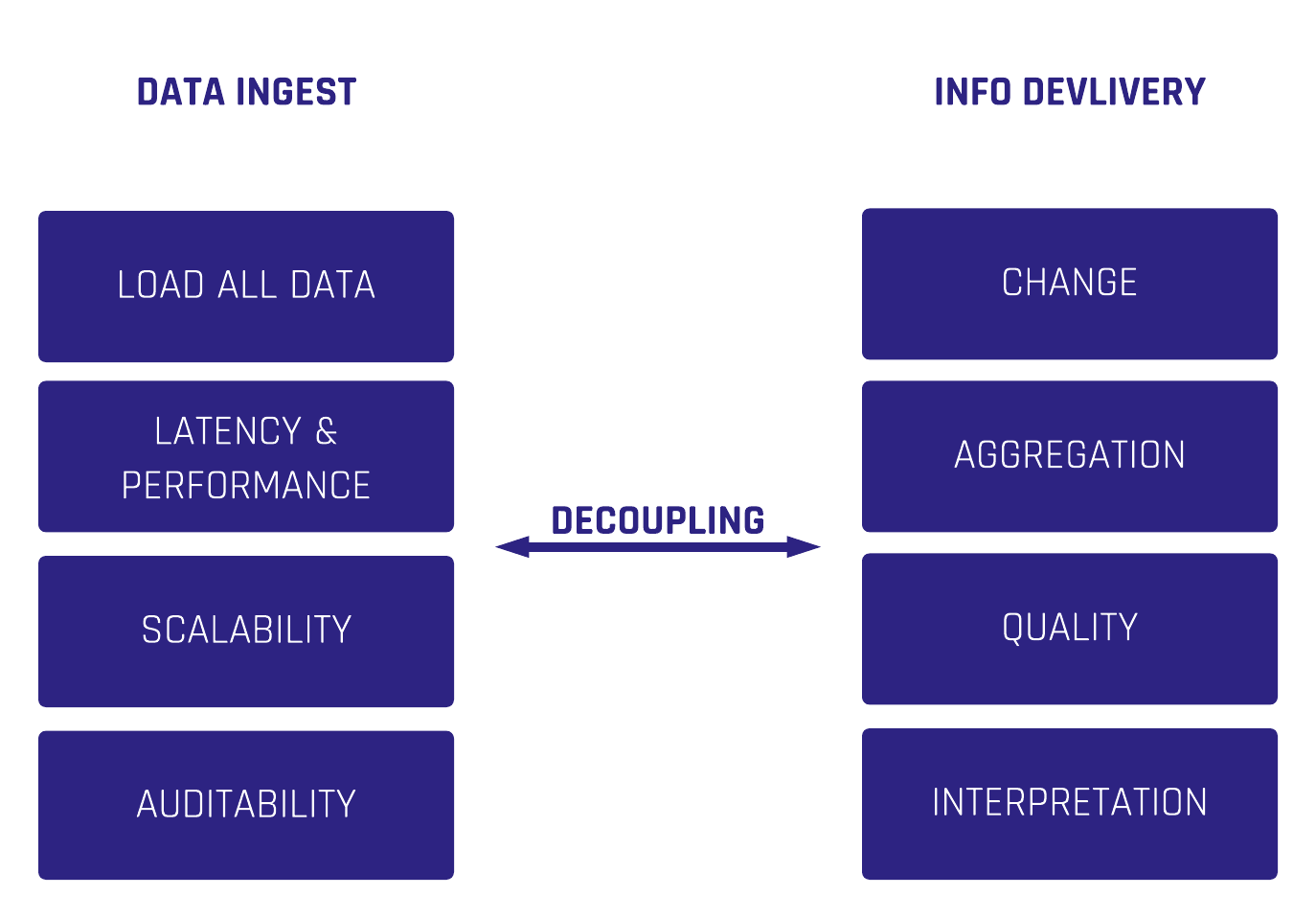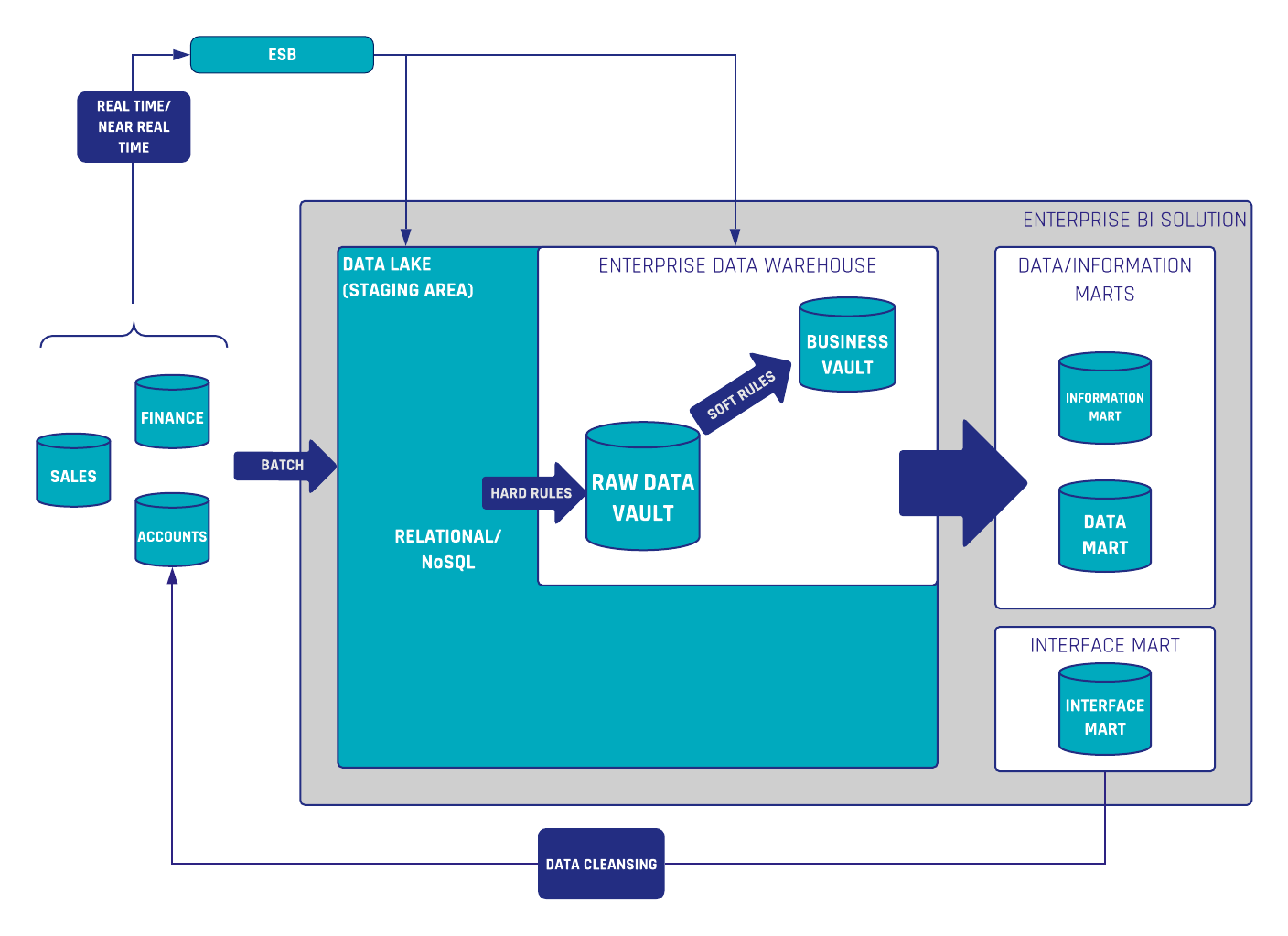