Data Catalogs in Modern Data Warehousing
Modern data architectures are becoming increasingly complex, posing significant challenges for organizations. Data is often scattered across multiple systems, making it difficult to locate, utilize, and preserve its quality. Analysts spend a substantial amount of time searching for relevant information, while businesses struggle to manage data efficiently and comply with regulatory requirements. A structured approach to metadata management is essential to enhance transparency, maintain data quality, and enable efficient data usage.
This article is aimed at data professionals, business users, and IT teams looking to establish or improve structured metadata management. It explores the challenges of fragmented metadata, the role of data catalogs as a central solution, and how they enhance data organization and usability. Additionally, it provides practical insights into structuring a data catalog within a Data Vault 2.0 architecture to support a scalable and comprehensive data strategy.
The Challenge of Fragmented Metadata
In the era of data-driven decision-making, organizations face a fundamental challenge: fragmented and inconsistent metadata. Across different departments, heterogeneous systems, divergent naming conventions, and varying documentation standards lead to a disjointed data landscape. Analysts and data professionals often spend excessive time locating, verifying, and interpreting data—a process that not only reduces efficiency but also increases the risk of errors and misinterpretations.
At the core of this issue lies the absence of a centralized metadata repository. Without a unified source of truth, critical aspects such as data lineage, ownership, and quality remain unclear. This lack of transparency not only complicates regulatory compliance but also erodes trust in data and impedes strategic initiatives. The result is the formation of data silos that prevent organizations from fully leveraging their data assets. As highlighted, this fragmentation leads to wasted time and effort on finding and accessing data, turns data platforms into data swamps, and hinders the development of a common business vocabulary.
What is a Data Catalog?
A data catalog is a centralized, structured repository that organizes and manages metadata across an organization, facilitating efficient data discovery, governance, and collaboration. Much like a well-curated library, a data catalog enables users to locate, understand, and utilize data efficiently by capturing essential metadata and making it easily searchable and accessible. Beyond merely indexing data assets, a data catalog provides critical context, tracks relationships between datasets, and integrates user-driven insights to enhance data usability and governance.
Features of a Data Catalog
A well-implemented data catalog consists of several foundational features that support metadata management, data governance, and user collaboration:
- Metadata Management: Captures and organizes essential information about datasets, such as source, format, relationships, and usage patterns, ensuring accessibility and usability.
- Data Discovery: Enables users to locate and access data quickly through intuitive search functions that leverage metadata attributes and contextual tags.
- Data Lineage: Tracks the lifecycle of data, mapping its journey from origin to consumption. This allows organizations to trace transformations, ensuring data integrity and error resolution.
- Data Governance: Establishes policies for data availability, usability, integrity, and security. This can include access control, regulatory compliance, and stewardship responsibilities.
- Business Glossary: Defines business terminology and ensures consistency across the organization, improving communication and reducing misinterpretation of data fields.
- Data Dictionary: Provides technical documentation on data structures, including schema definitions, data types, and field constraints.
- Data Profiling: Analyzes datasets to generate statistics on data quality, completeness, distribution, and anomalies. This helps organizations understand their data better and ensures its reliability for analytical and operational use.
Benefits of a Data Catalog
A data catalog enhances data discovery by providing structured metadata, enabling users to efficiently find and access the right datasets. By offering clear definitions, contextual information, and lineage tracking, it improves data comprehension, ensuring that users understand data origins, transformations, and relationships.
Discovering and understanding data sources and their use is a core function of a data catalog. Business users can quickly locate relevant datasets, evaluate their fit, and utilize them effectively. Additionally, users can contribute to the catalog by tagging, documenting, and annotating data sources, fostering collective knowledge and enhancing data usability.
It fosters trust by documenting data quality, provenance, and usage, ensuring that users rely on accurate, well-maintained datasets. Furthermore, by reducing redundancy and streamlining workflows, a data catalog increases operational efficiency, saving time and resources while maximizing the value of an organization’s data assets.
