The Essential Data Vault Glossary
Data Vault has its own precise vocabulary. Whether you are evaluating the methodology for the first time or preparing for Data Vault certification, understanding what each term means — and why it exists — is the foundation for everything else. This glossary covers the core concepts of Data Vault 2.0 and 2.1, defined at the conceptual level for data engineers, architects, and IT leaders building or modernising a data platform.
In this article:
Business Key
A business key is the identifier that the business actually uses to recognise and track a business object — a customer number, a product code, an account number, an ISBN. It is the natural, meaningful key that appears in source systems and that business users refer to in their daily work.
In Data Vault, the business key is the fundamental organising principle of the entire model. Every Hub is built around business keys. The goal is to find keys that are unique across the enterprise and stable over time — keys that different source systems share, enabling integration between them.
Business keys sit above surrogate keys (technical IDs generated by a source system). A surrogate key is unique within one system but carries no meaning outside it. A business key has meaning across the organisation, making it suitable for integration. The hierarchy runs from global business keys (universally unique, like a Vehicle Identification Number), through organisational business keys (assigned by the enterprise, like a customer number), down to system-wide surrogate keys where no better option exists.
Hub
A Hub is one of the three fundamental entity types in Data Vault. It stores a distinct list of business keys for a single type of business object — all customer numbers, all product codes, all account numbers. The Hub identifies. It records which business keys have ever existed in the data platform, alongside when they were first seen (the load date) and where they came from (the record source).
The Hub does not describe anything about the business object — that is the Satellite’s job. It does not store relationships — that is the Link’s job. A Hub is insert-only: once a business key is recorded, it is never updated or deleted (except under legal obligation). This permanence is what makes Data Vault historically complete.
Link
A Link is the second fundamental entity type. It stores a distinct list of relationships between business keys — the fact that a customer purchased a product, that an employee was assigned a vehicle, that a booking involved a passenger and a flight. Like the Hub, the Link is insert-only and records when the relationship was first identified and from which source.
The Link does not describe the relationship — it only establishes that it existed. All descriptive information (when it started, when it ended, what conditions applied) lives in Satellites attached to the Link. Importantly, Links can connect more than two Hubs: a purchase transaction might link a customer, a product, and a store simultaneously. This is entirely normal in Data Vault design.
Satellite
A Satellite is the third fundamental entity type, and where the actual data warehousing happens. It stores descriptive data — the attributes that describe a business object or relationship over time. A customer’s name and address. A product’s description and list price. The start and end dates of an employment contract.
Every time an attribute changes in the source, a new row is inserted into the Satellite. No rows are ever updated. This insert-only behaviour is what gives Data Vault its complete historical record. Each Satellite has exactly one parent — either a Hub or a Link — and Satellites are typically split by source system, by security or privacy classification, and sometimes by rate of change.
