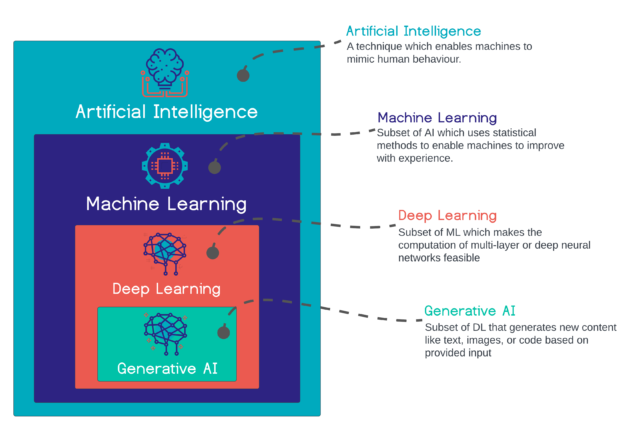
dbt Semantic Layer
The bigger a corporation gets, the more data is available, and more and more users want to use this data. In a traditional data warehouse (DWH) environment, the DWH typically provides a consumption layer consisting of various information marts, which are then loaded into multiple business intelligence (BI) tools. In there, business users transform and aggregate the data to calculate KPIs and finally make business decisions.
This, as it turns out, is easier said than done. To derive KPIs out of the data, business users need to have a common understanding of the data provided by the DWH. The information to understand the data is typically hard to find and not accessible in a single place.
Ultimately, this might lead to multiple departments having different understandings of the same data and deriving different interpretations of the same KPI. Now, it’s very likely that the worst case scenario happens, the trust in your data fades out. This is where a unified semantic layer can help!
From Raw Data To Semantic Layer – With Turbovault And Dbt Cloud
Data Vault is vital for businesses due to its adaptability and scalability in managing dynamic data environments. Its hub-and-spoke architecture ensures traceability and agility, enabling quick adaptation to changing requirements and diverse data sources.
Join our webinar and learn about how to use dbt Cloud with Turbovault and a data modeling tool to implement Data Vault in your organization. Additionally, we will have a look at the dbt Semantic Layer.
Components of the dbt Semantic Layer
The dbt Semantic Layer helps simplify the definition and usage of critical business metrics in your dbt project. Metric definitions are centralized to allow consistent self-service usage for all data teams.
By shifting metric definitions from the BI layer into the modeling layer, business users from different units can be confident that they use the same metric definition, no matter which tool they use. In case a metric definition changes over time, the changes will be applied everywhere it’s used and therefore consistency is enforced.
To create a unified semantic layer inside your dbt project, the following steps are necessary:
- Draft a semantic model
- To implement a semantic model, a model needs to be drafted first. This should happen via a collaboration between the technical and business teams, to identify core business concepts and how they relate to each other.
- Create dbt models that match your semantic model
- Each object of your semantic model should be turned into a dbt model 1:1. While creating them, put extra work into aligning column names with naming standards and correctly developing the loading logics.
- Create new .yml files in the metrics folder
- Everything related to the dbt Semantic Layer needs to be located in a new folder called “metrics”. In there, .yml files are used to define and configure your semantic models. We recommend creating one .yml file per semantic model.
- Define entities
- In contrast to the name, entities in the semantic model roughly describe columns of semantic models. Entities can be of four different types: Primary, Unique, Foreign, or Natural. Every model needs to have a primary entity, and one entity can be just one column or a SQL expression transforming a column.
- Define dimensions
- A dimension in the dbt Semantic Layer can be seen as different ways to look at your model, i.e., group the data by a specific attribute. Every dimension needs to be tied to a primary entity, which is used for the grouping. A good example is a date column which enables you to group your data by day, month, or year.
- Define measures
- Measures represent aggregations applied to specific columns in your data model. Measures can be used in other measures to calculate more complex ones, and can be defined with various parameters that help create executable SQL code for calculation.
- Measures represent aggregations applied to specific columns in your data model. Measures can be used in other measures to calculate more complex ones, and can be defined with various parameters that help create executable SQL code for calculation.
- Define metrics
- Metrics represent the language of the business users. They can be of various types, which represent different kinds of calculations. Some examples include Conversion metrics, Cumulative metrics, Derived metrics, and Ratio metrics. They are always based on measures and represent the last building block of the semantic layer.