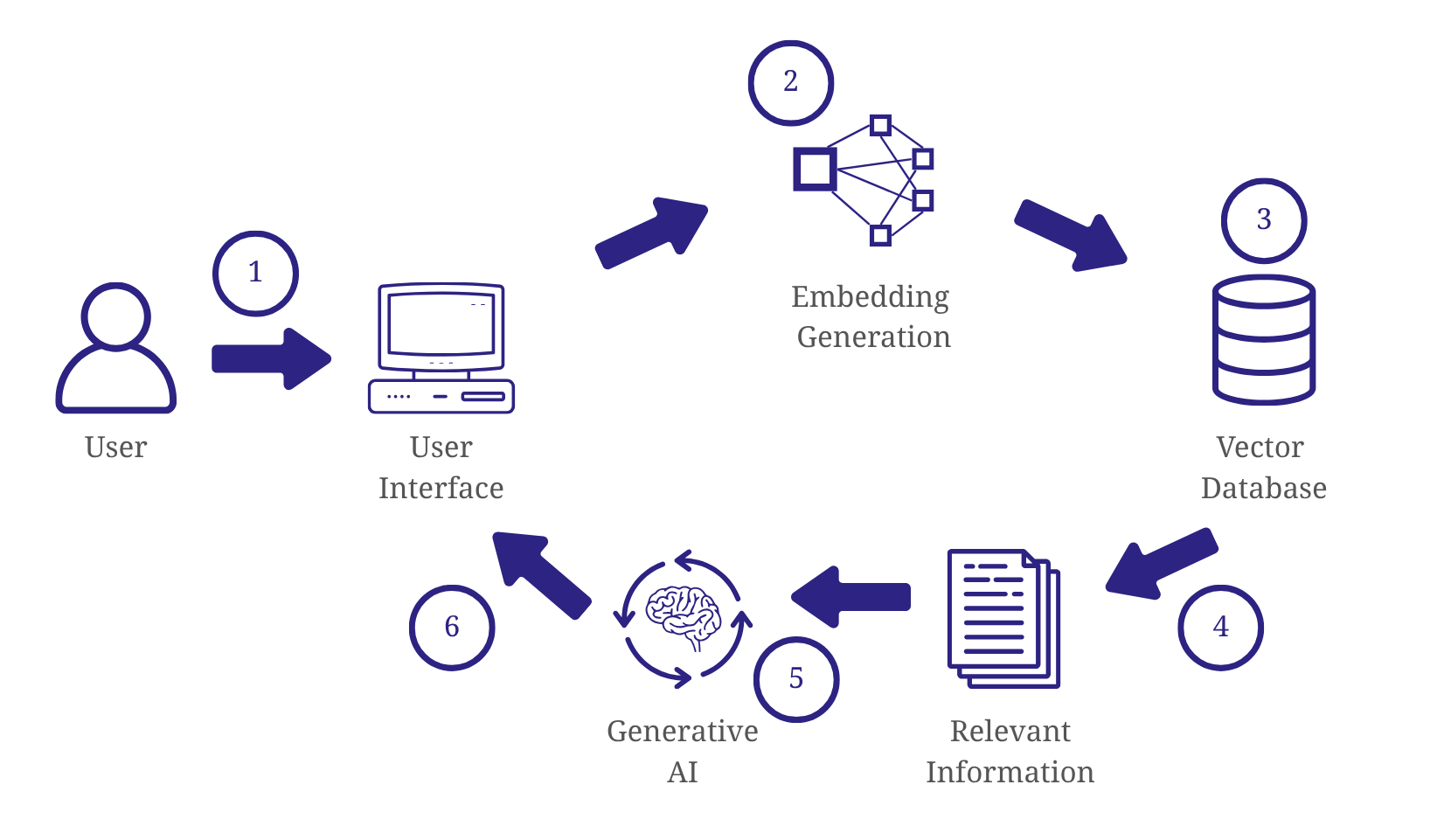
How a Data Catalog Works
A data catalog functions as a dynamic metadata management system, automating the extraction, organization, and indexing of metadata. It seamlessly connects to various data sources, including data platforms, data lakes, ETL pipelines, and BI tools, synchronizing metadata through two primary approaches: pull-based and push-based ingestion.
In the pull-based approach, the data catalog actively queries source systems using APIs, JDBC connectors, or scheduled scans to retrieve metadata. This method allows the catalog to regularly update its metadata repository by fetching information from the source systems. On the other hand, the push-based approach relies on source systems to send real-time metadata updates to the catalog through event-driven mechanisms, webhooks, or message queues. This ensures immediate synchronization of metadata, keeping the catalog up-to-date with any changes in the data landscape.