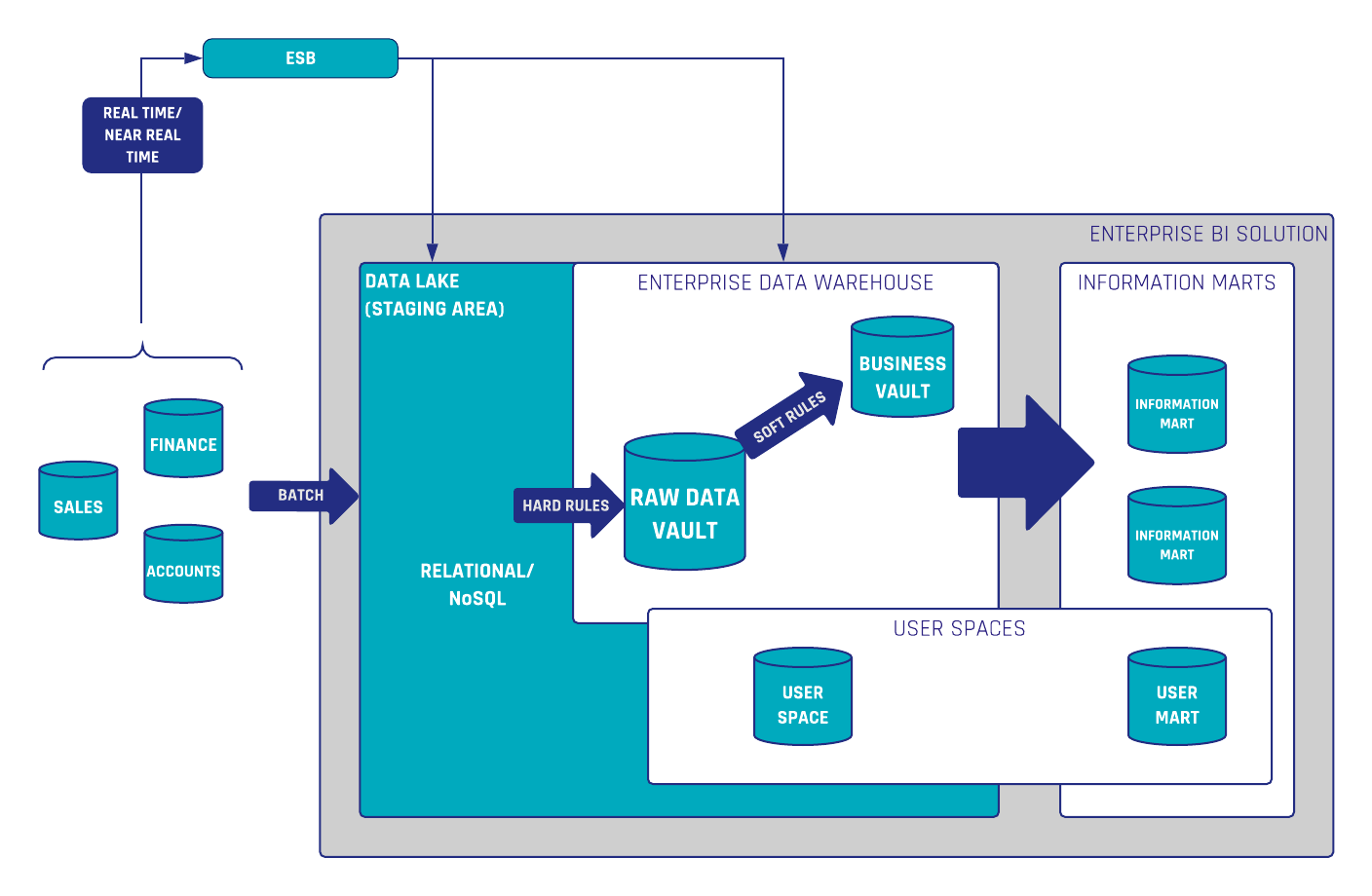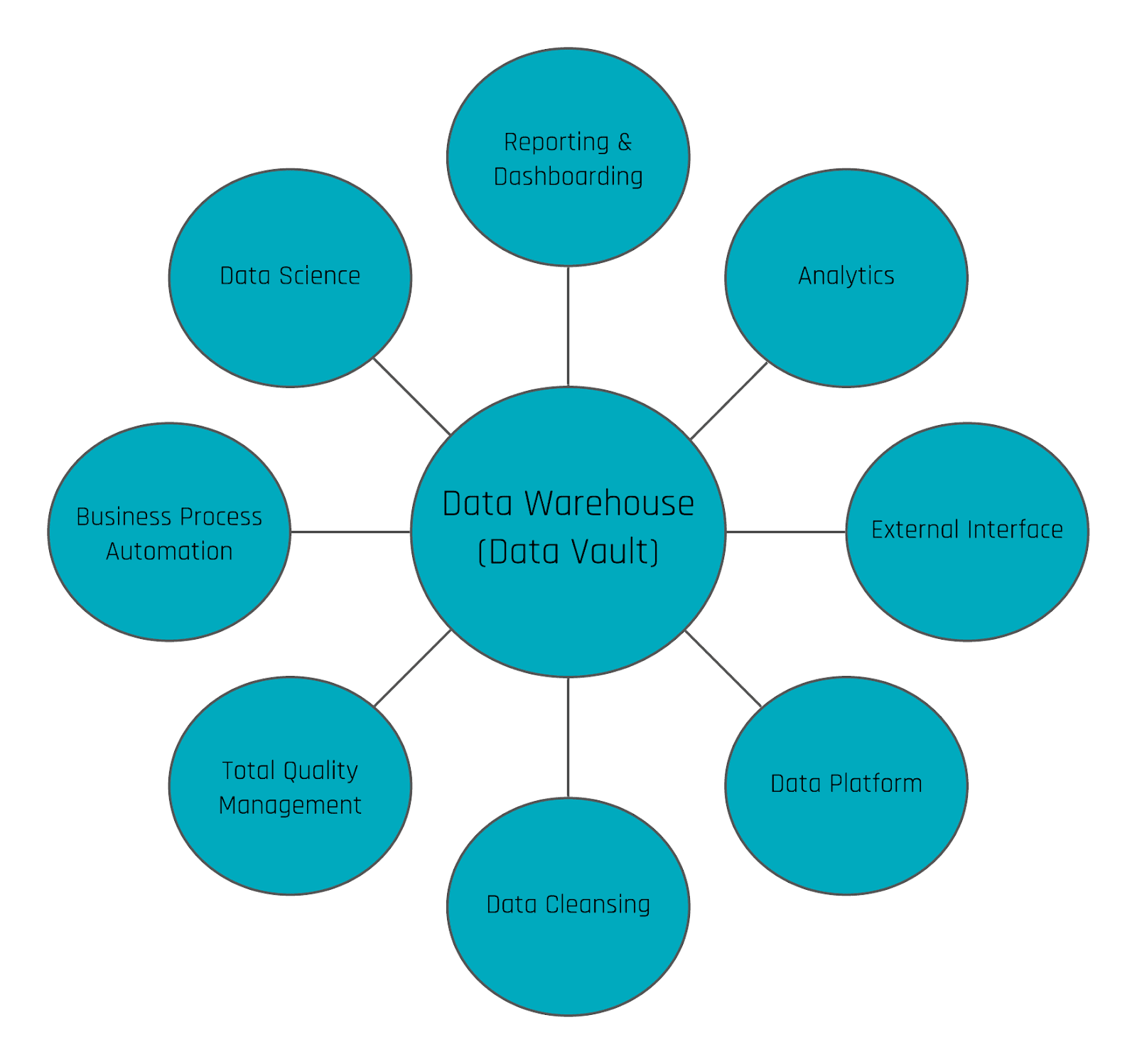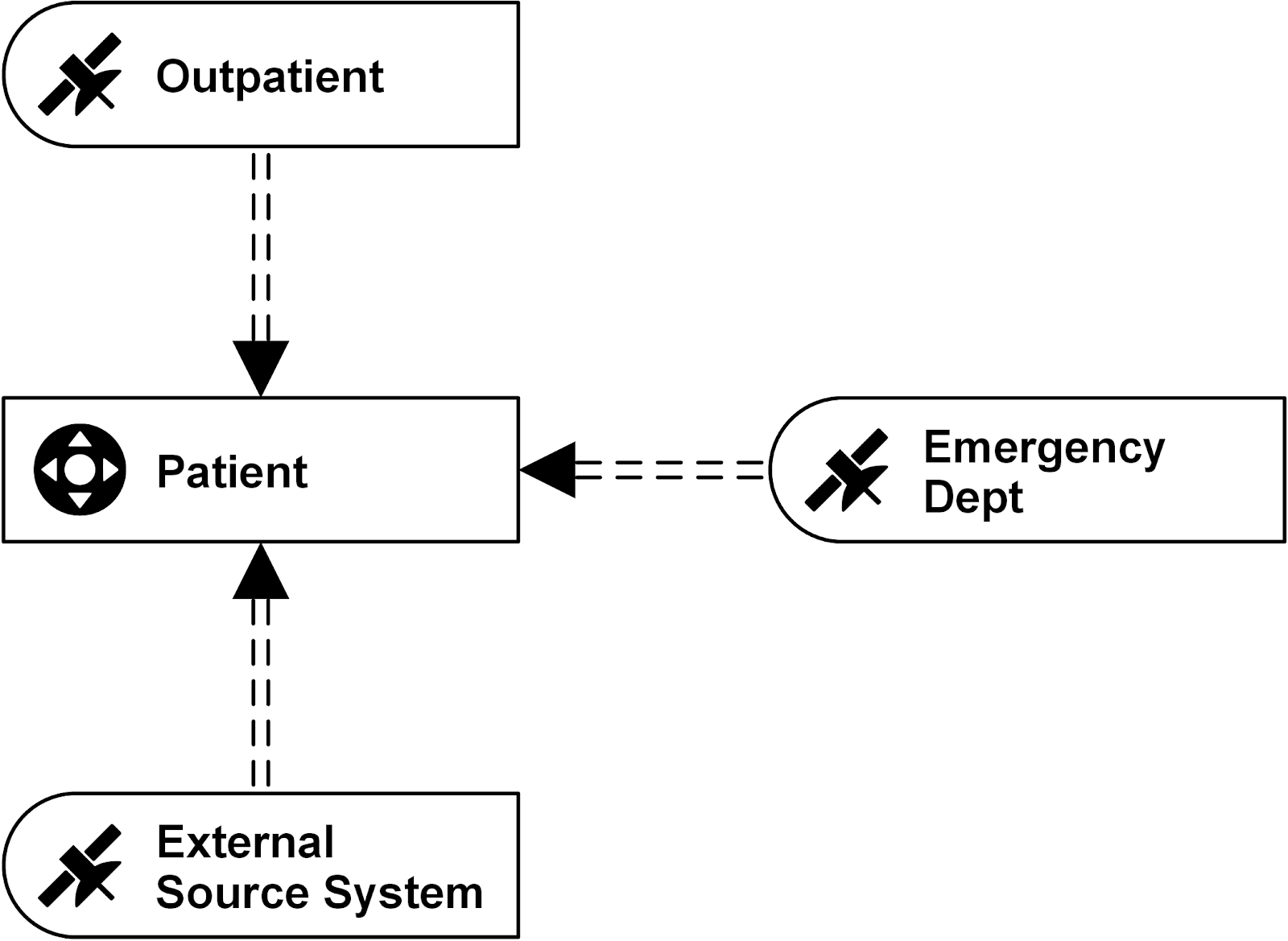