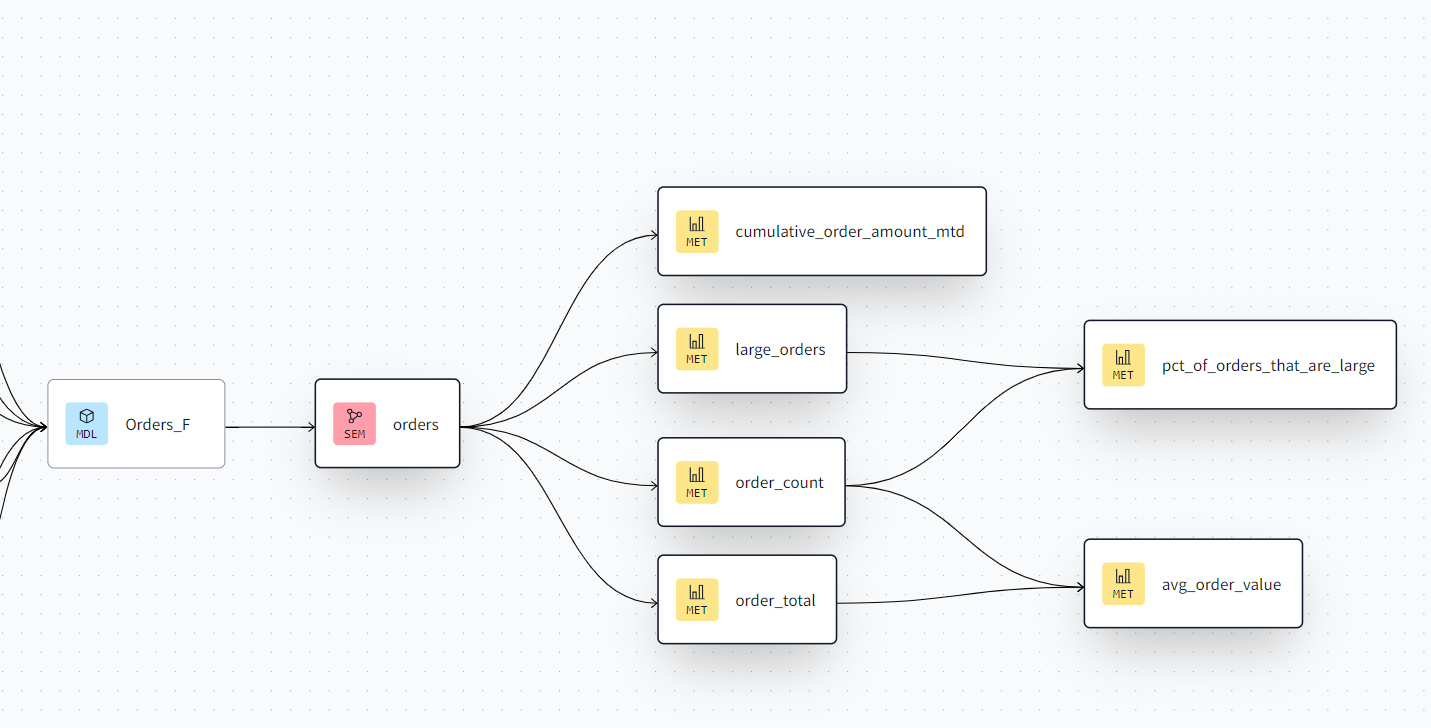
This is how the semantic layer is reflected in your dbt lineage:
Consuming the dbt Semantic Layer
Once your dbt project has a semantic layer defined, it can be opened to data consumers. The dbt Semantic Layer allows various BI tools to directly connect to your dbt Cloud project and integrate metrics, measures, and filters directly into the tool of choice.
The following tools are already natively supported:
- Tableau
- Google Sheets
- Microsoft Excel
- Hex
- Klipfolio PowerMetrics
- Lightdash
- Mode
- Push.ai
- Steep
Other tools can be integrated with custom integrations, as long as they support generic JDBC connections and are compatible with Arrow Flight SQL.
Conclusion
The dbt Semantic Layer can help regain trust in your data warehouse. By moving calculations back from the business users into the data model, a common definition of business KPIs is created.
Although there is some additional setup required, implementing a semantic layer can highly improve the value generated by your data. Integrating it into the BI tools of your business users even simplifies the way your data is consumed.
If you want to know more about the dbt Semantic Layer and learn how it fits into a Data Vault 2.0 powered Data Warehouse, make sure to join our next webinar on August 13th!
– Tim Kirschke (Scalefree)