Microsoft Fabric für Business Intelligence
Microsoft Fabric ist eine cloudbasierte All-in-One-Analyseplattform, die eine einheitliche Umgebung für Datenexperten und Geschäftsanwender bietet, um gemeinsam an Datenlösungen zu arbeiten. Diese leistungsstarke Plattform unterstützt Unternehmen dabei, Workflows zu automatisieren, die Produktivität zu steigern und wertvolle Erkenntnisse aus ihren Daten zu gewinnen.
In der heutigen datengesteuerten Welt setzen Unternehmen zunehmend auf Business-Intelligence-Lösungen (BI), um fundierte Erkenntnisse aus ihren Daten zu generieren. BI-Lösungen helfen Unternehmen dabei, ihre Entscheidungsfindung zu verbessern, ihre Abläufe zu optimieren und sich einen nachhaltigen Wettbewerbsvorteil zu verschaffen.
Das Potenzial von Microsoft Fabric für Business Intelligence -Lösungen
Microsoft Fabric ist eine neue, innovative Datenanalyseplattform, welche die Art und Weise, wie Unternehmen Entscheidungen treffen, revolutionieren kann. Mit Fabric können Organisationen all ihre Daten an einem einzigen Ort erfassen, speichern, verarbeiten und analysieren, indem sie ein einheitliches Portfolio an Tools und Diensten nutzen. Dies ermöglicht es, schneller und einfacher als je zuvor Erkenntnisse aus Daten zu gewinnen. In diesem Beitrag untersuchen wir das Potenzial von Microsoft Fabric für Business-Intelligence-Lösungen. Wir erörtern, wie Fabric genutzt werden kann, um die Datenqualität zu verbessern, Analyse-Workflows zu optimieren und Anwendern passgenaue Erkenntnisse bereitzustellen. Dieses Webinar ist für alle interessant, die mehr darüber erfahren möchten, wie sie mit Microsoft Fabric einen maximalen Mehrwert aus ihren Daten ziehen können. Besonders wertvoll ist es für Data Engineers, Analysten, Business-Intelligence-Experten sowie IT-Entscheidungsträger. Registrieren Sie sich jetzt für dieses kostenlose Webinar und erfahren Sie, wie Microsoft Fabric Ihnen helfen kann, Ihre Business-Intelligence-Lösungen auf ein neues Niveau zu heben!
Was Sie erwartet
Dieser Newsletter zeigt Ihnen die transformative Kraft von Microsoft Fabric für Business-Intelligence-Lösungen. Sie lernen die verschiedenen Workloads und Experiences kennen, die Microsoft Fabric bietet, und erlangen ein umfassendes Verständnis seiner Funktionen. Zudem entdecken Sie die Vorteile, die Microsoft Fabric für die datengesteuerte Entscheidungsfindung bietet, um fundierte Entscheidungen zu treffen, die Ihr Unternehmen voranbringen. Schließlich tauchen Sie tief in das Potenzial ein, das Microsoft Fabric für die Verbesserung von Business-Intelligence-Lösungen bereithält, und erfahren, wie Sie neue Dimensionen von Erkenntnissen und Entscheidungsprozessen erschließen können.
Um noch tiefer in das Thema einzusteigen, können Sie sich die Webinar-Aufzeichnung kostenlos ansehen. Klicken Sie hier, um sich zu registrieren.
Was ist Microsoft Fabric?
Microsoft Fabric ist eine cloudbasierte All-in-One-Analyseplattform, die eine einheitliche Umgebung für Datenexperten und Geschäftsanwender bietet, um gemeinsam an Datenlösungen zu arbeiten. Fabric bietet eine Suite integrierter Dienste, mit denen Sie Daten auf einer einzigen Plattform erfassen, speichern, verarbeiten und analysieren können, die auf Software-as-a-Service (SaaS) basiert.
Microsoft Fabric bietet Tools für Anwender aller Erfahrungsstufen im Datenbereich und lässt sich nahtlos mit den Tools verbinden, die Unternehmen für ihre Entscheidungsfindung nutzen.
