Green-Bond-Reporting
Nachhaltigkeit und Transparenz sind längst mehr als nur Buzzwords – heutzutage gehören sie zum Selbstverständnis moderner Unternehmen. Green Bonds gewinnen zunehmend an Bedeutung, da sie gezielte Investitionen in nachhaltige Projekte ermöglichen. Ein professionelles und prüfungssicheres Reporting ist entscheidend, um Vertrauen bei Investoren, Wirtschaftsprüfern und anderen Stakeholdern zu schaffen.
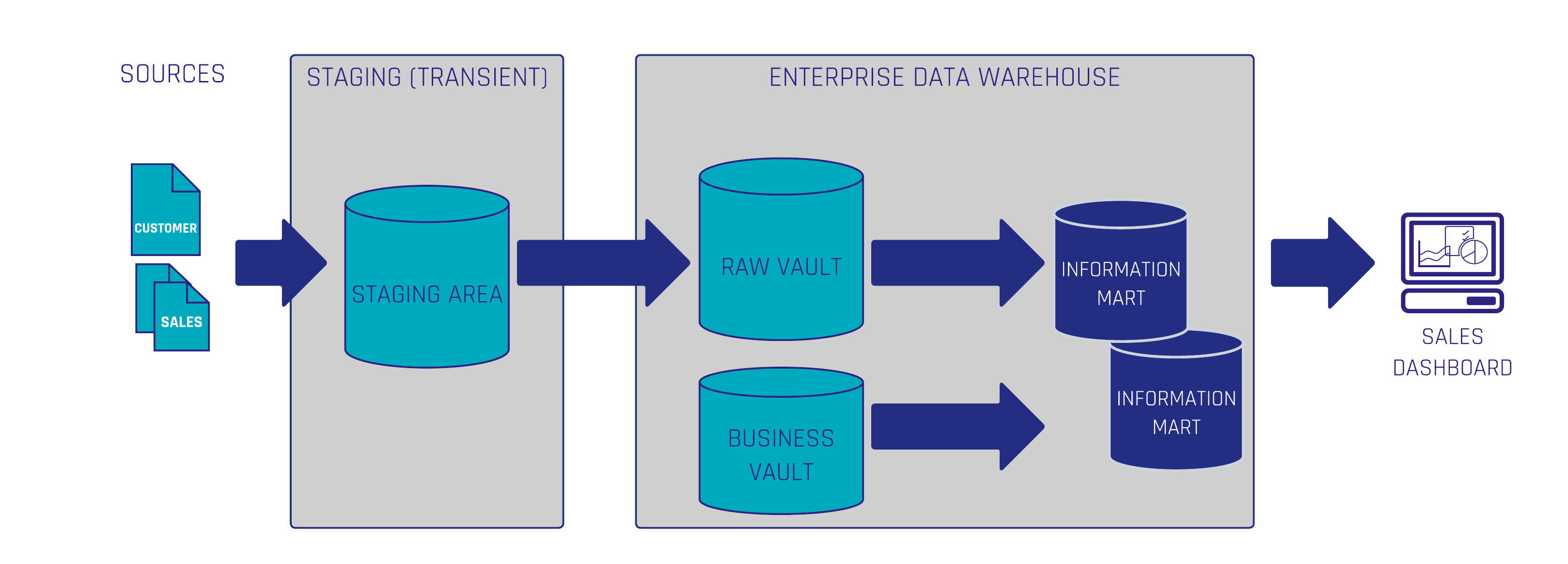
Unser Kunde Grenke vertraute bereits auf unsere Expertise und hatte ein Data Warehouse auf Basis von Data Vault 2.0 implementiert. Die Prozesse wurden weitgehend automatisiert, sodass Datenquellen effizient integriert und verarbeitet werden konnten. Als eine neue Anforderung für das Green-Bond-Reporting entstand, konnten wir diese dank des bereits bestehenden, skalierbaren Setups in nur einem Monat umsetzen.
