The Business Value of Data Vault
Data Vault is not just another data model. It’s a pragmatic architecture and methodology built for change, auditability, automation and fast delivery — and those traits translate directly into measurable business advantages compared with traditional approaches or doing nothing at all.
Why we need a different approach to data
Most organisations don’t start with the perfect, governed data platform. They begin with spreadsheets, a few scripts, maybe a single operational system. Then the business grows: new SaaS apps (Salesforce, shop platforms), partner APIs, IoT feeds, regulatory requirements and ad-hoc reporting requests. Before long you have multiple sources, inconsistent definitions, and changing business rules.
Traditional models — Kimball’s star schemas or Inmon’s normalized enterprise warehouse — work well when sources, rules and requirements are stable. But the reality today is constant change. That’s exactly the gap Data Vault was designed to fill: a model and architecture focused on capturing raw facts reliably, separating business logic, and enabling incremental, auditable growth.
High-level difference: Data Vault vs. traditional models (or none)
Put simply:
- Traditional models (Kimball/Inmon): great for reporting, intuitive star schemas for business users, but rigid and costly to change when sources or rules evolve.
- No model / ad-hoc reports: fastest at day zero but leads to duplicated effort, inconsistent numbers, and brittle scripts that break as systems change.
- Data Vault: engineered for change. Capture everything in a consistent, standard way, keep full lineage, and build business logic and reporting layers on top. This structure enables automation, auditability and rapid delivery of real business reports.
Concrete business advantages of implementing Data Vault
1. Faster time-to-value (Tracer-bullet delivery)
Data Vault enables an iterative “tracer bullet” approach: pick a high-value report, identify the raw source data, ingest and model only what’s needed to deliver that report end-to-end. Business users get a working dashboard in weeks (not months), giving immediate value, generating trust, and allowing the team to expand incrementally.
