Snapshotting is a crucial process when managing financial and business data. It involves capturing a static copy of data at a specific point in time, preserving it for future reference, analysis, and reporting. Therefore, snapshotting facilitates data-driven decision-making by providing a reliable historical timeline on given business dates for trend analysis, compliance, forecasting and many more to add value to the reports. This newsletter delves into the details of snapshotting based on business dates, as opposed to system timestamps, and emphasizes its significance in ensuring data accuracy and consistency.
HANDLING SNAPSHOTTING VIA A TIMELINE OTHER THAN LOAD DATE
This webinar delves into the intricacies of business date snapshotting, a vital data warehousing technique that aligns historical data with specific business requirements, contrasting it with load date snapshotting. Join us on April 15th at 11:00 AM CEST to explore this topic in depth.
Snapshotting – An Overview
Snapshotting, in essence, is the process of creating a replica of data at a particular moment. In the context of business and finance, aligning snapshots with business dates, rather than system timestamps guarantees that reports and analyses mirror operational timelines, which is crucial for period-end reporting, regulatory compliance, and historical trend analysis.
Key Characteristics of Snapshots
- Data Integrity and Accuracy: Snapshots capture a complete record of data at a specific point in time; the captured record should be immutable, except for late-arriving data, which we’ll cover later. This historical representation ensures that data remains consistent and reliable for future reference, reporting, and analysis, regardless of any subsequent modifications or deletions.
- Source of Truth: By preserving data exactly as it existed at a particular moment, snapshots offer a dependable source of truth for auditing, compliance, and regulatory requirements. They enable organizations to track changes over time, identify trends, and make informed decisions based on accurate and historical data.
- Alignment with Business Operations: Unlike traditional data storage methods that rely on timestamps, snapshots are indexed according to a given schedule e.g. business dates or time (hourly, daily, weekly etc.). This approach ensures that data is organized and accessible in a manner that aligns with business operations and reporting cycles. By accounting for non-operational days, holidays, and designated business cutoffs, snapshots provide a more meaningful and relevant representation of data from a business perspective.
Challenges with Snapshots
- Handling Late-Arriving Data: Transactions or updates may come in after a snapshot is taken, requiring strategies to manage retroactive changes.
- Business Date vs. Calendar Date: Aligning snapshots with business dates rather than system timestamps can be complex, especially when dealing with weekends, holidays, or different time zones.
- Data Consistency Across Systems: Ensuring that all related datasets are captured at the same logical point in time is critical for maintaining consistency in reporting and analysis.
- Snapshot Frequency and Granularity: Choosing the right balance between full and incremental snapshots affects system performance and usability. Taking too few snapshots may result in data gaps, while excessive snapshots increase processing overhead.
Strategies for Effective Snapshot Management
To effectively manage snapshotting through a timeline that isn’t solely reliant on load date, several key considerations must be addressed:
Snapshot Frequency
- The frequency with which snapshots are taken should be determined by the specific requirements of the business, including reporting needs, regulatory compliance, and data retention policies.
- Options for snapshot frequency include daily, weekly, monthly, or even more granular intervals depending on the volatility of the data and the necessity for historical accuracy.
- It is essential to balance the need for frequent snapshots with the storage and processing overhead they incur.
Business Date Alignment
