Branching Strategies
Branching strategies are one of those topics that rarely get much attention until they suddenly become a problem. Whether it’s drowning in merge conflicts, the headache of implementing and synchronizing hotfixes across multiple branches, or a feature freeze caused by insufficient quality assurance, your repository and branching structure can have a major impact on day-to-day development.
But what branching strategies actually exist, and what are their pros and cons? Which approach allows you to deploy changes most quickly? And how can you maintain high software quality despite frequent releases?
In this article, we’ll provide a structured overview of common branching strategies and typical challenges developers face when using them.
Navigating Git Workflows in Modern DevOps
This webinar offers a clear overview of common approaches and how they impact CI/CD, code quality, and maintainability. Beyond theory, we’ll dive into practical challenges and real-world issues teams face every day. Register now for our free webinar on September 16th, 2025!
Why Are Branching Strategies Relevant?
Branching models reflect the organization, release culture, and technical maturity of a project. There is no single “correct” strategy that fits every project. Choosing the right one depends heavily on the project’s context. Some of the most important questions to consider when selecting a branching strategy include:
- Does the team work in fixed sprint or release cycles, or is code deployed continuously?
- How many developers are working simultaneously on the same codebase?
- What is the quality of your CI/CD pipeline? Does every change need a manual review, even if the pipeline passes, or can it be deployed automatically?
Depending on the answers to these questions, a simple or more complex branching strategy may be appropriate.
Comparison of Common Strategies
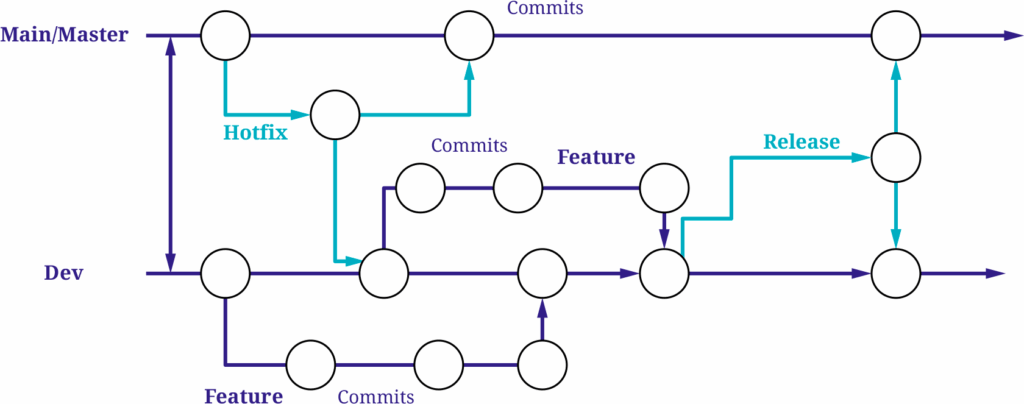
Git Flow
The Git Flow strategy was originally developed for traditional software projects with planned release cycles. Its long-lived main branches are “main” (or “master”) and “dev”.
In addition, it introduces several short-lived branches:
Feature branches
New features are developed in separate feature branches, which are merged into the develop branch once completed.
Hotfix branches
If a critical bug occurs in the production environment (i.e., on the main branch), a hotfix branch is created from main to address the issue. Once the fix is implemented and pushed to the hotfix branch, it is merged into both main and develop to ensure the bug is resolved in both branches.
Release branches
When a release is approaching, a release branch is created from develop, containing all features added since the last release. This branch is then used for final QA testing, bug fixing, and versioning. Once the release is approved, the release branch is merged into both main and develop.
The main advantage of Git Flow is its clear structure. Even in larger teams with many developers and therefore multiple concurrent feature branches, it’s easy to track which version is in what state. The strategy supports parallel development very well due to its structured branching model.
However, the downside is the organizational and technical overhead. The large number of branches and merges can lead to conflicts and divergence over time, especially with long-lived release and hotfix branches. A particular challenge arises when keeping branches in sync. Hotfixes created from main need to be merged back into main and dev, and changes made in release branches, which originate from dev, must eventually be merged into both main and dev, as shown in the diagram. These synchronization steps often introduce additional effort and increase the risk of conflicts or inconsistencies, especially when multiple streams of work are active in parallel.
Additionally, the path a feature must take, from a feature branch to develop, to a release branch, and finally to main, can slow down the deployment process.
While a solid CI/CD pipeline can help automate and streamline parts of this workflow, Git Flow does not rely on automation to function. This makes it especially suitable for teams with more manual QA processes or limited automation infrastructure.
