault: Data Integration
Data Vault is designed specifically for situations where integration is a priority. If a business needs to bring together multiple disparate data sources into a single framework for reporting, Data Vault offers a robust solution. Its flexibility allows businesses to combine data from different systems, apply various business logic, and present the data in a meaningful way.
In contrast to other methods, Data Vault shines when the data integration needs are complex. Simply dumping data into a data lake may seem like an easy solution, but it leaves businesses with the challenge of how to integrate these disparate datasets into a cohesive model. Without a clear method for integration, data lakes become isolated silos of information, and producing integrated reports becomes a significant challenge.
Addressing Regulatory Compliance and Privacy
In today’s data-driven world, businesses must also address regulatory requirements such as GDPR. One of the strengths of Data Vault is its built-in support for privacy and security regulations. When managing sensitive data, businesses need to ensure compliance with privacy regulations, including the ability to delete or anonymize personal data when necessary.
While other methods can also address regulatory concerns, Data Vault provides out-of-the-box patterns and solutions that are easy to implement and scale. For example, Data Vault allows businesses to securely store data, apply business rules, and remove or anonymize personal attributes without disrupting the overall data structure. This capability is crucial in today’s regulatory environment, where compliance is not just a best practice but a legal requirement.
Handling Changing Business Rules Over Time
Another key use case for Data Vault arises when businesses face changing business rules. Over time, companies evolve, and with this evolution comes changes in how data is processed and interpreted. For example, a business might need to apply different versions of a business rule to historical and current data, depending on when the rule was in effect.
Data Vault provides a solution to this challenge by separating the data transformation processes and storing them in the “business vault.” This separation allows businesses to apply different versions of business rules to different datasets. For instance, you might apply one rule to data from the previous year and a different rule to the current year’s data. This flexibility allows companies to adapt to new business requirements without overhauling their data architecture every time the rules change.
Scalability and Flexibility
As businesses grow and their data needs become more complex, the scalability of their data management solutions becomes critical. Data Vault is highly scalable because it allows companies to add new data sources, apply new business rules, and adjust their data models as needed without requiring a complete redesign of their data infrastructure.
One of the most powerful features of Data Vault is its ability to “creatively destruct” incoming data. This means that data from different source systems can be broken down into fundamental components—such as business keys, relationships, and descriptive data. These components can then be recombined in any format or structure that suits the business’s reporting or analytical needs, whether that’s a star schema, flat tables, or any other target structure. This flexibility ensures that businesses can meet various use cases and reporting requirements using the same data platform.
Data Vault and Business Intelligence
In the realm of business intelligence (BI), Data Vault stands out as an effective method for managing large, complex datasets. It offers businesses the ability to handle multiple use cases, such as generating reports, analyzing trends, and forecasting future performance. Because it integrates data from multiple sources, it provides a single, reliable source of truth for reporting and analysis.
Unlike traditional BI systems, which often require multiple data platforms or complex ETL (extract, transform, load) processes, Data Vault allows businesses to use a single platform for all their BI needs. Whether you’re running operational reports, building data marts, or creating advanced analytics models, Data Vault’s flexibility ensures that businesses can handle various BI scenarios without the need for separate systems or tools.
Addressing Complex Data Models
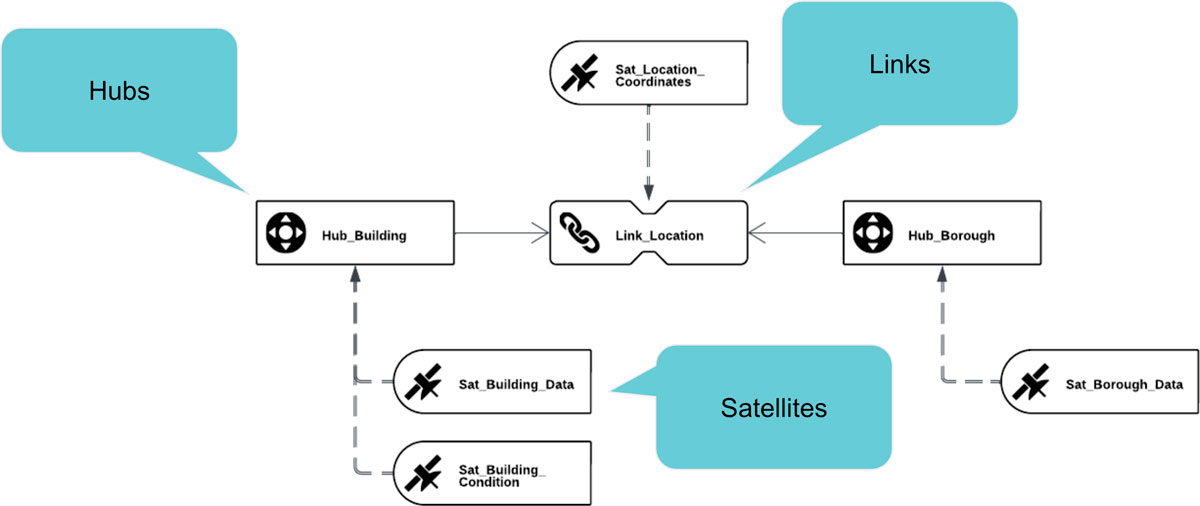
While Data Vault is highly flexible, it can also become more complex as businesses face increasingly complex data models. The complexity arises when businesses deal with dirty data, unclear business key definitions, or overlapping data from different source systems. In these situations, Data Vault allows companies to address these challenges by adding new components to their data models, such as hubs, links, and satellites.
For instance, if a business has two different source systems with different business key definitions, Data Vault can create a new hub to store these keys and establish relationships between them. Similarly, when data quality is an issue, Data Vault allows businesses to add computed satellites to clean the data before it’s used for reporting or analysis. While these additional components can increase the complexity of the data model, they are essential for solving the challenges presented by messy, inconsistent, or incomplete data.
When Should You Use Data Vault?
Ultimately, the decision to use Data Vault depends on your business’s data requirements. If your data integration needs are relatively simple, or if you don’t have stringent privacy or regulatory requirements, other solutions might suffice. However, for businesses dealing with complex datasets, evolving business rules, and compliance challenges, Data Vault provides a comprehensive, scalable solution that addresses all these needs.
When evaluating whether Data Vault is the right choice for your organization, it’s essential to assess your current and future data needs. If you require robust data integration, the ability to apply different business rules over time, and compliance with privacy regulations, Data Vault is a powerful tool that can handle these challenges. Its flexibility and scalability ensure that it can grow with your business as your data needs evolve.
Conclusion
Data Vault is a powerful methodology for businesses that need to integrate complex data from multiple sources, apply evolving business rules, and comply with privacy regulations. While it may not be necessary for every business, for those facing challenges in these areas, Data Vault offers a robust, flexible, and scalable solution. By breaking down and restructuring data in a way that supports various reporting and analytical needs, Data Vault ensures businesses can keep up with the ever-changing demands of today’s data-driven world.