Data Migration
Data migration is a complex process that requires careful planning and execution. Understanding the data landscape, ensuring minimal downtime, managing stakeholder expectations, and most importantly, maintaining the integrity and security of your data throughout the transition are critical. Failing to address these factors can lead to data loss, corruption, or non-compliance with regulatory standards, which can have significant business implications. In a worst-case scenario, stakeholders may notice data issues before the data team does, decreasing trust in the data and the team. Another potential problem, having to work overtime because of data issues which were not noticed before.
Features embedded within dbt (Data Build Tool) and tools like Great Expectations offer powerful solutions to help organizations manage these risks, ensuring that the data remains reliable and compliant as it moves through the migration process.
Ensuring Data Accuracy and Compliance During a Migration: Leveraging dbt and Great Expectations
This webinar will cover the essential aspects of maintaining data accuracy and compliance throughout the data migration process. We will explore how dbt (Data Build Tool) enables robust data transformation with built-in and custom tests, ensuring data integrity at each stage. Additionally, we will demonstrate how Great Expectations enhances data validation, allowing you to enforce specific rules and expectations, ensuring a smooth and secure migration with minimal risk of errors or inconsistencies.
Leveraging dbt for Data Accuracy
A powerful tool for data transformation: dbt enables teams to build, test, and document data pipelines. By utilizing its features, such as tests and contracts, dbt ensures data consistency and accuracy. We’ll explore these capabilities in detail below.
dbt offers two ways to define tests, singular and generic data tests.
- Singular data tests: Custom SQL query that is written to test a specific condition or logic in the data. It is highly tailored to a particular use case or business logic. In essence, it’s a standalone test where the developer writes custom SQL to check for specific data anomalies or inconsistencies.
- Generic data tests: Pre-defined and reusable tests that can be applied to multiple models or columns across different datasets.
Examples of Generic Tests:
- Unique Tests: Ensure that a field in your dataset contains unique values, which is critical for primary key fields
- Not Null Tests: Validate that a field does not contain any null values
- Referential Integrity Tests: Checks that foreign key relationships are maintained, ensuring consistency across related tables
- Accepted values: Useful tests for columns which receive predictable data
Tests can be configured to: either fail (severity: error) or issue a warning (severity: warning). Conditional expressions such as error_if and warn_if can refine this behavior, e.g., triggering a warning only after a certain number of failures.
dbt Contract enforcement
- Enforces that dbt model schemas adhere to predefined data structures
- Defines specific columns, data types, and constraints (e.g., not null, unique)
- Raises errors before materializing the model as a table, allowing identification of schema issues
Pro-tip for data migrations: use incremental models to update only new or modified records, which improves efficiency and avoids full table rebuilds. When enforcing a contract, the “append_new_columns” option is useful as it retains old columns, minimizing issues. The “sync_all_columns” setting is particularly handy for automatically adjusting the schema by adding new columns and removing missing ones, making it ideal for migrations with frequent renaming.
dbt-expectations vs Great Expectations
dbt-expectations integrates data quality tests into dbt, while Great Expectations provides a broader framework for managing data validation across various sources. Together, they enhance data accuracy and reliability.
dbt-expectations
The dbt-expectations package extends dbt’s testing capabilities by providing a collection of pre-built, customizable data quality tests inspired by Great Expectations. This package helps automate and standardize data quality checks across multiple models, ensuring that datasets meet specific expectations before they are used in downstream processes.
Here are some examples of data quality tests you can run using the dbt-expectations repository (we are going to cover more in the webinar):
- Expect_column_values_to_match_regex: Verifies that all values in a column match a given regular expression pattern
- Expect_column_median_to_be_between, expect_column_min_to_be_between, expect_column_max_to_be_between: Ensures numeric column values fall within specified ranges
- Expect_column_pair_values_a_to_be_greater_than_b: Checks that values in one column are greater than values in another
Why Consider Integrating Great Expectations?
With dbt-expectations providing robust testing within a single dbt project, you might wonder why you’d want to integrate Great Expectations. Here’s why:
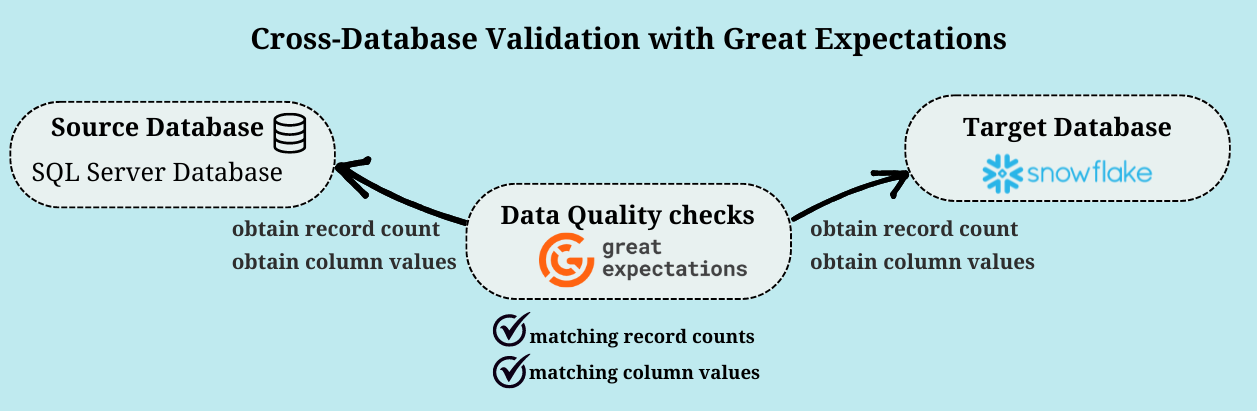
- Cross-Database Comparisons: dbt-expectations works well within a single SQL-based data warehouse. However, if you need to compare data across different databases (like Snowflake and SQL Server), Great Expectations offers a broader solution.
- Broader Data Validation: Great Expectations supports multiple data sources, including CSV, Parquet, JSON, APIs, and various SQL databases. It provides a flexible and user-friendly platform to define, manage, and execute data quality tests across diverse sources.
Key Features of Great Expectations:
- Data Profiling: Before starting your migration, use GE to profile your data and set expectations based on its current state.
- Detailed Validation Reports & Dashboards: GE offers comprehensive reports and visualizations, outputting results in formats like HTML, Slack, JSON, and Data Docs. This enhances transparency and provides deeper insights for both technical and non-technical stakeholders.
- Customizability and Extensibility: GE allows you to define custom expectations tailored to your data pipeline and integrate with other testing libraries.
- Version Control & Historical Validation: Track changes in data quality over time with version control, helping to identify trends and recurring issues.
- Production Monitoring & Integration: Integrate GE with data orchestration tools like Airflow, Prefect, or Dagster to incorporate data quality checks into your broader workflows, including those not managed by dbt.
Integrating Great Expectations with dbt
Great Expectations complements dbt by offering a flexible platform for data validation beyond single-project scenarios. By integrating GE with dbt, you can achieve a more comprehensive approach to data quality, ensuring your migration process is as smooth and reliable as possible.
In the upcoming webinar, we will explore practical examples of dbt tests, dbt-expectations, and Great Expectations validations, so stay tuned!