The combination of Hub, Link, and Satellite reflects the three fundamental components present in all enterprise data: business keys, relationships, and descriptive attributes. For a deeper treatment of how these entities are modelled and loaded, Data Vault 2.1 Training & Certification covers the full methodology in detail.
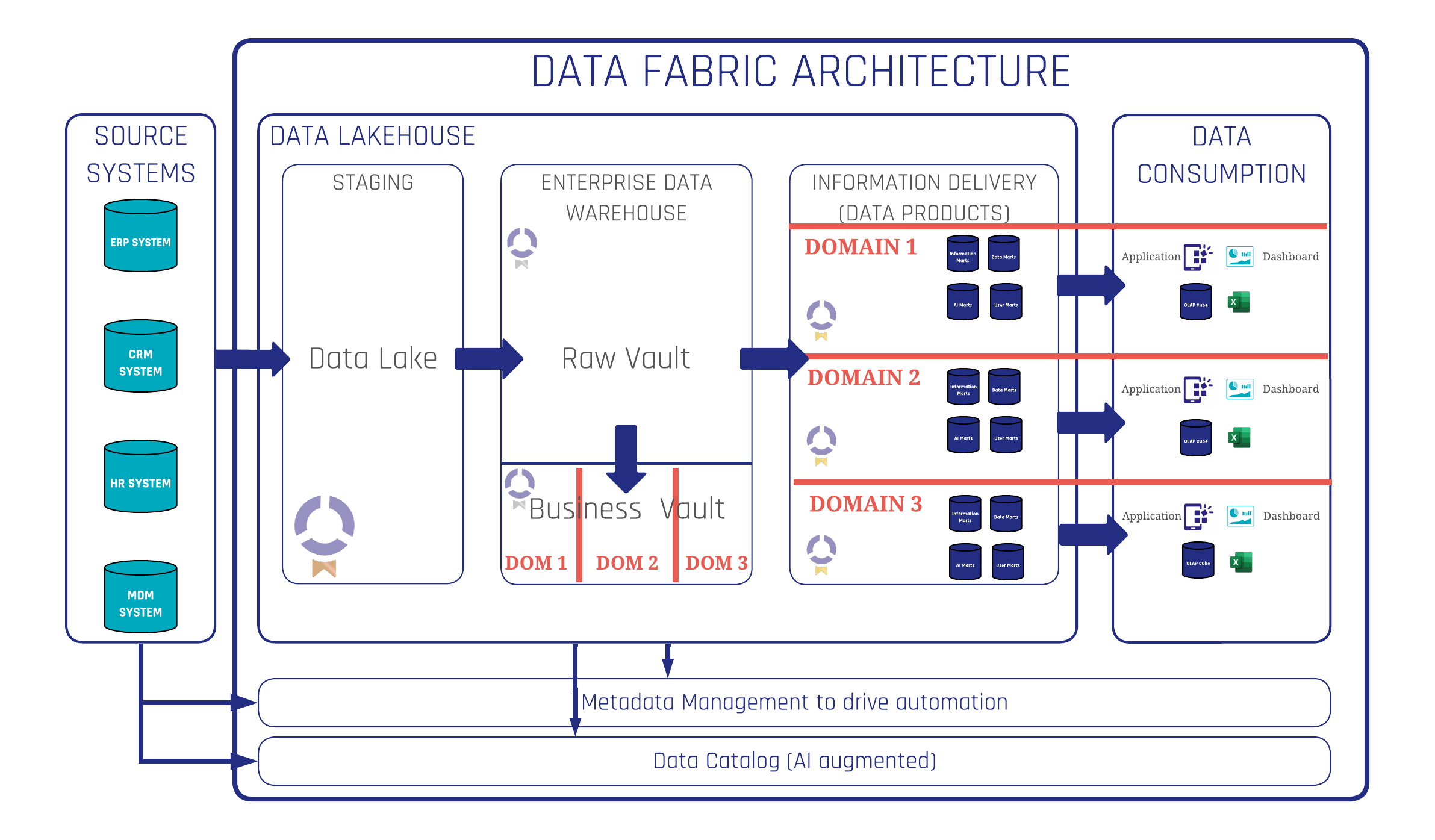
Raw Vault
The Raw Vault (also called the Raw Data Vault) is the layer of the Data Vault architecture that stores unmodified source data. It consists of Hubs, Links, and Satellites that capture data exactly as it arrived — no cleansing, no business rules, no filtering, no conditional logic of any kind.
The Raw Vault is the single point of facts. Because no business interpretation has been applied, the data it holds is fully auditable: you can demonstrate precisely what any source system delivered on any given date. This auditability is one of the primary reasons Data Vault is adopted in regulated industries such as banking, insurance, and government.
Business Vault
The Business Vault is the layer above the Raw Vault where business logic is applied. It uses the same Hub-Link-Satellite structures, but its purpose is to transform and enrich the raw data — cleansing records, resolving duplicates, applying currency conversions, tagging data quality levels, and deriving calculated attributes.
The Business Vault is not a mandatory pass-through layer. Data that is already clean and ready for reporting can flow directly from the Raw Vault to an Information Mart. In practice, organisations typically maintain multiple Business Vault schemas — one per department or domain — each expressing the business rules and definitions relevant to that context. This is how Data Vault delivers multiple versions of the truth from a single set of facts: different teams can apply their own definitions without touching the shared Raw Vault underneath. Learn more about the full Data Vault 2.0 methodology and how Scalefree applies it in client projects.
Information Mart
An Information Mart is the delivery layer that presents data to end users and reporting tools. Unlike the Raw Vault and Business Vault — which use Hub-Link-Satellite structures — Information Marts use dimensional models such as star schemas, snowflake schemas, or flat wide tables, in whatever structure the consuming tool requires.
Information Marts are usually virtualised (SQL views) rather than materialised tables, making them lightweight and easy to modify. The recommended approach is many small, focused Information Marts — one per report or use case — rather than a single large mart. Several specialised mart types exist for specific purposes:
- Error Mart — captures records rejected by a loading process due to hard rule violations. Should always be empty in a healthy system.
- Raw Mart — presents raw data in a reportable dimensional form without applying business rules. Used during agile requirements gathering to help business users articulate what they need.
- Quality Mart — shows only the bad or suspect records, giving data stewards visibility into data quality issues so they can be fixed at the source.
- Source Mart — reconstructs the original structure of a source system from the Data Vault model, with the added benefit of historical versioning and built-in GDPR data removal.
- Interface Mart — designed for machine-to-machine consumption, used when a downstream application needs to read from the platform or receive cleansed data back from it.
- AI Feature Mart — a specialised Interface Mart designed for AI and machine learning model consumption, typically wide, flat, and enriched with semantic field descriptions.