Fabric selbst fungiert als Dach für die folgenden cloudbasierten Microsoft-Dienste, die das Microsoft-Analytics-Portfolio bilden:
- Azure Data Factory
- Azure Event Hubs
- Azure Data Explorer
- Azure Artificial Intelligence
- Azure Databricks
- Azure Synapse Spark Pools
- Azure Synapse Analytics
- and Microsoft Power BI
Die oben genannten Komponenten wurden innerhalb von Microsoft Fabric vollständig überarbeitet und auf ein neues Niveau gehoben.
Workloads of Microsoft Fabric
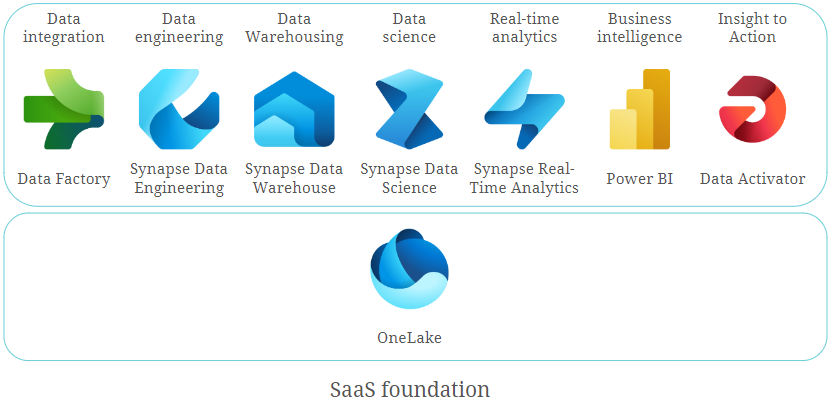
Fabric umfasst die folgenden Workloads und Experiences:
- Datenintegration
- Data Engineering
- Data Warehousing
- Data Science
- Real-Time Analytics
- Business Intelligence
- Insight to Action
Das Fundament dieser Experiences in Fabric ist der Data Lake, der als OneLake bezeichnet wird. Die folgende Abbildung veranschaulicht das Konzept von Microsoft Fabric.
Betrachten wir die einzelnen Komponenten von Fabric im Detail.
Datenintegration
Die Workload für Datenintegration in Microsoft Fabric, genannt Data Factory, bringt Datenbewegungsfunktionen sowohl in Dataflows als auch in Data Pipelines.
- Dataflows bieten flexible und benutzerfreundliche Möglichkeiten zur Transformation von Daten mit über 300 Transformationsoptionen. Sie basieren auf der vertrauten Power-Query-Experience, die in verschiedenen Microsoft-Produkten und -Diensten wie Excel, Power BI, Power Platform und anderen verfügbar ist.
- Data Pipelines ermöglichen es Ihnen, flexible Daten-Workflows zu erstellen, um Ihre organisatorischen Ziele zu erreichen. Sie können die integrierten Datenorchestrierungsfunktionen nutzen, um Ihre Dataflows zu aktualisieren, große Datensätze zu verarbeiten und komplexe Kontrollfluss-Pipelines zu definieren.
Data Engineering
Die Data-Engineering-Experience oder Synapse Data Engineering bietet eine erstklassige Spark-Plattform mit umfassenden Entwicklungsumgebungen. Dies ermöglicht es Data Engineers, umfangreiche Datentransformationen durchzuführen, und erleichtert den breiten Zugriff auf Daten über das Lakehouse.