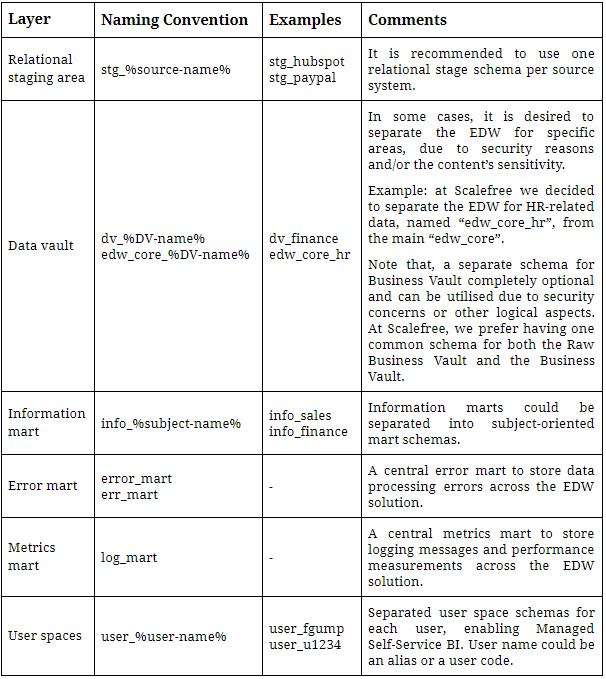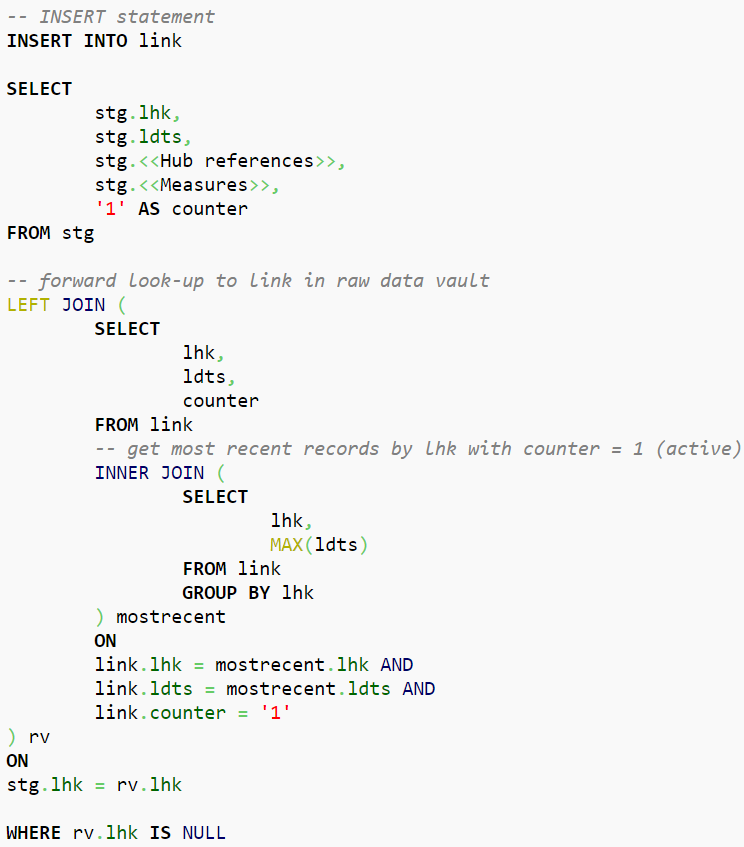