New Possibilities with Data Vault 2.0
Data Vault 2.0 empowers organizations to go beyond traditional reporting by unlocking new avenues for scalability, automation, and data-driven decision-making. From cleansing data and automating business processes to enabling advanced data science techniques like machine learning and predictive analytics, Data Vault 2.0 provides a flexible framework for modern data challenges. In this article, we explore how Data Vault 2.0 integrates data science to optimize operational processes, predict outcomes, and enhance enterprise data warehouses, ensuring a competitive edge in today’s data-driven landscape.
Going beyond standard reporting
Reporting and dashboarding have become the standards in business when it comes to identifying KPIs and other measurements. As such, Enterprise Data Warehouses have emerged to support the reporting process. Though, due to the large quantity and variety of data, a demand has developed for a method of utilizing this existing data in a manner in which it can add additional business value towards a company’s needs. Data Vault 2.0 offers a wide range of methods to provide decision support beyond standard reporting as well as critical information regarding the future. To see for yourself, join us as we present different approaches and solutions as to fully leverage the potential of your data.
Going beyond standard reporting
As we have shown in previous issues, Data Vault 2.0 enables individuals to implement reporting beyond the traditional methods.
In the first part, we demonstrated how to perform data cleansing in Data Vault 2.0.
And the second use case showed how to implement business process automation using Interface Marts.
The scalability and flexibility of Data Vault 2.0 offers a whole variety of use cases that can be realized, e.g. to optimize as well as automate operational processes, predict the future, push data back to operational systems as a new input or trigger events outside the data warehouse, to name a few.
By leveraging the enterprise data warehouse for data science, the TCO of data processing can be reduced: instead of processing the same data twice, once for reporting purposes and once for ad-hoc data analysis, the data is stored in the central data warehouse to be then used by multiple applications, reporting in addition to data analytics are only two cases as the following diagram shows:
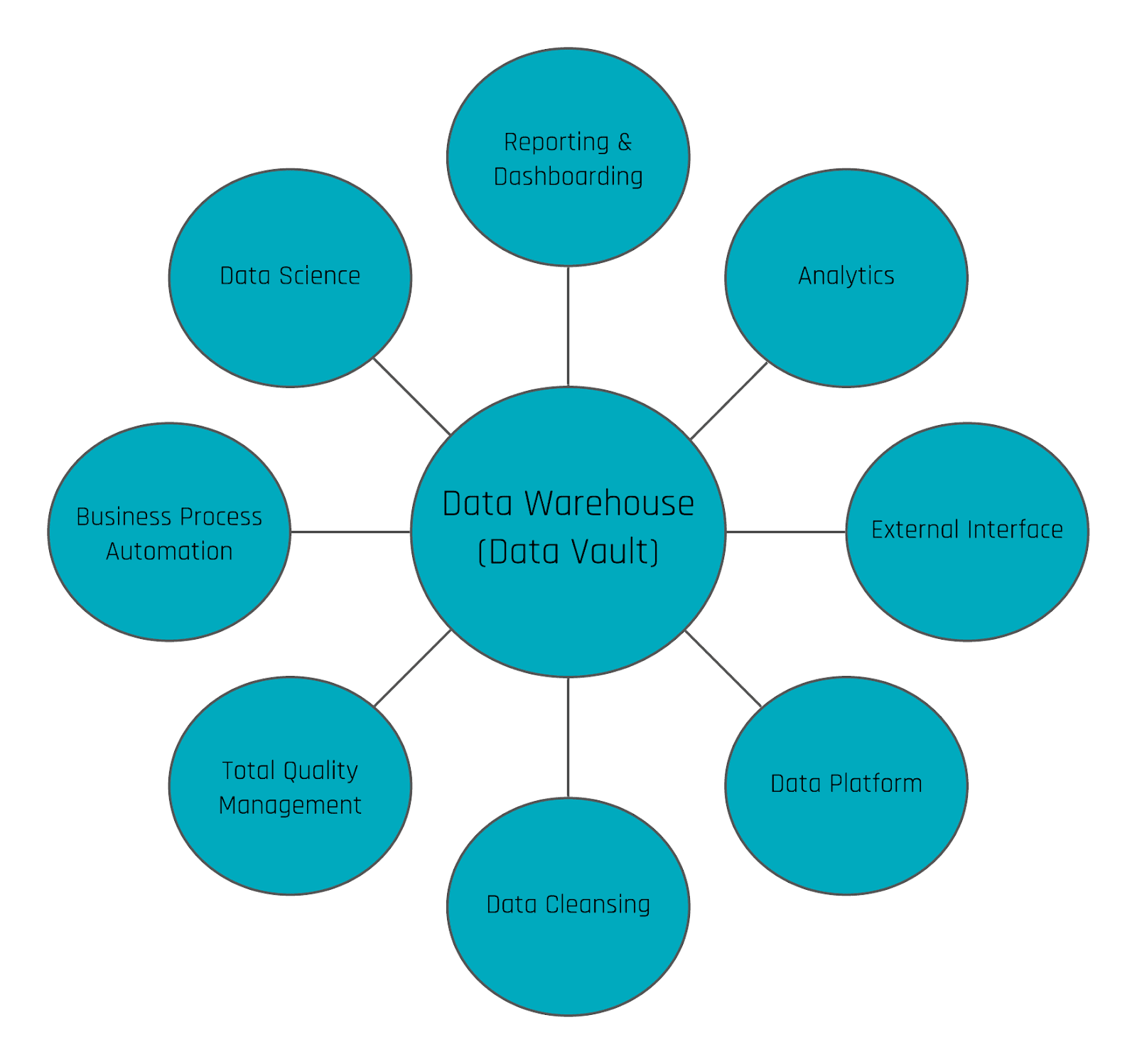
Figure 1: Data Vault Use Cases
In addition to the aforementioned cases, business process automation and external interfaces for writebacks into applications are standing out.