- Snapshots should be aligned with business dates rather than system timestamps to ensure consistency and relevance to business operations.
- This alignment must take into account weekends, holidays, and other non-business days, as well as period-end adjustments and other business-specific calendar considerations.
- The goal is to capture data that accurately reflects the state of the business at a given point in time from a business perspective.
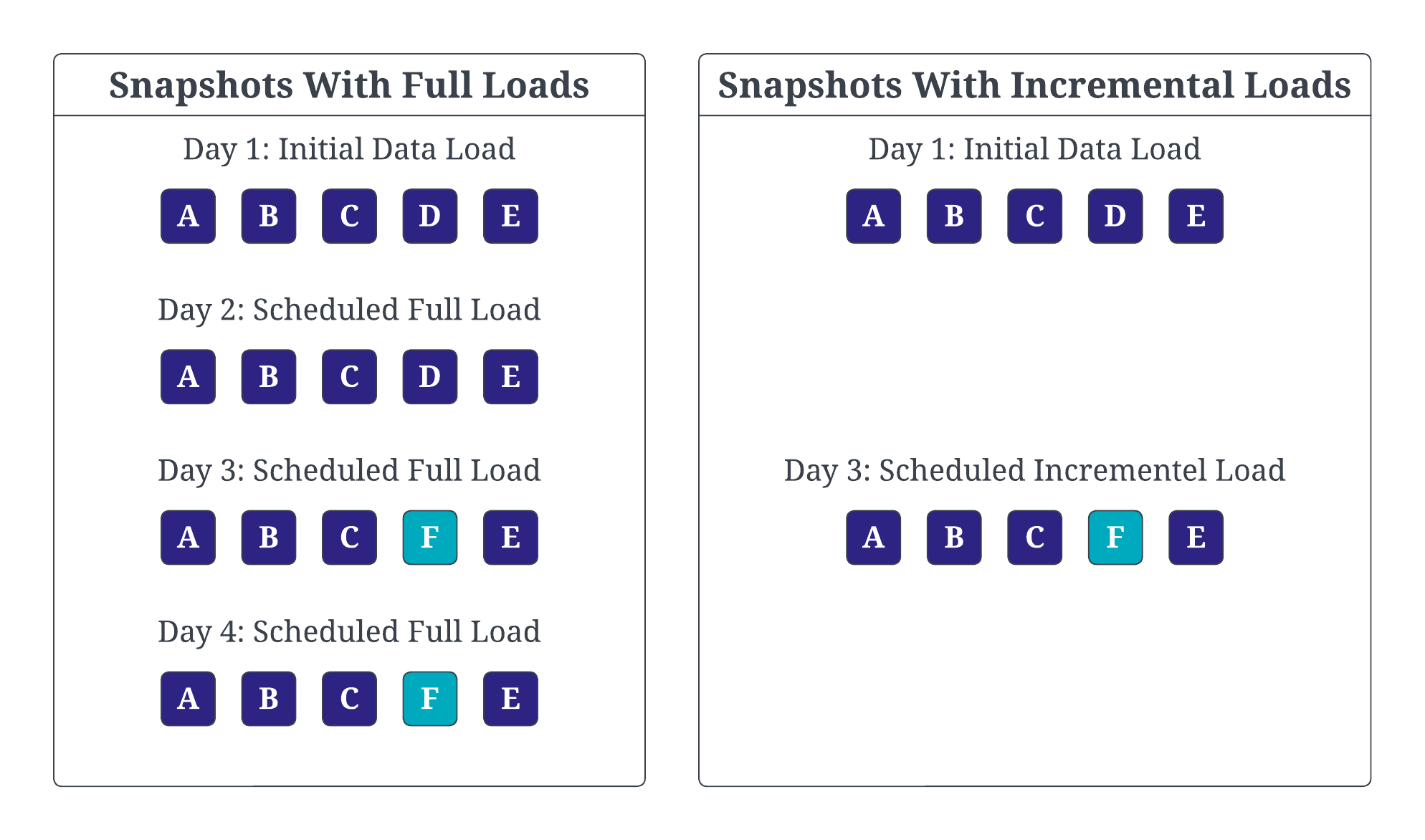
Snapshot Type
- The choice between full snapshots and incremental snapshots depends on factors such as storage capacity, processing power, and data retrieval requirements.
- Full snapshots capture the entire dataset at a specific point in time, while incremental snapshots only store the changes that have occurred since the last snapshot.
- Incremental snapshots are generally more efficient in terms of storage and processing, but may be more complex to manage and restore.
Late/ Corrected Data
To ensure data accuracy and historical integrity within a snapshotting system that utilizes a timeline other than load date, a robust mechanism must be implemented to manage late-arriving transactions and data corrections. This is essential to maintain a reliable and consistent representation of the data over time.
Several strategies can be employed to achieve this, including versioning and backdating. Versioning involves maintaining multiple versions of the data, each representing a specific point in time, allowing for easy tracking of changes and rollbacks if necessary. Backdating, on the other hand, involves assigning a timestamp to the data that reflects its actual occurrence time, rather than the time it was loaded into the system. This ensures that the data is placed in its correct historical context.
Furthermore, it is crucial to consider the potential impact of late or corrected data on reporting and analysis. Late-arriving data can distort results and lead to inaccurate conclusions if not handled properly. Similarly, data corrections can invalidate previous analyses and require recalculations. Therefore, appropriate controls and safeguards must be put in place to mitigate these risks. This may include data validation checks, reconciliation processes, and audit trails to track data changes and ensure accountability.
By implementing these measures, organizations can maintain the accuracy, consistency, and reliability of their snapshot data, even in the face of late-arriving transactions and data corrections. This, in turn, enables them to make informed decisions, generate accurate reports, and support effective analysis based on trustworthy historical data.
Additional Considerations
- Retention Policy: Establish a clear retention policy for snapshots, considering legal, regulatory, and business requirements.
- Storage and Performance: Evaluate storage options and their impact on system performance, considering scalability and cost.
- Data Security: Implement appropriate security measures to protect snapshot data from unauthorized access or modification.
- Disaster Recovery: Include snapshots in disaster recovery plans to ensure business continuity.
- Metadata Management: Maintain metadata about snapshots, including creation time, business date, and snapshot type, to facilitate management and retrieval.
By carefully considering these factors and implementing a well-designed snapshot management strategy, organizations can effectively leverage snapshots to support business operations, regulatory compliance, and data-driven decision-making.
Conclusion
Snapshotting based on business dates is crucial for data management, especially in business and finance. It provides a reliable basis for reporting, analysis, and decision-making by capturing and structuring data in alignment with business operations. Snapshots also facilitate historical records for compliance and auditing, and enable comparisons between different time periods. However, potential challenges like data duplication and corruption need to be addressed through robust data management practices. In conclusion, snapshotting offers significant benefits, but requires careful management to ensure data accuracy and integrity.