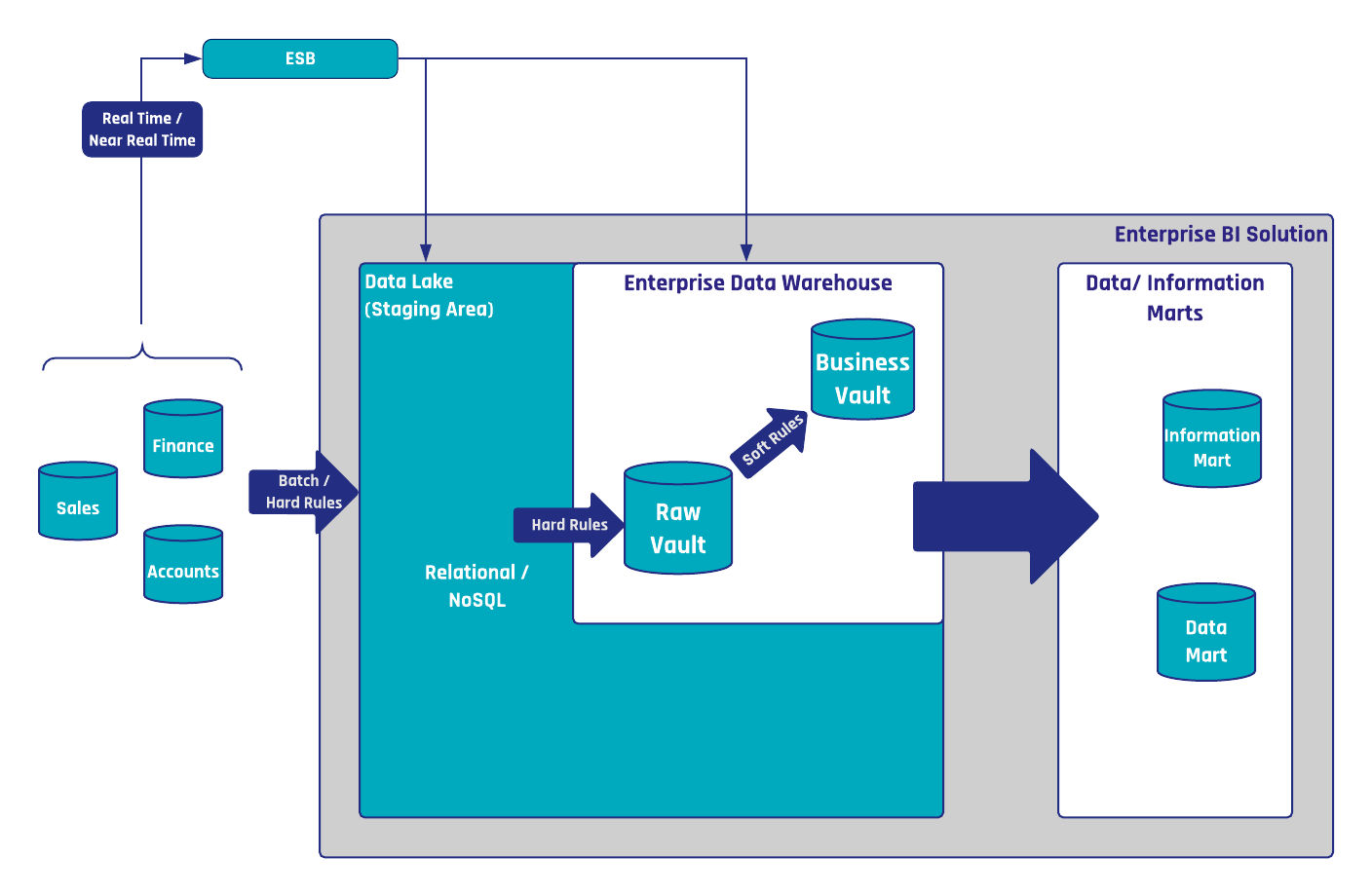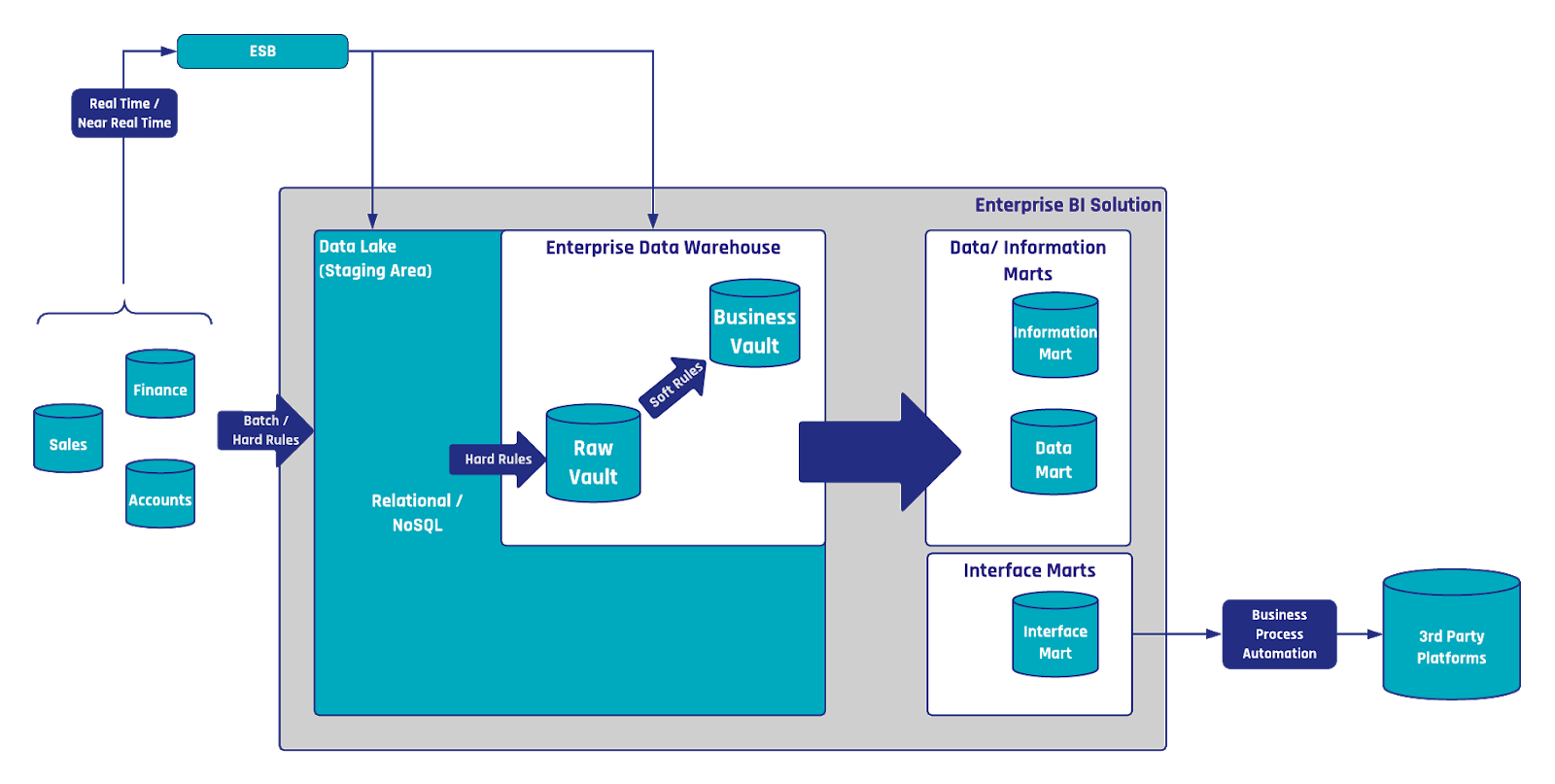