Ausgangslage: Ein bestehendes, automatisiertes Data Warehouse
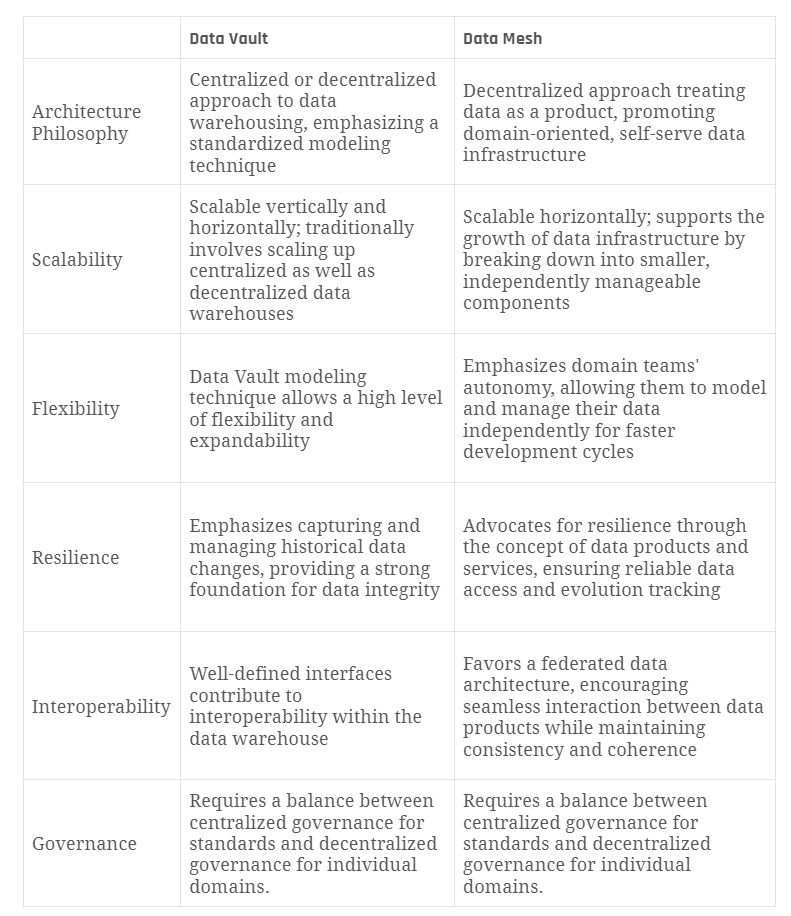
- Data-Vault-2.0-Architektur als Fundament:
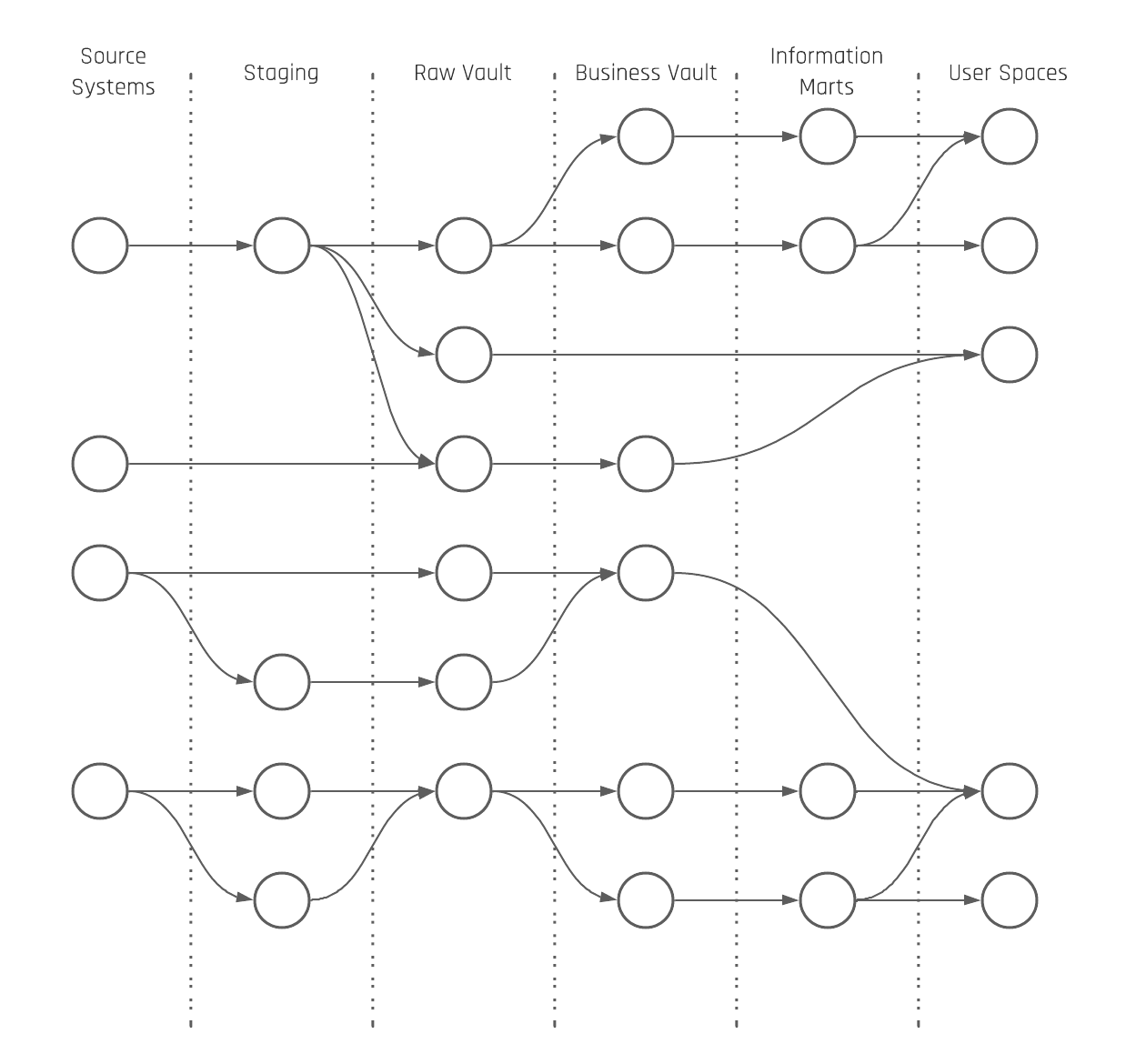
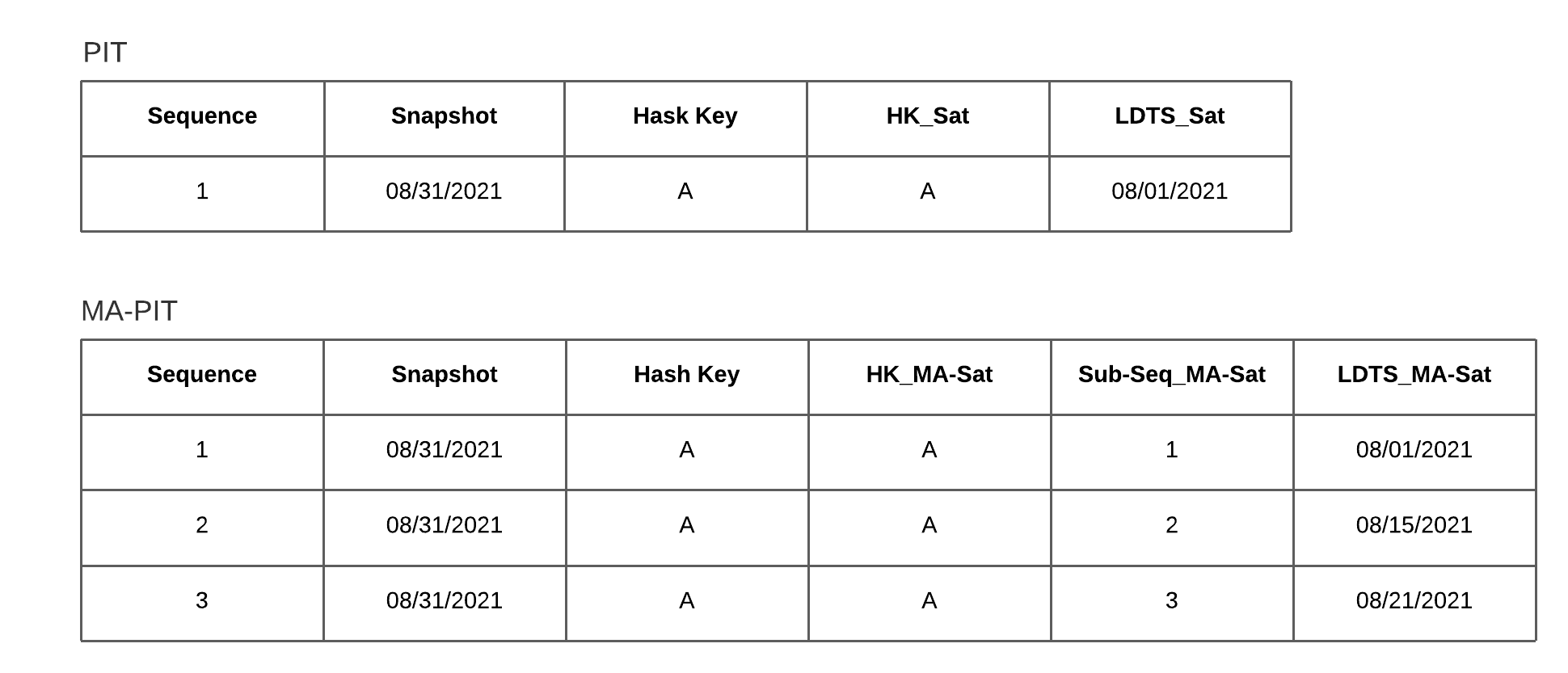
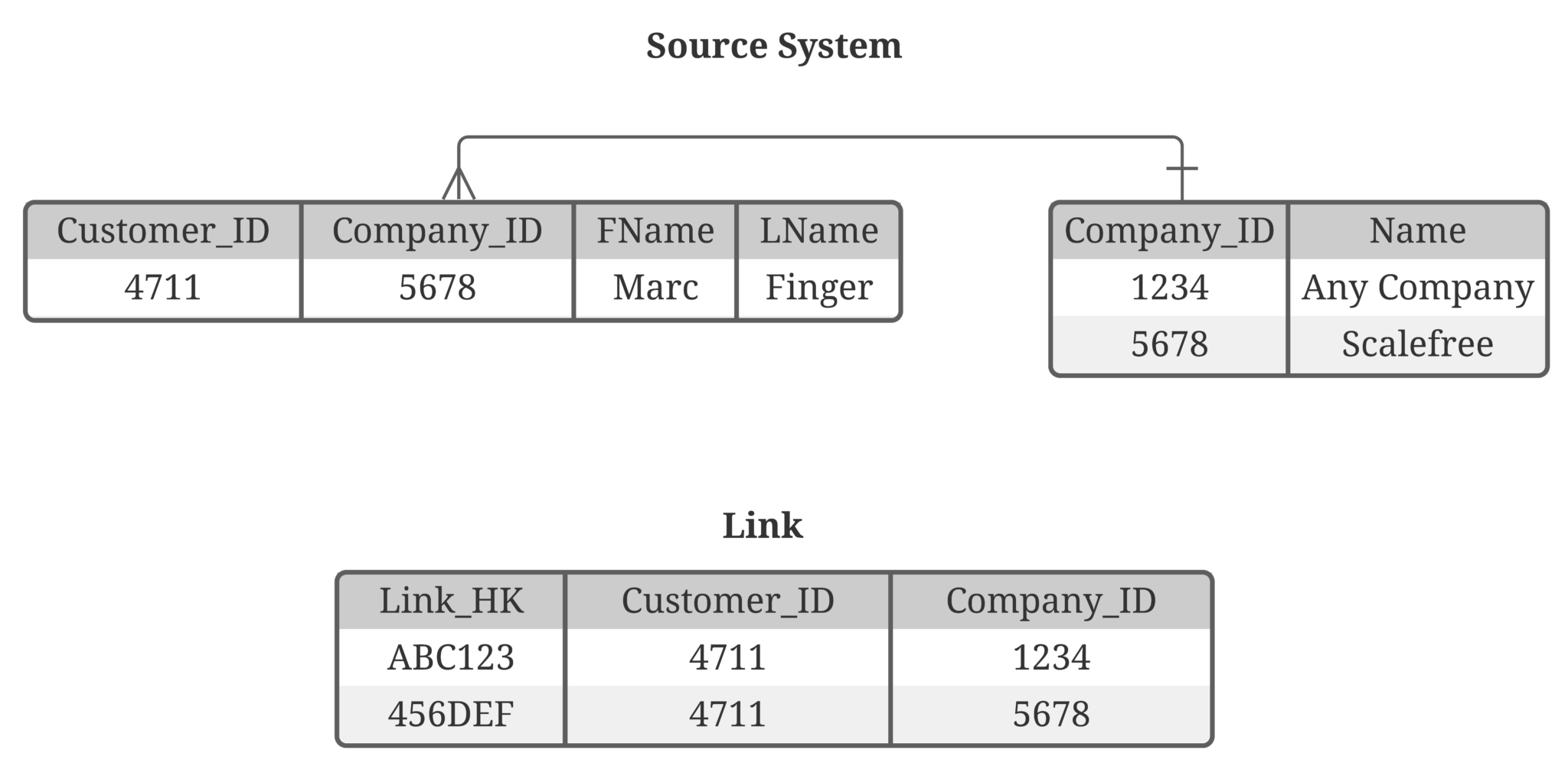
Grenke nutzte bereits eine robuste Data-Vault-2.0-Architektur, die