GitHub Flow
Compared to Git Flow, the GitHub Flow strategy is significantly leaner. It uses only a single long-lived branch, usually main, and temporary feature branches that are merged via pull requests.
Once all changes on a feature branch are complete and have passed review and various tests, the branch is merged directly into main.
The key advantage of GitHub Flow is its simplicity. There are no separate release or develop branches, and even hotfixes can be handled in short-lived branches. Teams can respond to changes quickly and deploy frequently. This agility is especially effective when supported by a robust CI/CD pipeline. If properly implemented, testing, building, and deployment processes are automated, further improving GitHub Flow’s fast time to market.
Because of its low complexity and minimal coordination overhead, GitHub Flow is also particularly well-suited for smaller teams that value speed and iteration over rigid release planning.
If you’re interested in how such pipelines are structured in practice, our CI/CD pipeline Blog article offers a look at a practical GitHub-based setup using GitHub Actions and dbt. It’s a useful companion piece for understanding the automation layer that supports fast and reliable delivery.
However, this strategy also comes with limitations: it doesn’t support managing multiple parallel versions or complex release planning.
Additionally, it relies heavily on the quality of the CI/CD pipeline.
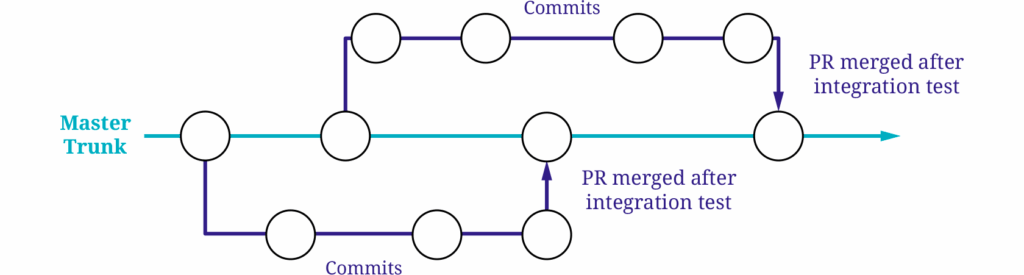
Trunk-Based Development
Trunk-Based Development is quite similar to the GitHub Flow strategy, but there are a few key differences.
While it also relies on a single long-lived branch (the trunk, typically main), commits are either made directly to main or via very short-lived feature branches. These feature branches often exist for only a few hours, and it’s common for changes to be merged into main multiple times a day. The goal is to integrate changes as early as possible to avoid conflicts before they even arise.
Because there are no fixed release cycles in Trunk-Based Development, it’s essential to ensure that incomplete features don’t go live prematurely. Feature flags play a central role here, allowing unfinished functionality to be hidden in the production environment until it’s ready.
As with GitHub Flow, a strong CI/CD pipeline is essential. It acts as the main safeguard for quality assurance and enables rapid deployment to the main branch.
Trunk-Based Development is especially effective for teams that are comfortable with rapid iteration and a high level of automation. While it can be used by smaller teams, it truly shines in larger organizations where multiple teams work in parallel and frequent integration is critical to maintaining momentum and consistency.
The benefits of Trunk-Based Development include extremely fast deployments and minimal risk of merge conflicts due to the short-lived nature of branches and continuous integration.
However, similar to GitHub Flow, this strategy heavily depends on the reliability of the CI/CD pipeline. If your team operates in a highly automated DevOps environment, this approach works smoothly. But if that’s not the case, software quality can suffer significantly. The risk is especially high here, as all changes are deployed directly to the main branch.
Conclusion
All three strategies come with their own strengths and weaknesses.
Git Flow is well-suited for larger projects with fixed release cycles, manual QA, and structured approval processes. It offers stability and clear workflows, but also brings significant technical and organizational overhead, making it a heavyweight option that can slow down development and release cycles due to its complexity and synchronization requirements.
GitHub Flow, by contrast, emphasizes speed and simplicity. It’s an excellent fit for smaller teams working on web or SaaS projects that deploy continuously, thanks to its low complexity and quick turnaround. But it relies on a good CI/CD pipeline. If tests are insufficient, faulty code might get deployed automatically.
Many of these risks can be mitigated with proper pipeline design and DevOps experience within the team, ensuring that automation is not just fast but also reliable.
Trunk-Based Development enables the highest release frequency, but only delivers consistent quality if the necessary technical maturity is in place. This makes it ideal for highly automated environments where teams ship many changes every day.
There are always ways to mitigate or minimize the downsides of any branching strategy. Techniques like blue/green or canary deployments, for example, can help reduce the impact of faulty changes and make rollbacks easier.
Stay tuned, we regularly share practical insights and solutions on topics like CI/CD, DevOps patterns, and deployment strategies.