2. Built-for-change — lower cost of future change
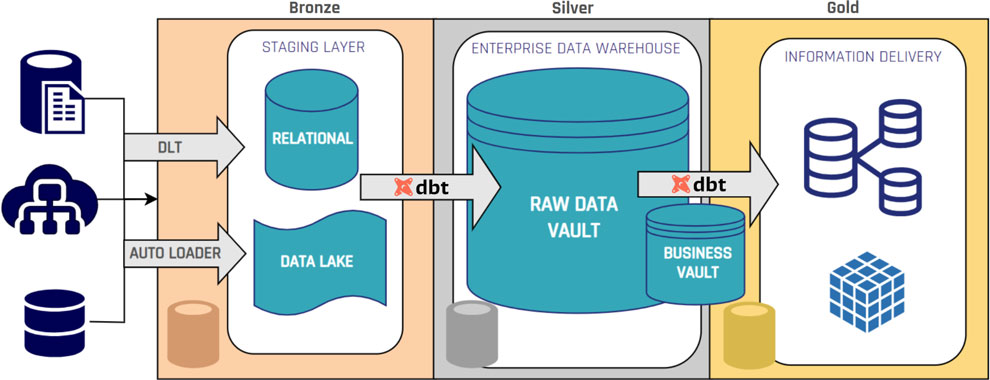
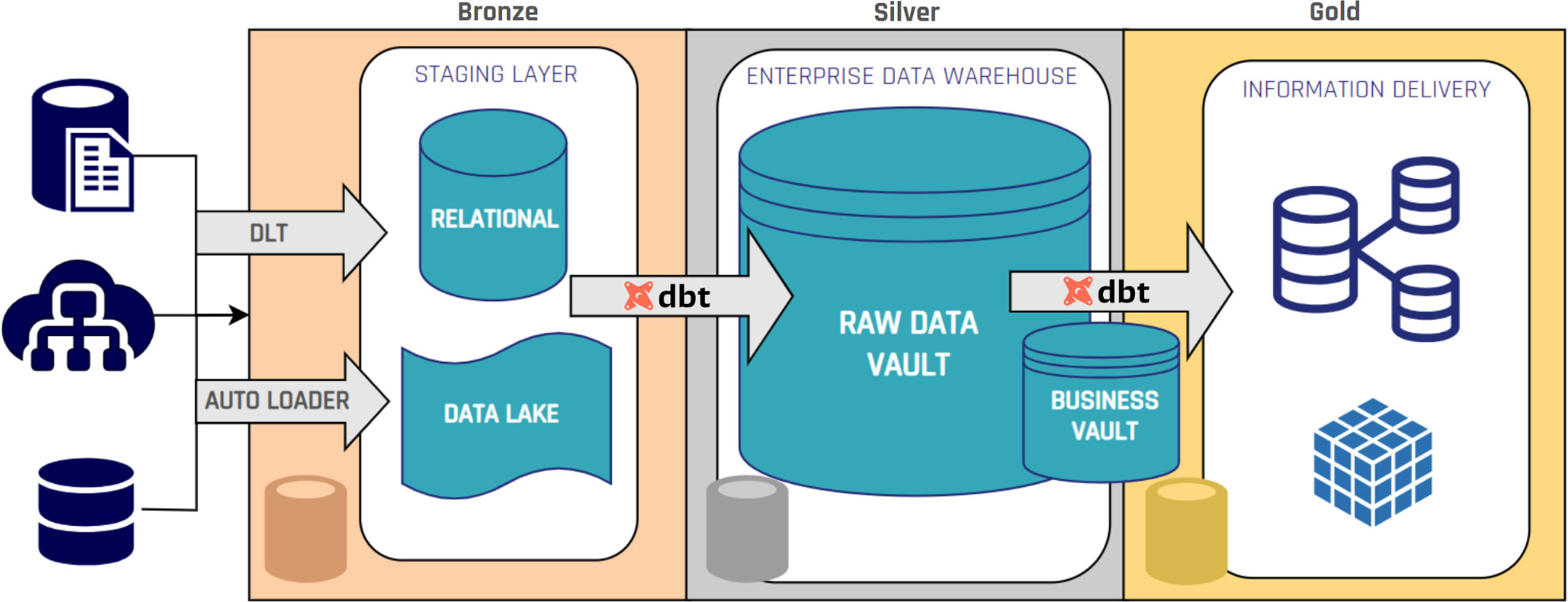
Because Data Vault separates raw data (hubs, links, satellites) from business rules (Business Vault / information marts), adding a new source, new attribute, or updated business rule rarely requires tearing down and rebuilding existing models. That translates into lower rework, lower maintenance costs, and much faster onboarding of new systems.
3. Automation reduces delivery time and human error
Data Vault entities follow standardized patterns. Hubs look alike; satellites follow the same tracking patterns. That repeatability makes the ingestion and loading processes highly automatable with modern tools (for example, dbt builders, Wherescape-style automation, Coalesce). Automation frees developers to focus on business logic instead of tedious ETL plumbing — more predictable pipelines, fewer bugs, faster delivery.
4. Auditable, traceable data for compliance and trust
Every record in a Data Vault carries load dates, record source identifiers, and historical versions. That full lineage is invaluable for audits, GDPR/DSR processes, finance reconciliations and provenance requirements for AI. When regulators or internal auditors ask “where did this number come from?” you can show the full trail back to source.
5. Future-proof architecture for analytics and AI
Data Vault’s decoupling of raw capture from business logic means you can adopt new storage or compute technologies (data lakes, cloud object stores, NoSQL or streaming platforms) without reworking the core model. It’s an architecture that scales with both data volume and analytics sophistication: data science teams can access the raw, auditable records they need without breaking downstream reporting.
6. Reduced risk and predictable governance
Standardized patterns, auditable history and clear separation of concerns improve governance. Data owners can define rules in a separate layer, compliance teams can inspect lineage, and operations can automate quality checks. That lowers operational risk and makes governance predictable rather than ad-hoc.