dank ihrer klaren Strukturen (Hubs, Links und Satellites) eine flexible und erweiterbare Datenspeicherung ermöglicht. - Automatische Modellgenerierung:
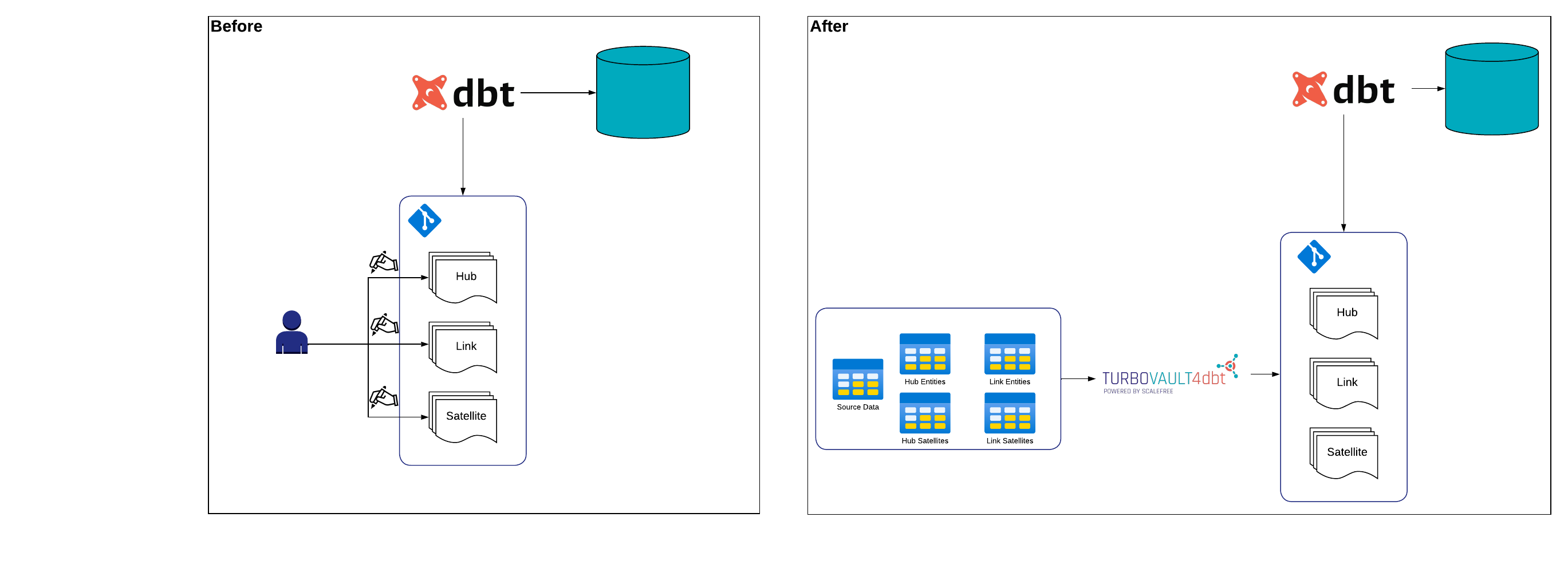
Durch den Einsatz von Templates und metadatengesteuerten Ansätzen können Data-Vault-Modelle automatisch generiert werden. Dies reduziert