Microsoft Fabric bietet verschiedene Data-Engineering-Funktionen, um sicherzustellen, dass Ihre Daten leicht zugänglich, gut organisiert und von hoher Qualität sind. Auf der Data-Engineering-Startseite haben Sie die folgenden Optionen:
- Lakehouse
Erstellen und Verwalten von Lakehouses. Ein Lakehouse ist ein logischer Speicherort in OneLake, an dem Sie strukturierte und unstrukturierte Daten mithilfe verschiedener Tools und Frameworks speichern und verwalten. Mit der Shortcut-Funktion können Sie sogar ein externes Speicherkonto in Ihr Lakehouse einbinden. Sie können den SQL-Endpunkt verwenden, um Lakehouse-Tabellen abzufragen, wobei dieser jedoch nur schreibgeschützte Abfragen unterstützt. - Notebook
Schreiben und Ausführen von Code in gängigen Programmiersprachen wie Python, R und Scala. Nutzen Sie Notebooks für die Datenerfassung, -transformation, -analyse und andere Datenverarbeitungsaufgaben. - Environment
Innerhalb eines Environments haben Sie die Flexibilität, aus einer Vielzahl von Spark-Runtimes zu wählen, Ihre Rechenressourcen zu konfigurieren und Bibliotheken zu integrieren, entweder aus öffentlichen Repositories oder durch das Hochladen lokal erstellter, benutzerdefinierter Bibliotheken. Die Zuweisung dieser Umgebungen (Environments) zu Ihren Notebooks und Spark-Jobdefinitionen ist ein nahtloser Prozess. - Spark-Jobdefinition
Definieren, planen und verwalten Sie Spark-Jobs, um Big Data in Ihrem Lakehouse zu verarbeiten, Transformationslogik auf die Daten anzuwenden und vieles mehr. - Data Pipeline
Entwerfen und orchestrieren Sie Pipelines, um Daten in Ihr Lakehouse zu kopieren, Spark-Jobs und Notebooks zur Verarbeitung großer Datenmengen zu planen und Daten-Workflows durch die Integration mit Data Factory zu automatisieren.
Data Warehousing
Das Data Warehouse oder Synapse Data Warehouse ist ein Lake-zentriertes Repository zur Speicherung und Analyse strukturierter Daten, das auf einer verteilten Verarbeitungs-Engine basiert. Die Data-Warehousing-Workload profitiert von den umfassenden Funktionen der SQL-Engine über ein offenes Delta-Lake-Format. Dabei handelt es sich um Parquet-Dateien, die als Delta-Lake-Logs veröffentlicht und in OneLake gespeichert werden. Delta-Lake-Logs ermöglichen ACID-Transaktionen. Ein Warehouse kann nur strukturierte Daten enthalten. Hier können Sie Daten mit SQL nicht nur lesen, sondern auch Schreib- und Aktualisierungsvorgänge (Inserts und Updates) ausführen.
Data Science
Die Data-Science-Experience oder Synapse Data Science ermöglicht die Erstellung, Bereitstellung und Operationalisierung von Machine-Learning-Modellen. Data Scientists werden in die Lage versetzt, Unternehmensdaten mit Vorhersagen anzureichern, und Business-Analysten können diese Vorhersagen direkt in ihre BI-Berichte integrieren. Data Science in Fabric bietet Ihnen die folgenden Optionen:
- ML-Modell
Nutzen Sie Machine-Learning-Modelle, um Ergebnisse vorherzusagen und Unregelmäßigkeiten in Datensätzen zu identifizieren. - Experiment
Steigen Sie in die Experimentierphase ein, indem Sie verschiedene Modelle erstellen, ausführen und deren Entwicklung überwachen, um Hypothesen zu validieren. - Notebook
Nutzen Sie die Notebook-Funktion, um in die Datenexploration einzutauchen und Machine-Learning-Lösungen über Apache-Spark-Anwendungen zu erstellen. - Environment
Diese Option dient demselben Zweck wie in der Data-Engineering-Experience.
