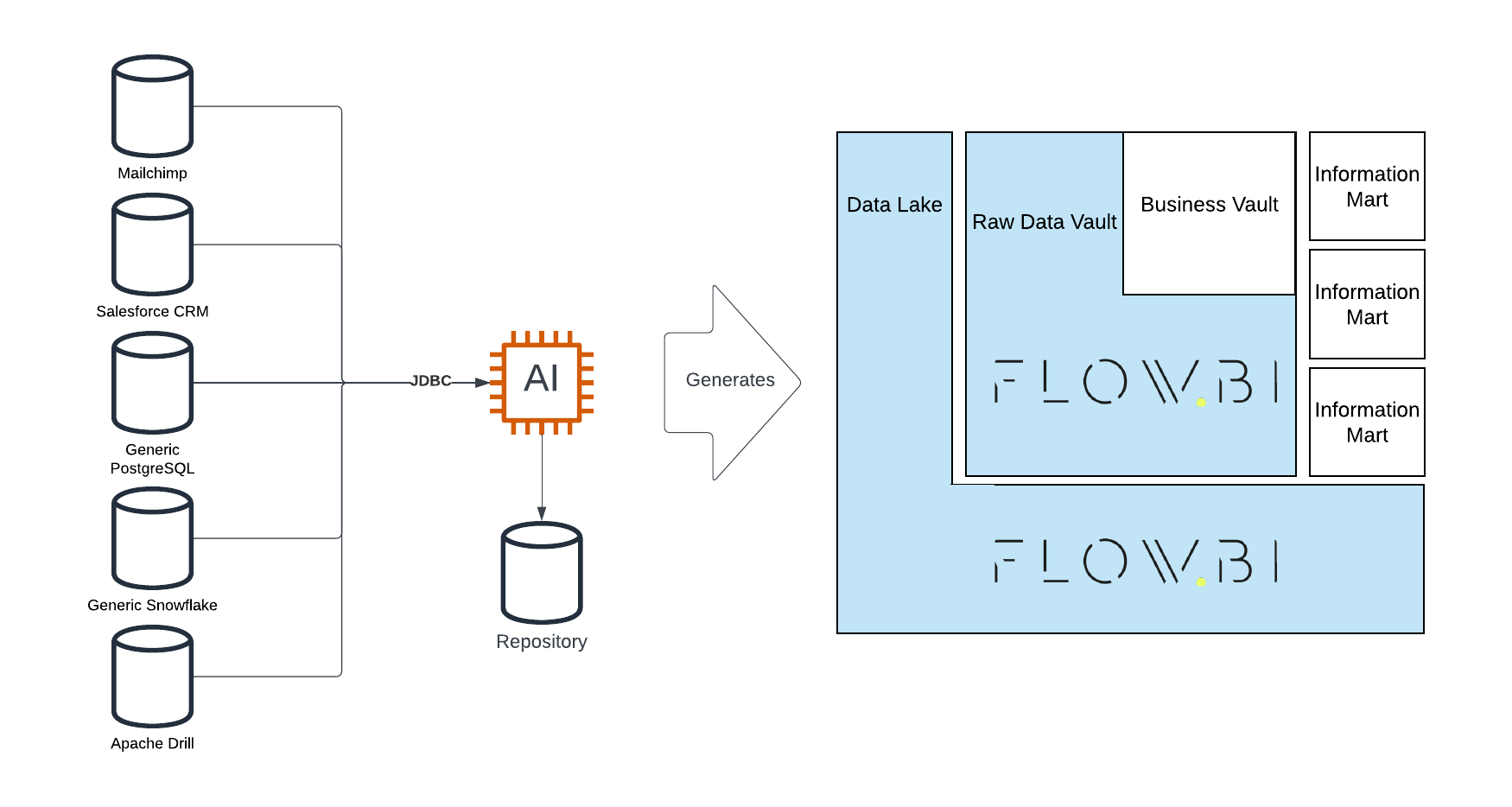
How to Explaining Data Vault
When introducing Data Vault to business users, it’s important to communicate its value in a way that resonates with them. Instead of focusing on the technical details, it’s best to highlight the benefits and business impact.
In this article:
Understanding the Audience
Business users, including executives and commercial leaders, generally don’t need to understand the intricacies of Data Vault. They are more interested in the outcomes, such as data accessibility, security, and adaptability.
Explaining Data Vault with a Simple Analogy
Imagine you are building a house. As a homeowner, you don’t need to know every construction detail; you just want to ensure that it’s solid, safe, and has all the necessary features. Similarly, business leaders don’t need to understand the technical framework of Data Vault—they just want a reliable data management system that supports their decision-making.
Focusing on Business Value
Instead of using the term “Data Vault,” it’s often more effective to discuss the advantages of a managed data platform:
- Data Security & Privacy: Ensures compliance with regulations like GDPR while securing sensitive information.
- Data Integration: Consolidates structured, semi-structured, and unstructured data from multiple sources.
- Auditability & Transparency: Provides full data lineage, ensuring that every data point can be traced back to its source.
- Agile Data Delivery: Enables incremental delivery of insights, so business teams don’t have to wait months or years to see results.
- Adaptability to Change: Easily adjusts to changes in source systems, business logic, and reporting needs.
- Handling Multiple Business Timelines: Supports complex business requirements, including postdating and backdating of records.
- Scalability: Handles large datasets and high-speed data processing.
Delivering Business Outcomes
Business leaders care about measurable outcomes. With a Data Vault-based platform, they can expect:
- Improved decision-making with accurate, timely data.
- Faster adaptation to market changes and customer demands.
- Cost efficiency through a structured yet flexible data architecture.
- Enhanced reporting and analytics with reliable data sources.
Making the Pitch to Business Users
When discussing Data Vault with executives, avoid technical jargon and focus on business goals. Instead of saying, “We use Data Vault 2.0 for data modeling,” say, “We have a data platform that ensures secure, auditable, and easily accessible insights to drive your business forward.”
By emphasizing real-world benefits, you can effectively communicate the value of Data Vault without overwhelming non-technical stakeholders with complexity.
Conclusion
Communicating the benefits of Data Vault to business users requires a shift from technical explanations to business value discussions. By framing the conversation around security, agility, and data-driven decision-making, you can successfully gain buy-in from stakeholders and demonstrate the impact of a well-managed data platform.