den manuellen Aufwand, erhöht die Standardisierung und verbessert die Datenqualität. - Qualitätsprüfungen und Revisionssicherheit:
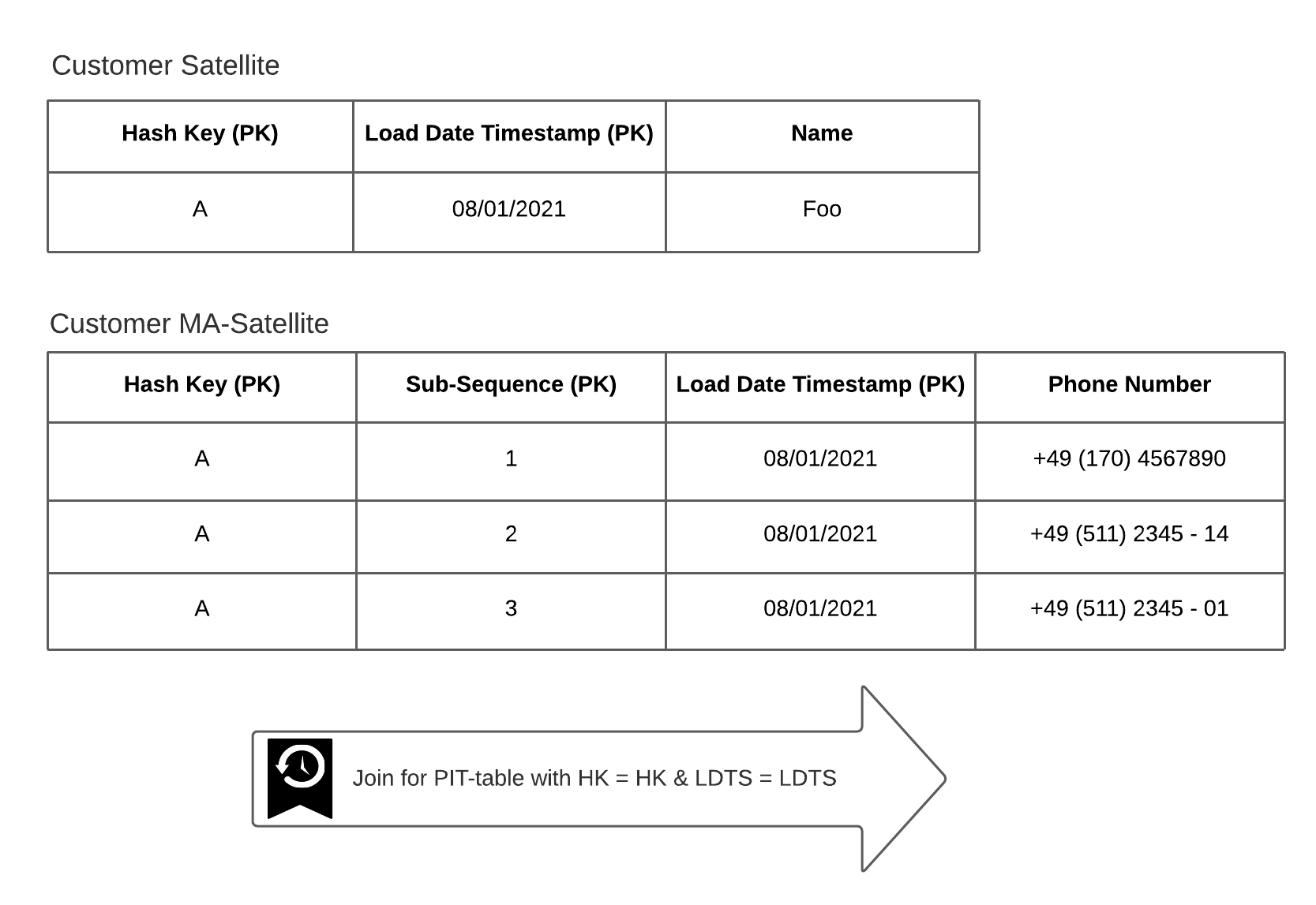
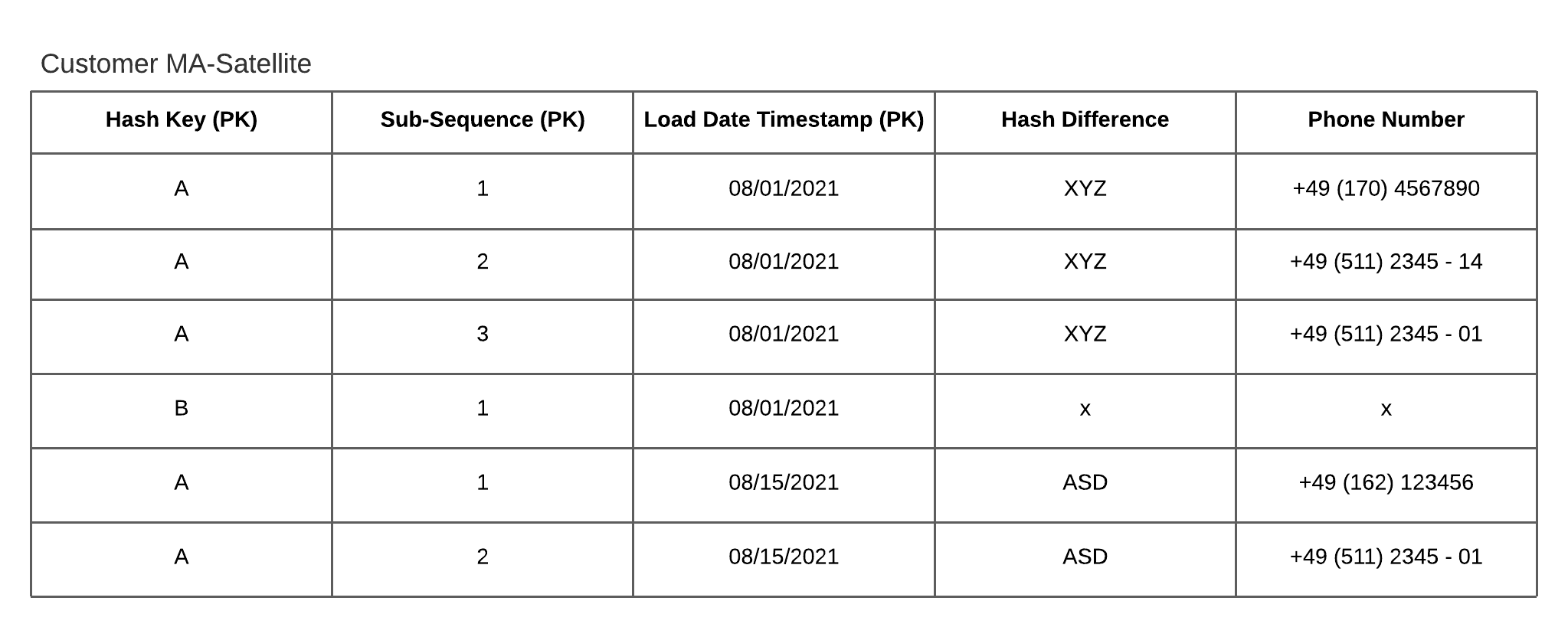
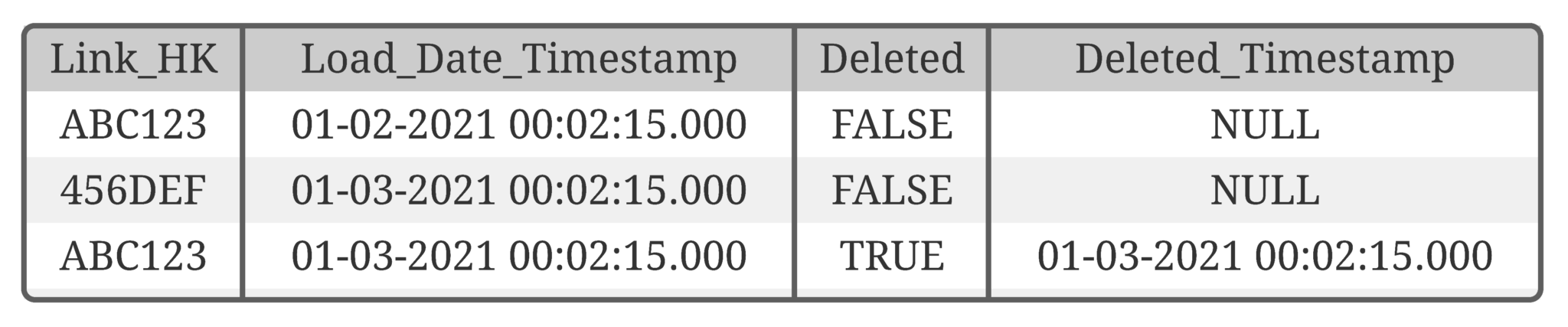
Plausibilitätsprüfungen, Historisierung und metadatenunterstützte Prozesse sorgten bereits für eine hohe Datenqualität und Nachvollziehbarkeit – essenziell für Audits und Reporting.
Diese Voraussetzungen bildeten das perfekte Sprungbrett, um das neue Green-Bond-Reporting schnell und zuverlässig in das bestehende System zu integrieren.
Neue Anforderung: Green-Bond-Reporting
Mit dieser neuen Anforderung stand Grenke vor der Herausforderung, spezifische ESG-Kennzahlen sowie Green-Bond-spezifische Daten zu erfassen, aufzubereiten und in einem nachvollziehbaren Bericht darzustellen.
Ziel war es, das Reporting so zu gestalten, dass:
Externe Prüfer und Auditoren schnell und einfach Einblick erhalten können.
Investoren und andere Stakeholder transparente Informationen über die nachhaltigen Projekte erhalten.
Regulatorische Anforderungen und interne Standards jederzeit erfüllt und nachvollziehbar dokumentiert werden.
Dank der bestehenden Data-Vault-2.0-Infrastruktur und des hohen Automatisierungsgrads konnten diese neuen Anforderungen in kurzer Zeit umgesetzt werden.