Real-Time Analytics
Real-Time Analytics in Fabric oder Synapse Real-Time Analytics ist eine vollständig verwaltete Big-Data-Analyseplattform, die für Streaming- und Zeitreihendaten optimiert ist. Sie nutzt die Kusto Query Language (KQL), eine Engine mit außergewöhnlicher Performance für die Suche in strukturierten, semistrukturierten und unstrukturierten Daten. Real-Time Analytics ist vollständig in die gesamte Palette der Fabric-Produkte für Datenlade-, Datentransformations- und erweiterte Visualisierungsszenarien integriert. Es gibt drei Komponenten von Real-Time Analytics in Fabric:
- KQL-Datenbank
Der Ort zum Speichern von Streaming-Daten. Sie nutzt OneLake als zugrunde liegendes Speichersystem. - KQL-Queryset
Führen Sie Abfragen auf Ihren Daten aus, um teilbare Tabellen und Visualisierungen zu erstellen. Speichern, verwalten, exportieren und teilen Sie KQL-Abfragen. Ein KQL-Queryset ist das Pendant zu SSMS für eine SQL-Datenbank. - Eventstream
Erfassen, transformieren und leiten Sie Echtzeit-Event-Streams im gewünschten Format an verschiedene Ziele weiter, ganz ohne Programmieraufwand (No-Code). Es ist eine zentrale Drehscheibe für Streaming-Daten, an der mehrere Quellen (einschließlich Event Hub) und verschiedene Ziele (einschließlich KQL-Datenbank) eingerichtet werden können.
Business Intelligence
Auf der BI-Seite bietet Fabric mit Power BI eine der weltweit führenden Business-Intelligence-Plattformen. Power BI vereint eine Reihe von Diensten, Tools und Konnektoren, die Ihre Daten in interaktive visuelle Berichte und Dashboards verwandeln. In Fabric gibt es einige neue Funktionen und Erweiterungen für die Arbeit mit Fabric-Objekten und -Experiences. Dazu gehören:
- Der Direct-Lake-Modus, eine Verbindung, die auf dem direkten Laden von Dateien im Parquet-Format aus einem Data Lake basiert, ohne dass die Daten in ein Dataset importiert werden müssen.
- Die Integration mit Synapse Real-Time Analytics zur Erstellung von Berichten nahezu in Echtzeit.
- Semantic Link, der das Laden von Daten aus Power-BI-Datasets in die Data-Science-Experience und andere Umgebungen ermöglicht..
Insight to Action
Insight to Action in Fabric bietet den Data Activator, eine Experience zur automatischen Auslösung von Aktionen, sobald bestimmte Bedingungen in den eingehenden Daten erfüllt sind. Der Data Activator arbeitet mit Eventstreams für Echtzeitdaten und mit Power BI für Batch-Daten. Es gibt drei mögliche Aktionen, die nach dem Erkennen der Bedingungen konfiguriert werden können:
- E-Mail: Lassen Sie sich per E-Mail benachrichtigen.
- Teams-Nachricht: Senden Sie eine Benachrichtigung an eine Person oder einen Kanal in Teams.
- Benutzerdefinierte Aktion: Führen Sie eine benutzerdefinierte Aktion aus, um einen Power-Automate-Workflow aufzurufen.
Data Lake
OneLake ist die zentrale Komponente aller Fabric-Dienste. Es ist ein integrierter, einheitlicher Data Lake, der alle Organisationsdaten speichert und von allen Fabric-Experiences genutzt wird. OneLake verwendet ADLS Gen2 als zugrunde liegenden Speicher.
Um die Verwaltung im gesamten Unternehmen zu vereinfachen, ist OneLake hierarchisch organisiert. Jeder Tenant besitzt genau eine OneLake-Instanz, die einen einzigen Namensraum bereitstellt, der sich über Benutzer, Regionen und sogar Clouds erstreckt. Zur einfachen Handhabung sind die Daten in OneLake in überschaubare Container unterteilt.
Ähnlich wie bei Microsoft OneDrive kann jeder Entwickler oder jede Geschäftseinheit innerhalb des Tenants eigene Arbeitsbereiche (Workspaces) in OneLake erstellen. Sie können Daten in ihre eigenen Lakehouses laden und mit der Verarbeitung, Analyse und gemeinsamen Bearbeitung der Daten beginnen. Alle Fabric-Experiences sind an OneLake gebunden und arbeiten darauf aufbauend.
Welche Potenziale bietet Microsoft Fabric also?