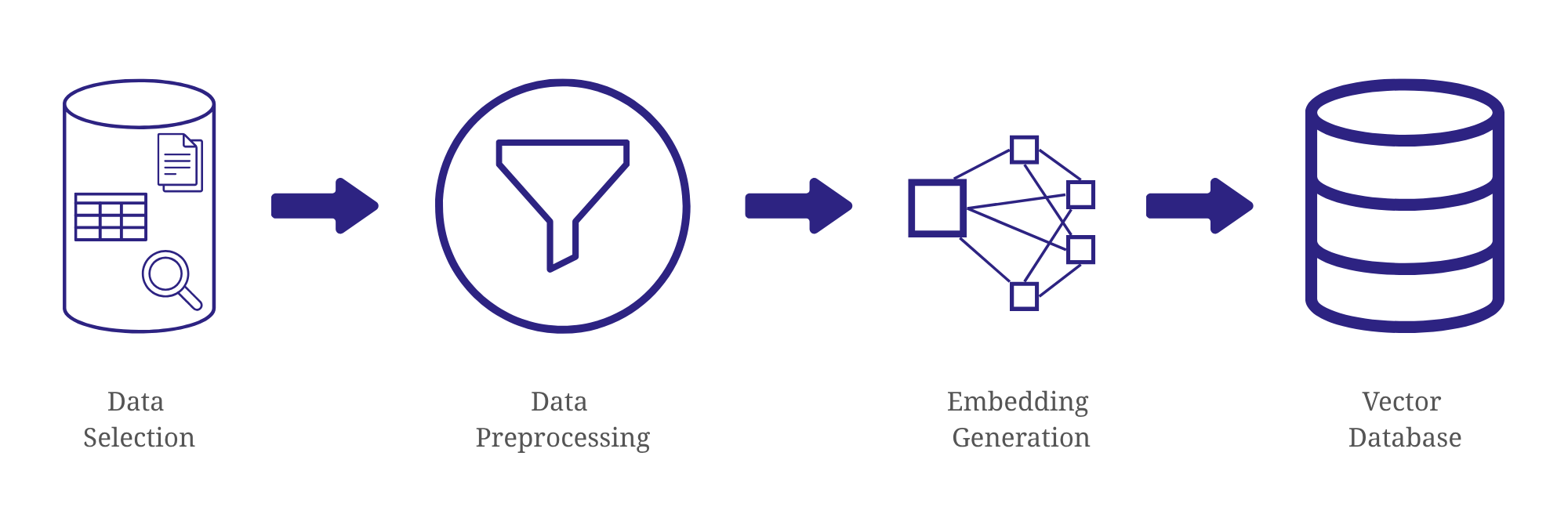
Once metadata is ingested, the data catalog standardizes and enriches it, ensuring consistency and adding valuable context. This process includes extracting schema details, identifying data ownership, applying classifications, and establishing data lineage. The standardized and enriched metadata is then stored in an indexed repository, enabling fast search, filtering, and lineage tracking. Furthermore, automated tagging, schema change detection, and governance policies are implemented to ensure compliance with security and regulatory requirements.
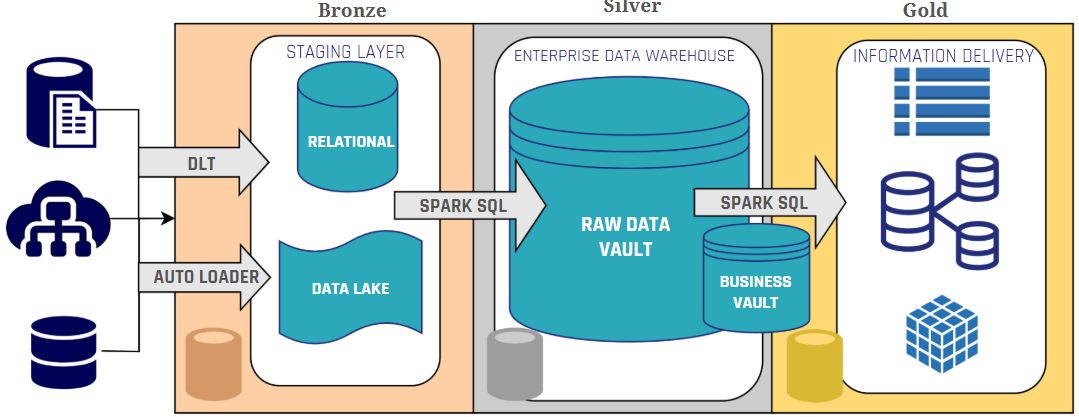
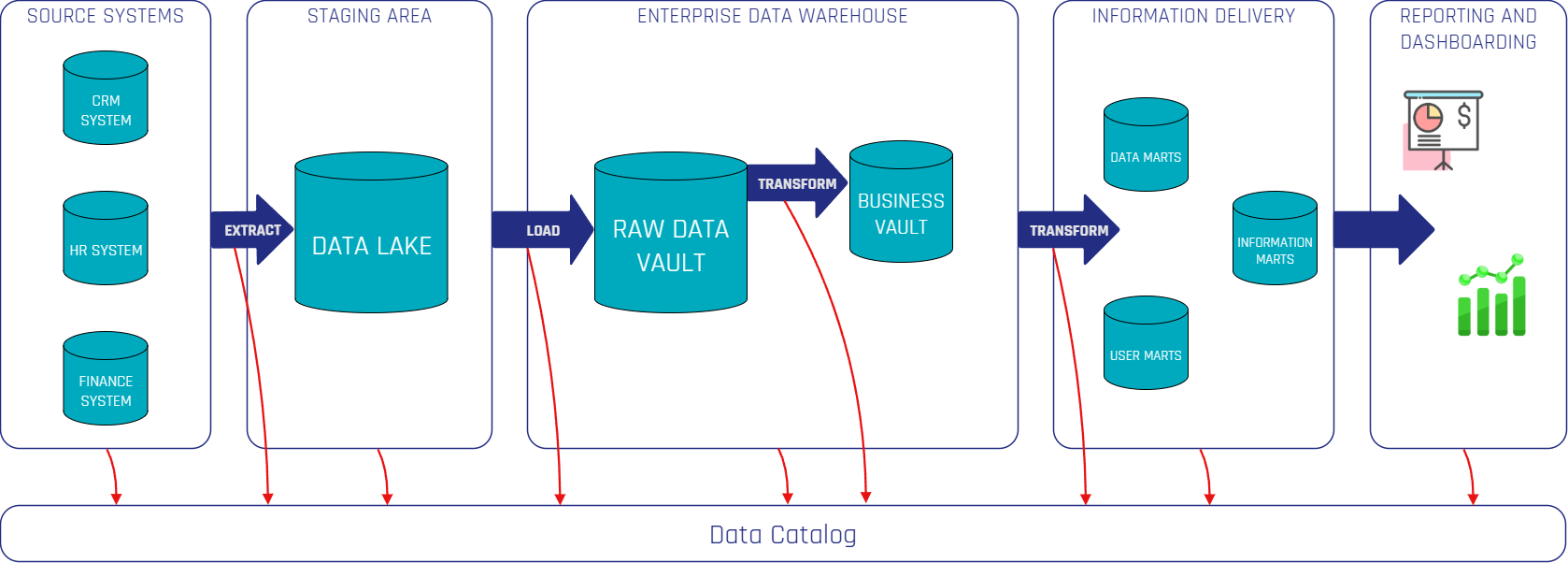
Integrating a Data Catalog With Data Vault 2.0
The diagram illustrates how a Data Catalog integrates into a Data Vault 2.0 Architecture. Using various connectors, it extracts metadata from source systems, data platforms, ETL tools, and BI tools through push- or pull-based approaches. The red arrows represent the flow of metadata from these systems into the Data Catalog, ensuring continuous capture and synchronization of metadata. This process guarantees end-to-end visibility, governance, and accessibility, making data assets more reliable and valuable for business users and analysts.
