Alternative to the Driving Key
There is a special case when a part of the hub references stored in a link can change without describing a different relation. This has a great impact on the link satellites. Furthermore, back in 2017 we introduced the link structure with an example of a Data Vault model in the banking industry. We showed how the model looks like when a link represents either a relationship or a transaction between two business objects. A link can also connect more than two hubs. What is the alternative to the Driving Key implementation in Data Vault 2.0?
In this article:
The Driving Key
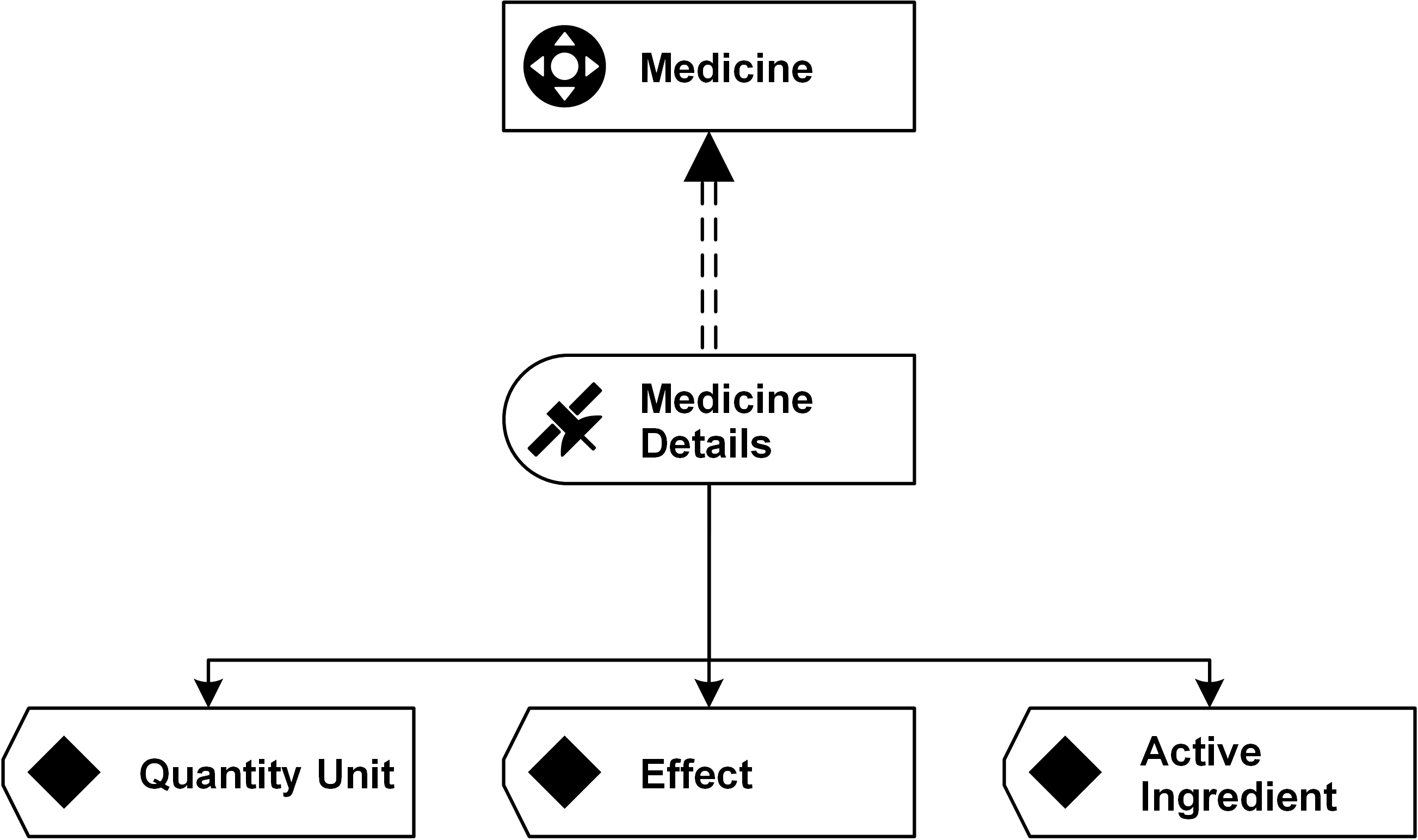
A relation or transaction is often identified by a combination of business keys in one source system. In Data Vault 2.0 this is modelled as a normal link connecting multiple hubs each containing a business key. A link contains also its own hash key, which is calculated over the combination of all parents’ business keys. So when the link connects four hubs and one business key changes, the new record will show a new link hash key. There is a problem when four business keys describe the relation, but only three of them identify it as unique. We can not identify the business object by using only the hash key of the link. The problem is not a modeling error, but we have to identify the correct record in the related satellite when query the data. In Data Vault 2.0 this is called a driving key. It is a consistent key in the relationship and often the primary key in the source system.