Specific business problems Data Vault can solve
Below are concrete problems organisations experience — and how Data Vault addresses them.
- M&As and rapid source expansion: After an acquisition you must onboard dozens of new systems. Data Vault lets you ingest raw records quickly and map business rules later, so analytics can start immediately without delaying integration for perfect master data alignment.
- Conflicting definitions across departments: Different teams report different revenue numbers. With Data Vault you capture every source event and build reconciled information marts, so one canonical report can be produced while source-level values remain auditable.
- Regulatory or audit requests: Need to prove how a figure was derived six months ago? Data Vault’s lineage (load timestamps, record source) shows exactly which source values contributed to any derived metric.
- GDPR / Data Subject Requests: Because raw values and their sources are stored with provenance, it’s easier to locate and isolate personal data, show retention windows, or delete/segment records if needed.
- AI/ML model drift and explainability: Models need defensible inputs. Data Vault keeps the raw inputs and transformation history separate, so feature engineers and auditors can trace which raw values produced a model input.
- Slow BI delivery and constant rework: BI projects where every change requires a model rewrite burn budget. Data Vault’s incremental approach reduces rework and keeps BI teams delivering incremental, reliable reports.
- Operational reporting vs historical analytics conflict: Operational needs often demand current-state views; analytics wants full history. Data Vault stores full history by design, while downstream information marts can present both current and historical perspectives appropriately.
How the business benefit translates to measurable outcomes
Organisations that adopt Data Vault commonly see measurable improvements such as:
- Shorter lead times for report delivery (weeks vs months for new reports).
- Lower total cost of ownership because changes require less rework and are more automatable.
- Fewer data incidents and faster root-cause analysis because lineage is built-in.
- Stronger compliance posture and faster audit responses.
- Better support for analytics and AI initiatives — because data scientists get consistent, traceable raw data.