Organizations can choose between open-source and commercial solutions. Commercial platforms like Atlan, Alation, and Collibra offer fully managed enterprise solutions with automation and vendor support, while open-source tools such as DataHub, Amundsen, and OpenMetadata provide more customizability and cost efficiency. Many open-source solutions now also offer cloud-based enterprise versions for easier deployment.
Self-hosted deployments are typically hosted on Docker or Kubernetes, giving organizations greater control and security, making them ideal for compliance-heavy environments. Meanwhile, cloud-based solutions offer automatic scaling and lower maintenance overhead, simplifying operations.
A well-integrated Data Catalog should connect seamlessly with data sources, ingest metadata efficiently, and provide structured management and governance. In a Data Vault 2.0 environment, it enhances traceability and transparency, enabling better data-driven decisions and reducing inefficiencies caused by fragmented metadata.
Introduction to DataHub
In this section, we will present an example of a data catalog tool and some of its key features.
DataHub is a leading open-source data catalog developed by LinkedIn to address the challenges of data discovery, governance, and observability in complex data ecosystems. Designed to handle the increasing volume, variety, and velocity of data, DataHub has been adopted by numerous organizations seeking to improve their metadata management practices. It supports both push- and pull-based metadata ingestion, seamlessly integrating with a wide range of data tools and technologies, including dbt, Snowflake, BigQuery, and Airflow.
