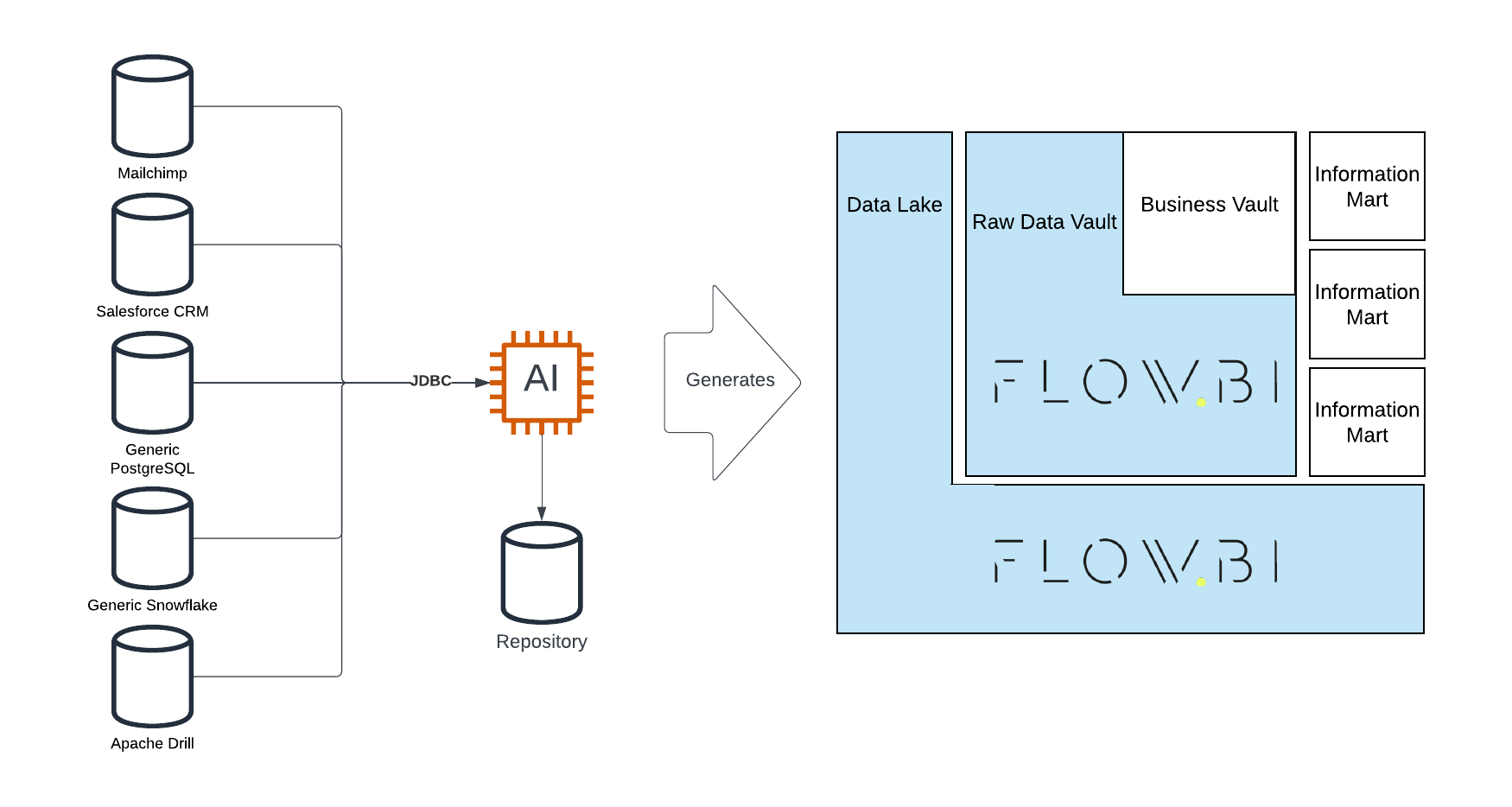
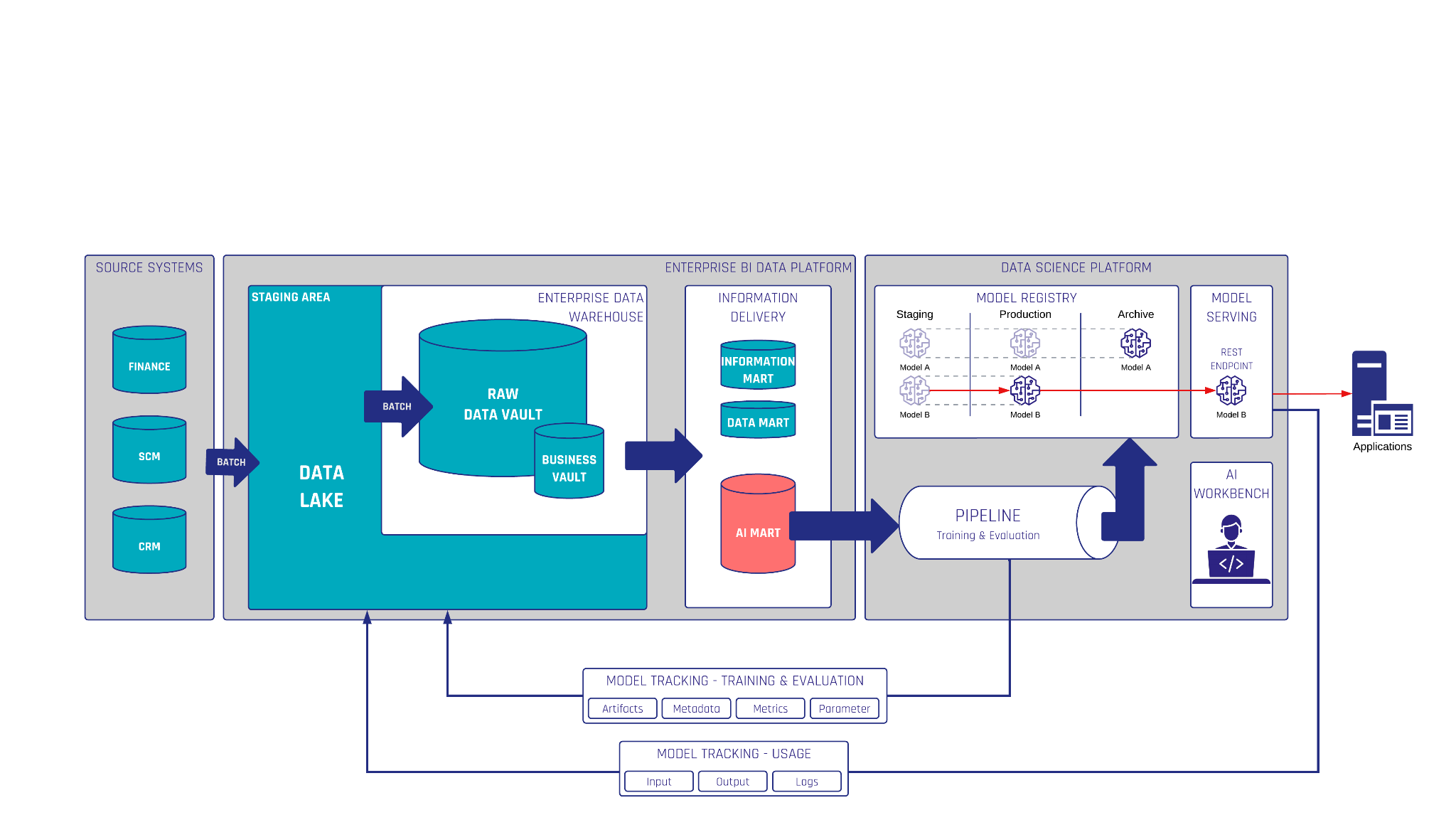
Data Vault Stages
The Data Vault methodology provides a robust framework for managing and organizing enterprise data. One of the foundational components of a Data Vault is the stage. In this guide, we’ll explore what Data Vault stages are, their importance, and how to create them effectively.
In this article:
Understanding Node Types in Data Vault
Before diving into stages, let’s review the key node types in a Data Vault:
- Stages: Temporary storage areas where raw data is preprocessed.
- Hubs: Central entities containing unique business keys.
- Links: Relationships between hubs.
- Satellites: Contextual and descriptive data for hubs and links.
- PITs (Point-in-Time Tables): Optimized query performance tools.
- Snapshot Tables: Historical states of data.
- Non-Historized Links & Satellites: Used when historical tracking isn’t required.
- Multi-Active Satellites: Support multiple active records for the same key.
- Record Tracking Satellites: Track changes and versions of records.
Features of Data Vault Patterns
The Data Vault methodology leverages years of practical experience to deliver several key features:
- Patterns Based on Expertise: Proven methods for efficient loading and processing.
- Multi-Batch Processing: Handle multiple data batches simultaneously.
- Automatic PIT Cleanup: Uses logarithmic snapshot logic for optimal performance.
- Virtual Load End-Date: Allows insert-only processes by using calculated end dates.