The Data Vault Handbook:
Core Concepts and Modern Applications
Build Your Path to a Scalable and Resilient Data Platform
The Data Vault Handbook is an accessible introduction to Data Vault. Designed for data practitioners, this guide provides a clear and cohesive overview of Data Vault principles.
Data Science in Data Vault 2.0
The following use case deals with a topic that has received increasing attention in recent years and whose use in data warehousing should not be ignored. Data Science. Whether it is data mining, machine learning or deep learning, each of these topics has become very popular.
Within Data Vault 2.0, methods from the data science area can be regarded as soft business rules due to the fact that the data is modified or new information is created during the execution. As a result, the usage takes place at the Business Vault.
Figure 2: Data Science in Data Vault 2.0
One possible application of machine learning in Data Vault 2.0 is the scoring of new leads.
Here, a model is developed on the basis of known customers who have already used services in a company in order to identify potential new customers and quantify their possible value.
The model enables promising customers to be identified and further processes to be initiated in a targeted manner.
The predictive model can be executed in different ways, e.g. as a Python or R script. Further, we are able to show a possible realization as a process in RapidMiner Studio. Here, the data is loaded from the Business Vault and preprocessed for further analysis. The algorithm is then trained with the help of customers already known to us.
The resulting model is then used to evaluate new leads.
Finally, the decisions made and the data that led to the decision are loaded back into the EDW to form new entities in the Business Vault.
Figure 3: RapidMiner Studio Process
Conclusion
This is just one example of how Data Science can be applied within Data Vault 2.0.
Other options include processes such as loading data from the data lake to process the raw data from the source system according to user-defined processes. It is worth noting that it is also possible to use the information from the information marts to make them even more valuable.
The options provided by Managed Self-Service BI are also of a great advantage. This allows different users to develop and test models in their own user spaces as well as share the results as needed.
The automation of these processes also increases the value of the EDW for the company. In addition to this, different scenarios can be simulated and valuable decisions for the future can be made.