Key Features of DataHub
DataHub goes beyond the traditional features and benefits of a standard data catalog by offering advanced features that address modern data management challenges. Here are some practical insights on how DataHub solves some of the features of a data catalog:
- Data Discovery: Leveraging advanced search capabilities and detailed metadata, DataHub enables users to quickly locate and understand data assets, facilitating efficient data-driven decision-making across the organization, with a powerful search and filtering mechanism that allows users to refine queries by platform, domain, data type, owner, and specific tags, significantly enhancing the search process.
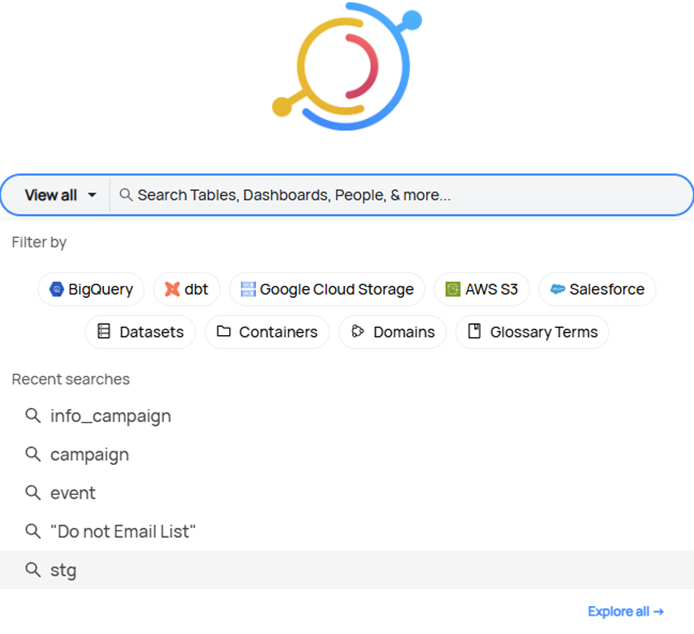
Screenshot of Internal Data Catalog
- Data Lineage: It provides a comprehensive, visual trace of data flow—from origin through various transformations to final consumption—ensuring transparency, simplifying troubleshooting, and supporting compliance efforts. This lineage can extend down to the column level, offering a granular view of how data is transformed and utilized throughout the system.
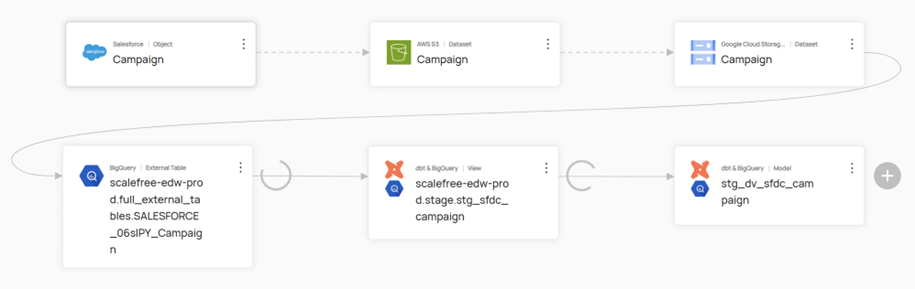
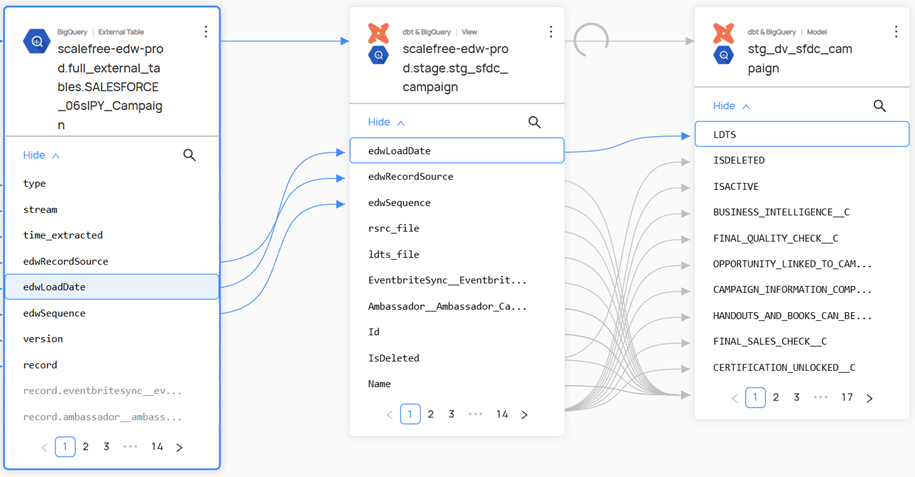
Screenshot of Internal Data Catalog
- Data Profiling: DataHub continuously monitors and analyzes data quality, automatically generating profiling metrics that reveal data distributions, identify anomalies, and help maintain high data quality standards. It provides key statistics such as row and column counts, query frequency, top users, and last update timestamps, along with detailed attribute profiling, including value ranges, central tendencies, null and distinct values. The table below shows some examples of these profiling metrics.