Microsoft Fabric hat das Potenzial, die Art und Weise, wie Unternehmen Business-Intelligence-Lösungen entwickeln und bereitstellen, grundlegend zu verändern. Hier sind einige der wichtigsten Aspekte:
- Einheitliche Datenplattform: Microsoft Fabric bietet eine einheitliche Datenplattform für die Speicherung und Analyse aller Datentypen, einschließlich strukturierter, semistrukturierter und unstrukturierter Daten. Dies bedeutet, dass Unternehmen ein einziges Toolset nutzen können, um alle Aspekte ihrer Datenpipeline zu verwalten – von der Datenerfassung und -aufbereitung bis hin zur Datenanalyse und -visualisierung. Dies trägt maßgeblich dazu bei, die Komplexität zu reduzieren und die Effizienz zu steigern.
- End-to-End-Analysen: Microsoft Fabric bietet ein vollständiges Spektrum an Funktionen für die Erstellung und Bereitstellung von End-to-End-Analyselösungen. Dies umfasst Data Engineering, Data Science, Data Warehousing und Business Intelligence. Dies vereinfacht die Entwicklung sowie Bereitstellung von Analyselösungen und reduziert den Bedarf an spezialisiertem Fachwissen.
- KI-gestützte Erkenntnisse: Microsoft Fabric integriert KI- und Machine-Learning-Funktionen auf der gesamten Plattform. Diese können genutzt werden, um Aufgaben zu automatisieren, Erkenntnisse zu generieren und die Genauigkeit von Vorhersagen zu verbessern. So können Unternehmen schneller fundierte Entscheidungen treffen.
- Eine einheitliche Plattform für unterschiedliche Fachbereiche: Datenexperten mit verschiedenen Hintergründen können ihre Fähigkeiten einbringen, um gemeinsam an einer einzigen Datenlösung zu arbeiten. Diese integrative Umgebung ermöglicht es Personen aus unterschiedlichen Disziplinen und mit verschiedenen Qualifikationsstufen, ihr Fachwissen in ein gemeinsames Datenprojekt einzubringen.
- Reduzierung von Datensilos: Da Daten nicht mehr zwischen verschiedenen Systemen verschoben werden müssen, wird eine ganzheitliche Sicht auf das Unternehmen erheblich erleichtert.
- Kostensenkung: Microsoft Fabric hilft Unternehmen dabei, die mit der Entwicklung und Bereitstellung von Business-Intelligence-Lösungen verbundenen Kosten zu senken. Da die Anschaffung und Wartung mehrerer Einzelsysteme entfällt, wird eine Reihe von Funktionen bereitgestellt, die Aufgaben automatisieren und die Effizienz steigern können.
Im Wesentlichen verspricht Microsoft Fabric, die Entwicklung und Bereitstellung robuster Business-Intelligence-Lösungen zu vereinfachen und sie für Unternehmen jeder Größenordnung zugänglicher und kostengünstiger zu machen.
Fazit
Microsoft Fabric stellt einen Paradigmenwechsel im Bereich der Business-Intelligence-Lösungen dar. Mit seiner einheitlichen Datenplattform, den End-to-End-Analysefunktionen und den KI-gestützten Erkenntnissen optimiert Fabric das Datenmanagement von der Erfassung bis zur Visualisierung. Die Fähigkeit der Plattform, verschiedene Fachbereiche und Kompetenzen zusammenzuführen, Datensilos zu reduzieren und Aufgaben zu automatisieren, verdeutlicht das bemerkenswerte Potenzial, die Branche nachhaltig zu revolutionieren.
Durch seine Komponenten wie Data Factory, Data Engineering, Data Warehousing, Data Science, Real-Time Analytics, Power BI, Data Activator und das solide Fundament von OneLake verspricht Microsoft Fabric eine Zukunft, in der Unternehmen die Macht der Daten effizient nutzen können, um fundierte Entscheidungen zu treffen und Innovationen voranzutreiben. Letztendlich hat es das Potenzial, leistungsstarke Business-Intelligence-Lösungen zu demokratisieren und sie für Unternehmen aller Größenordnungen zugänglicher und wirtschaftlicher zu machen.