These translate to business outcomes: faster decisions, less risk, better regulatory positioning, and a higher ROI on analytics investments.
Practical adoption path — a pragmatic recipe
You don’t have to flip the switch for everything at once. A typical, low-risk path is:
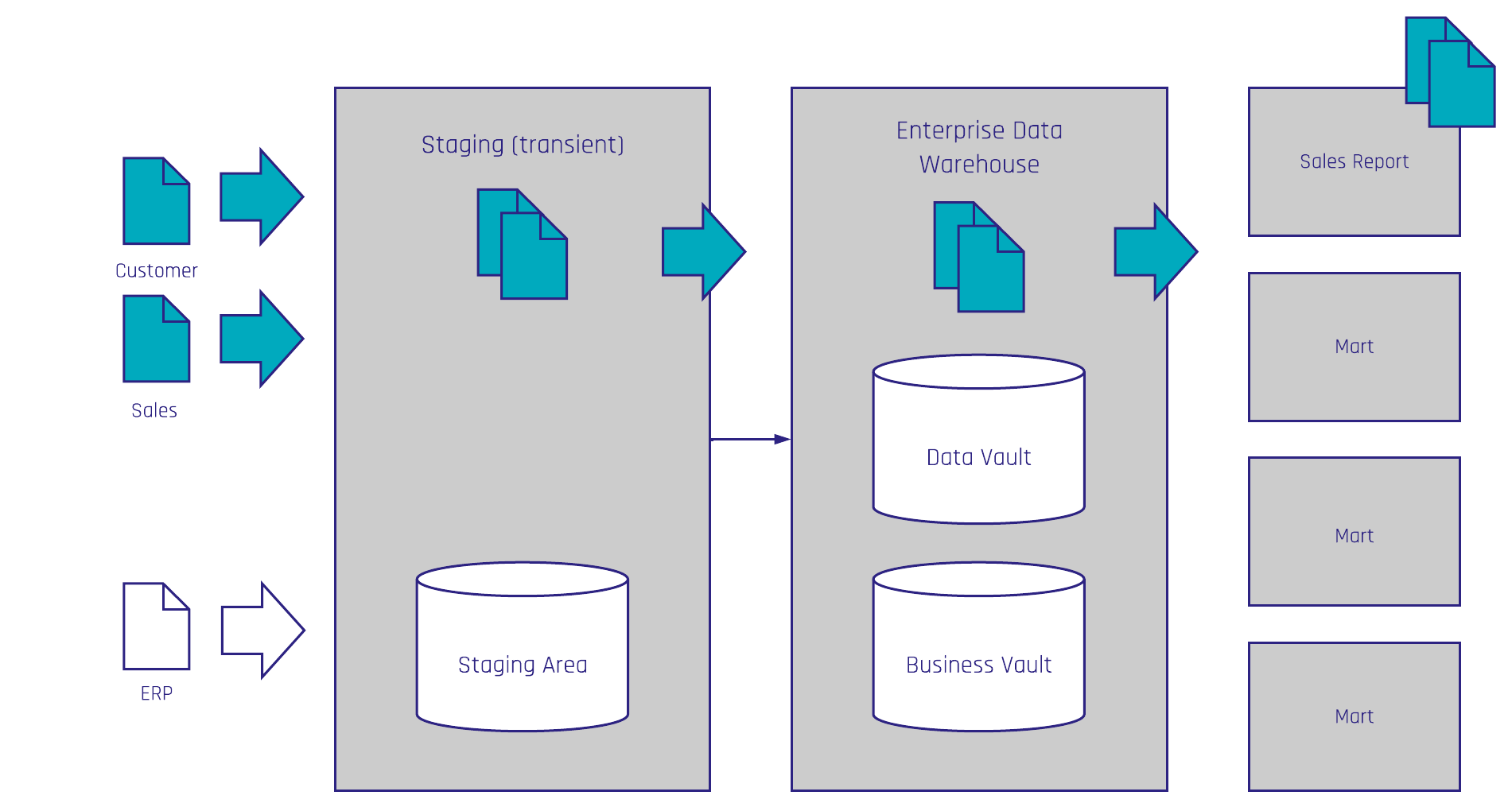
- Choose one high-value report (the tracer bullet). Identify required sources and ingest the raw records into the Raw Vault.
- Build the Business Vault where you apply the business rules for that specific report (transformations live here, not in the raw zone).
- Deliver an Information Mart tuned for reporting (star schema if that’s what BI needs) that offers the business an immediate, usable report.
- Iterate and scale — add more reports and sources, reuse existing Hubs/Links/Satellites, automate loading patterns and apply governance over time.
This approach gives quick wins, builds trust, and progressively modernises your data landscape without huge upfront modelling effort.
When Data Vault might be overkill
Data Vault is powerful, but it’s not always necessary. If you’re a very small organisation with a single system, little change, and a handful of reports, a simple star schema or a few curated data marts could be more pragmatic. Evaluate:
- Number of sources and expected change rate
- Regulatory/audit requirements
- Scale of historical data needs
- Long-term analytics and AI ambitions
If those requirements are modest today but expected to grow, Data Vault often makes sense as a future-proofing step you can introduce incrementally.
Final thoughts — why business leaders should care
At the executive level, Data Vault should be evaluated not as a modeling fad but as an investment in enterprise agility, compliance and scalable analytics. The technical patterns (hubs, links, satellites) map directly to business outcomes: rapid delivery of trusted reports, reduced change costs, auditable provenance, and a platform ready for advanced analytics and AI.
Compared to doing nothing (ad-hoc scripts) or building a rigid, monolithic warehouse, Data Vault gives you a repeatable way to capture everything, govern it, and build the business-facing outputs that actually create ROI.
If you’re considering a modern data platform, start with a tracer-bullet use case, prove the approach, automate the repeatable parts, and keep the focus on business outcomes rather than perfect modelling up front.