Hash Key
A Hash key is a fixed-length value derived by applying a hashing algorithm (typically MD5 or SHA-256) to one or more business key columns. In Data Vault, Hash keys serve as the primary keys of Hubs and Links, and as the foreign key references connecting Satellites to their parents.
The key advantage of Hash keys is that they can be computed independently: any system, given the same business key input, will always produce the same Hash key. This enables parallel loading, makes the model portable across environments, and simplifies join logic. The actual business key columns remain stored alongside the Hash key in the Hub or Link. For a detailed look at how Hash keys are implemented in practice, see Scalefree’s article on Hash Keys in the Data Vault.
Load Date
The load date timestamp is a technical metadata attribute on every Hub, Link, and Satellite row. It records the moment the record was loaded into the data platform — not when the event occurred in the source system, but when the data arrived in the vault. The load date is always a full timestamp, never just a date, since data platforms often receive deliveries multiple times per day.
Combined with the record source, the load date answers two fundamental audit questions for every piece of data: when was it received, and from where?
Record Source
The record source identifies which source system a particular record came from. It is stored on every Hub, Link, and Satellite row alongside the load date. Its primary audience is the development and engineering team — when investigating a data issue, the record source points directly to the originating system and delivery batch. It is not used for business reporting or compliance auditing in the same way as the load date.
PIT Table
A PIT table (Point-in-Time table) is a helper structure that makes querying historical data across multiple Satellites significantly more efficient. Without a PIT table, reconstructing the complete state of a business object at a specific historical moment requires complex, expensive joins across Satellites with different load dates. A PIT table pre-computes the correct Satellite row timestamps for each point in time, so downstream queries can join the PIT table directly rather than re-solving the temporal logic on every run.
PIT tables are derived structures — generated from Raw Vault data and rebuildable at any time. They are not part of the core Data Vault model but are standard production companions to it.
Bridge Table
A Bridge table is a helper structure that simplifies querying across multiple Links. Where PIT tables solve the temporal complexity of Satellites, Bridge tables solve the structural complexity of navigating a chain of linked Hubs — for example, tracing from a customer through their orders, through their order lines, to the products. Bridge tables are pre-joined snapshots of relationship paths that would otherwise require multiple sequential joins. See also: Bridge Tables 101 on the Scalefree blog.
Ghost Record
A ghost record (also called a default record or zero key record) is a placeholder row inserted into a Hub or Satellite to handle situations where a foreign key reference exists in the source data but the referenced record itself does not. It prevents referential integrity violations and allows the data platform to load records completely even when source data is incomplete. Ghost records are technical placeholders, not real business data, and are distinguishable by their defined default key values.
Effectivity Satellite
An Effectivity Satellite tracks the active or inactive status of a Hub record or a Link relationship over time. It records when a business object or relationship became active in the source system and when it was deactivated or deleted. When a source system deletes a record, the Hub retains the business key permanently — the Effectivity Satellite gains a new row reflecting the deletion, preserving the complete history while making the current active state queryable.
Persistent Staging Area
The Persistent Staging Area (PSA) is the layer where raw source data is stored before it enters the Raw Vault. Unlike a transient staging area (which holds only the most recent delivery), a PSA retains every historical delivery — a complete, time-stamped archive of everything ever received from every source system. In modern Data Vault architectures, the PSA role is typically fulfilled by a data lake, organised in a folder structure partitioned by source system, table, and load date.
Unit of Work
The unit of work is a concept from the Data Vault agile methodology that defines the smallest deliverable increment of business value in a sprint. It consists of a complete data flow from source to Information Mart — staging the required source data, loading the Raw Vault entities, applying business rules in the Business Vault, and delivering the result in a mart that a business user can consume. Organising development around units of work ensures every sprint delivers something tangible to the business rather than invisible infrastructure.
Data Aging
Data aging refers to the practice of identifying and marking historical records in the Raw Vault or Business Vault that are no longer operationally relevant — records that have not been updated or referenced over a significant period. Data aging strategies help manage storage costs and query performance over time. In keeping with Data Vault’s insert-only philosophy, aged records are flagged or moved to archival storage rather than deleted, preserving the completeness of the historical record.
CDVP2.1
CDVP2.1 stands for Certified Data Vault Practitioner 2.1 — the professional certification awarded by the Data Vault Alliance upon passing the certification examination. It validates that a practitioner understands and can apply the Data Vault 2.1 methodology across architecture, modeling, and implementation.
Scalefree is an authorised Data Vault Alliance training partner. The Data Vault 2.1 Training & Certification is the official path to CDVP2.1, combining instructor-led training with exam preparation and two included exam attempts. If you are building or modernising a data platform and want to understand how Data Vault fits into a broader enterprise architecture, explore the free Data Vault Handbook or get in touch with Scalefree directly.