- Automated Ghost Records: Simplifies handling of missing or incomplete data.
Why Are Stages Important in Data Vault?
Stages play a critical role in the Data Vault architecture by enabling efficient data preparation and ensuring data integrity. Key benefits include:
- Hash Keys & Hash Diffs: Ensures unique identifiers for data integration and deduplication.
- Load Date & Record Source: Tracks the origin and timing of data entries.
- Prejoins: Combines data efficiently before entering the vault.
- Hard Rules: Implements strict validation and transformation logic.
How to Create a Data Vault Stage
Creating a stage in a Data Vault involves leveraging the right tools and techniques. For this, we recommend using Datavault4Coalesce, a powerful platform designed for Data Vault implementation. This tool simplifies the process by automating key tasks and ensuring best practices are followed.
Conclusion
Stages are a foundational component of the Data Vault methodology, enabling seamless data preparation and integration. By understanding their role and leveraging the right tools, you can ensure the success of your Data Vault implementation.
Watch the Video
Meet the Speaker

Tim Kirschke
Senior Consultant
Tim has a Bachelor’s degree in Applied Mathematics and has been working as a BI consultant for Scalefree since the beginning of 2021. He’s an expert in the design and implementation of BI solutions, with focus on the Data Vault 2.0 methodology. His main areas of expertise are dbt, Coalesce, and BigQuery.