The following tables demonstrate the relationship between an employee and a department from a source system.
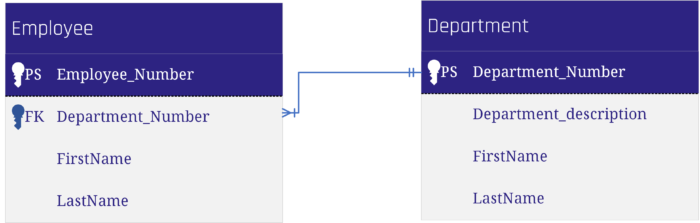
The following Data Vault model can be derived from this source structure.

The link table “Empl_Dep” is derived from the table “Employee” in the source system. The Driving Key in this example is the Employee_Number as it is the primary key in the source table, and an employee can work in only one department at the same time. This means, the true Driving Key “lives” in the satellite of the employee. If the department of an employee switches, there is no additional record in the employee’s satellite table, but a new one in the link table, which is legitimate.

To query the most recent delta you have to query it from the link table, grouped by the driving key.
To sum up you will always have a new link hash key when a business key changes in a relation. The challenge is to identify the driving key, which is a unique business key (or a combination of business keys) for the relationship between the connected hubs. Sometimes you would have to add an additional attribute to get a unique identifier.
Both present an issue for power users with access to the Data Vault model. Without naming conventions there is a risk that a group by statement is performed on more attributes than just the driving key which would lead to unexpected and incorrect aggregate values – even though the data itself is correctly modeled.
When dealing with relationship data there is a better solution available than the driving key: we typically prefer to model such data as a non-historized link and insert technical counter-transactions to the data when a hub reference changes.
In the case of a modified record in the source, we insert two records to the non-historized links: one for the new version of the modified record in the source and one for the old version that still exists in the target (non-historized link) but needs to be countered now – the technical counter record. To distinguish the records from the source and the counter transactions a new column is inserted, often called “Counter”.
The standard value for this counter attribute is 1 for records from the source and -1 for the technical counter transactions. Important: We do not perform any update statements, we still insert only the new counter records. When querying the measures from the link you just multiply the measures with the counter value.
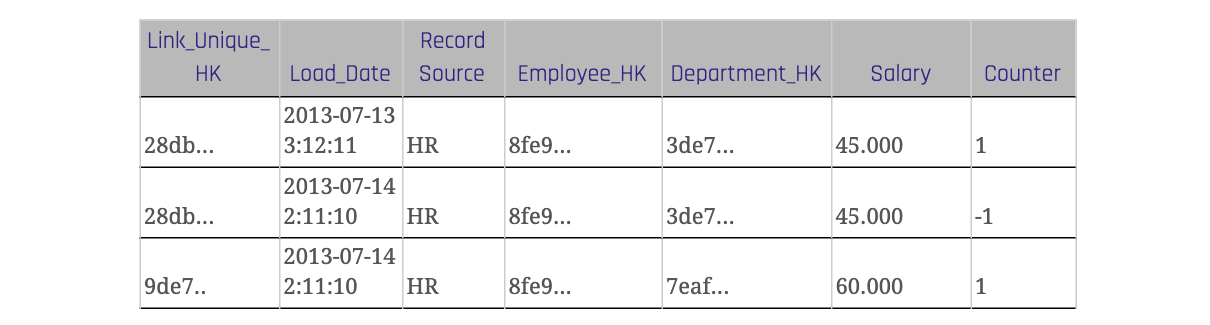
The table 3 shows a link with a counter attribute. When a record changes in the source system it is inserted with the original value and a counter value of -1 in the link table of the data warehouse. For the changed value there is a new link hash key which is also calculated over the descriptive attribute ‘Salary’. The counter value of the new record is 1.
Conclusion
Because identifying the driving key of a relation can be a problem in some situations you can use an alternative solution to avoid the driving key. All changes and deletes are tracked using a counter attribute in the non-historized link table. It stores also the descriptive attributes and the link hash key is calculated over all attributes.