Watch the Video
In our ongoing Data Vault Friday series, our CEO Michael Olschimke engages with a thought-provoking question from our audience regarding Same-as-Links.
“Sometimes mapping logic for Same-As-Links (SAL) requires complex ‘fuzzy’ business logic. When does the logic become too complex for the Raw Data Vault, and instead, the joining of similar tables from different sources becomes a Business Vault concern? It’s important to not have convoluted transformations in the Raw Data Vault, so where do we ‘draw the line’ on transformations being too convoluted/complex for a Raw Data Vault entity?”
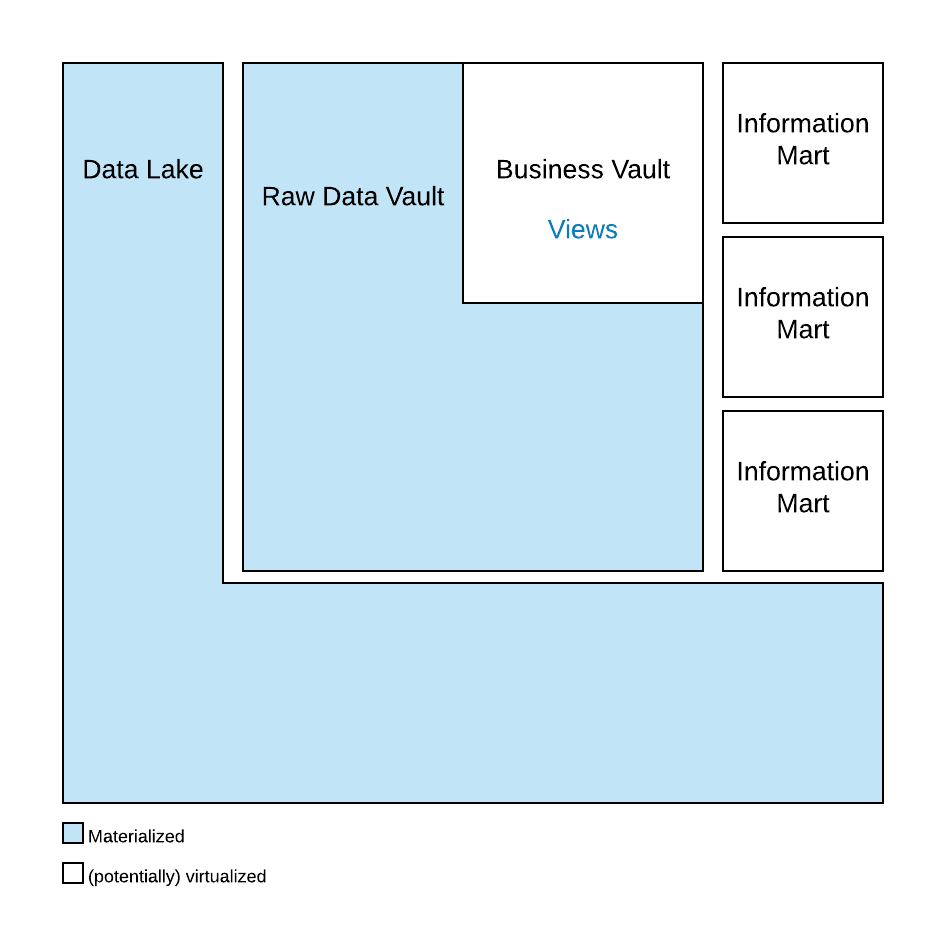
In this enlightening video, Michael addresses the delicate balance between the Raw Data Vault, where no business logic is applied, and the Business Vault, where most business logic is implemented. He provides insights into recognizing when the mapping logic for Same-As-Links (SAL) becomes too intricate for the Raw Data Vault, prompting the shift to the Business Vault for handling complex transformations.
The discussion offers practical considerations and a clear perspective on drawing the line to maintain the efficiency and clarity of transformations within the Raw Data Vault.