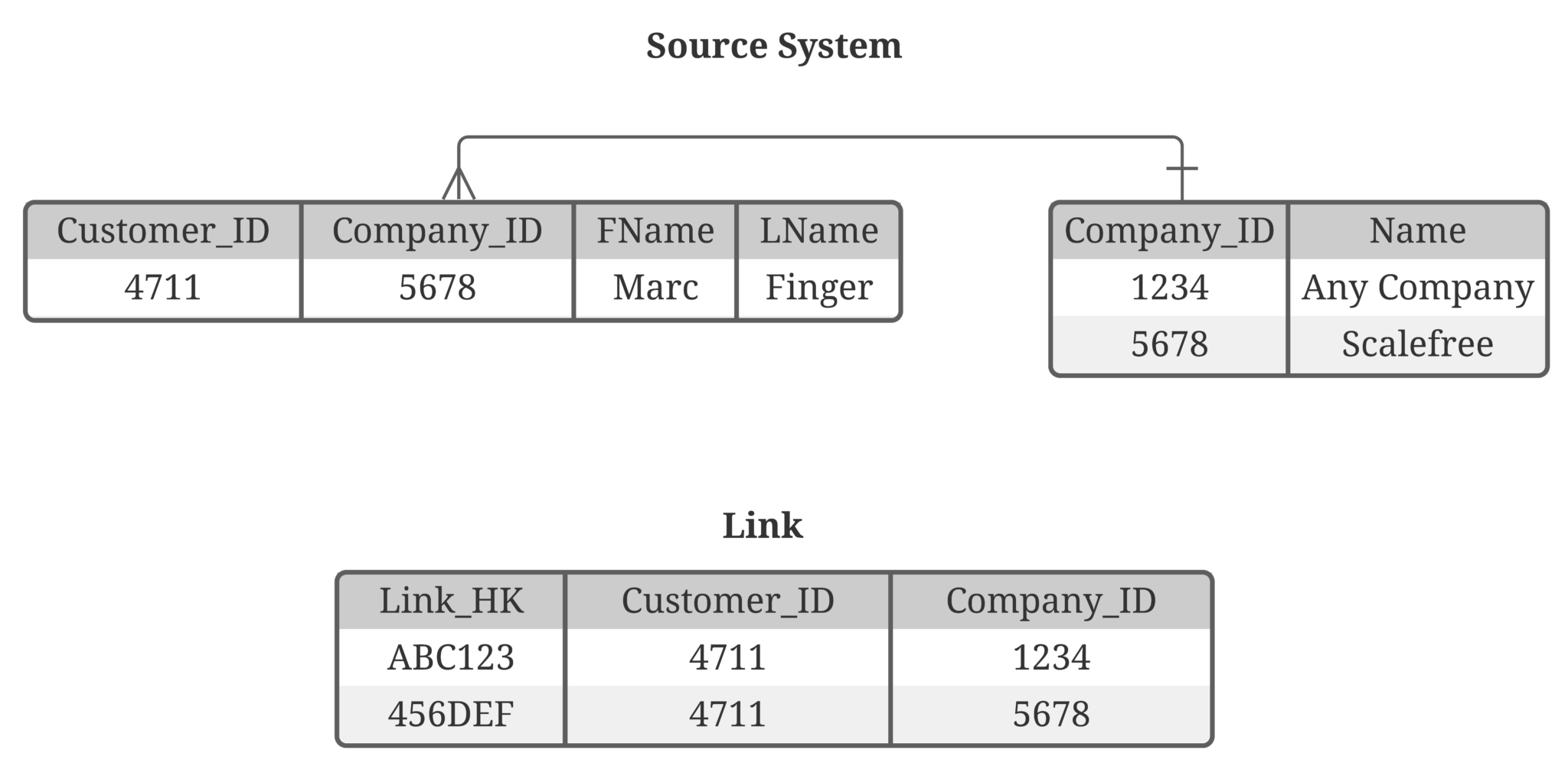
In Data Vault 2.0, we differentiate data by keys, relationships and description. That said, an often underestimated point is the handling of relationships in Data Vault 2.0. In the following…
Read More
Used by 8k+ people to unlock the power of their data.
Subscribe Me© 2024 Scalefree International GmbH
Imprint | Privacy Policy | Terms and Conditions