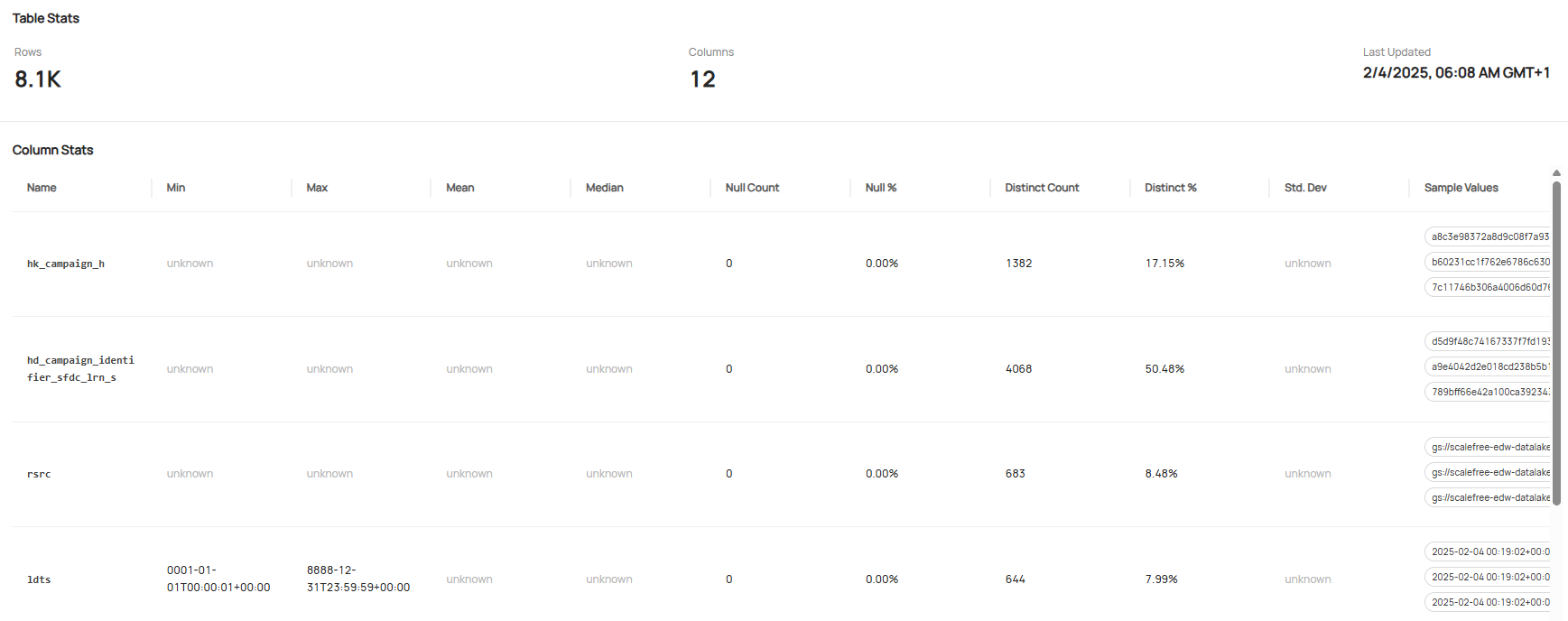
Screenshot of Internal Data Catalog
Watch the Video
Conclusion
In an era where data volume and complexity continue to surge, a robust data catalog is no longer optional, it is essential. By centralizing and enriching metadata, catalogs like DataHub turn fragmented datasets into a coherent, trustworthy foundation for analytics, governance, and collaboration. Implemented alongside architectures such as Data Vault, they deliver the transparency, lineage, and quality controls that modern organizations need to unlock real value from their data, quickly, confidently, and at scale.
– Tim Luca Derksen (Scalefree)