Unser Ansatz: Erweiterung statt Neubau
- Anforderungsanalyse:
Gemeinsam mit Grenke haben wir die relevanten Green-Bond-Kennzahlen und Reporting-Anforderungen definiert. Dazu gehörten Klassifizierungen nach ESG-Kriterien, die Zuordnung von Projekttypen sowie regionale und finanzielle Attribute. - Integration in das bestehende Data Warehouse:
Anstatt ein neues System aufzubauen, haben wir die erforderlichen Felder zu den bestehenden Hubs, Links und Satellites hinzugefügt. Dank der agilen Data-Vault-2.0-Methodik war dies ohne großen Zusatzaufwand möglich. - Automatisierte Prozesse und Qualitätsprüfungen:
Dank der bestehenden ETL/ELT-Strecken konnten wir die Daten schnell und sicher in das System laden. Neue Validierungsregeln für das Green-Bond-Reporting wurden ergänzt, um sicherzustellen, dass alle relevanten Daten vollständig und korrekt erfasst werden. - Reporting & Dashboards:
Auf Basis der verarbeiteten Daten haben wir interaktive Dashboards und Berichte entwickelt, die den Projektstatus, das Finanzierungsvolumen und weitere ESG-Kennzahlen übersichtlich darstellen. Bei Bedarf kann externen Prüfern auch über Exportfunktionen Zugriff gewährt werden. - Schnelle Freigabe durch externe Prüfungen:
Da die Data-Vault-2.0-Struktur eine vollständige Historisierung und Nachvollziehbarkeit der Daten gewährleistet, verliefen die externen Prüfungen reibungslos. Die Auditoren konnten alle Schritte und Datenänderungen lückenlos nachvollziehen – ein entscheidender Vorteil für Nachhaltigkeitsberichte.
Ergebnis: Green-Bond-Reporting in nur einem Monat
Die Kombination aus einem skalierbaren Data-Vault-2.0-Ansatz, einem hohen Automatisierungsgrad und einer bereits etablierten Dateninfrastruktur ermöglichte es uns, das Green-Bond-Reporting in nur einem Monat erfolgreich bereitzustellen.
Das bedeutet:
- Schnelle Time-to-Market: Grenke konnte den Bericht schnell veröffentlichen und direkt mit der Kommunikation und dem Marketing beginnen.
- Vertrauenswürdige Datenbasis: Dank integrierter Qualitätsprüfungen und Nachvollziehbarkeit ist das Reporting prüfungssicher – eine entscheidende Voraussetzung für externe Audits.
- Zukunftssichere Lösung: Neue Kennzahlen, erweiterte ESG-Kriterien oder regulatorische Anforderungen können flexibel integriert werden, ohne das System grundlegend neu aufbauen zu müssen.
Das sagt Grenke
„Die Partnerschaft mit Scalefree war entscheidend für unsere Data-Vault-2.0-Reise. Ihre tiefe Expertise in Data-Vault-Prinzipien und das praktische dbt-Know-how haben unsere Implementierung maßgeblich unterstützt und für einen reibungslosen sowie strukturierten Prozess gesorgt. Dank ihrer Begleitung konnten wir unsere Fähigkeiten zur Integration und Analyse von Unternehmensdaten bereits verbessern und gleichzeitig ein skalierbares und zukunftssicheres Data Warehouse aufbauen.“
Oliwia Borecka,
Chief Data & Analytics Officer bei grenke digital GmbH
Fazit: Agil und nachhaltig in die Zukunft
Das Projekt zeigt, wie Scalefree Kunden dabei unterstützt, neue Anforderungen schnell und effizient in bestehende Datenökosysteme zu integrieren. Der Data-Vault-2.0-Ansatz bietet dafür die ideale Basis: Skalierbarkeit, Flexibilität und Revisionssicherheit stellen sicher, dass Unternehmen ihre Reporting-Anforderungen nicht nur heute, sondern auch morgen erfüllen können.
Möchten Sie mehr darüber erfahren, wie Sie Ihr Data Warehouse oder ESG-Reporting zukunftssicher aufstellen können?
Kontaktieren Sie uns bei Scalefree – gemeinsam entwickeln wir eine maßgeschneiderte Lösung, die Ihren Anforderungen entspricht und Sie in puncto Nachhaltigkeit und Transparenz optimal aufstellt. Wir freuen uns darauf, Ihr Projekt zum Erfolg zu führen!