Green Bond Reporting
Sustainability and transparency have long been more than just buzzwords – nowadays, they are part of how modern companies see themselves. Green bonds are becoming increasingly important as they enable targeted investments in sustainable projects. Professional and audit-proof reporting is crucial to create trust among investors, auditors, and other stakeholders.
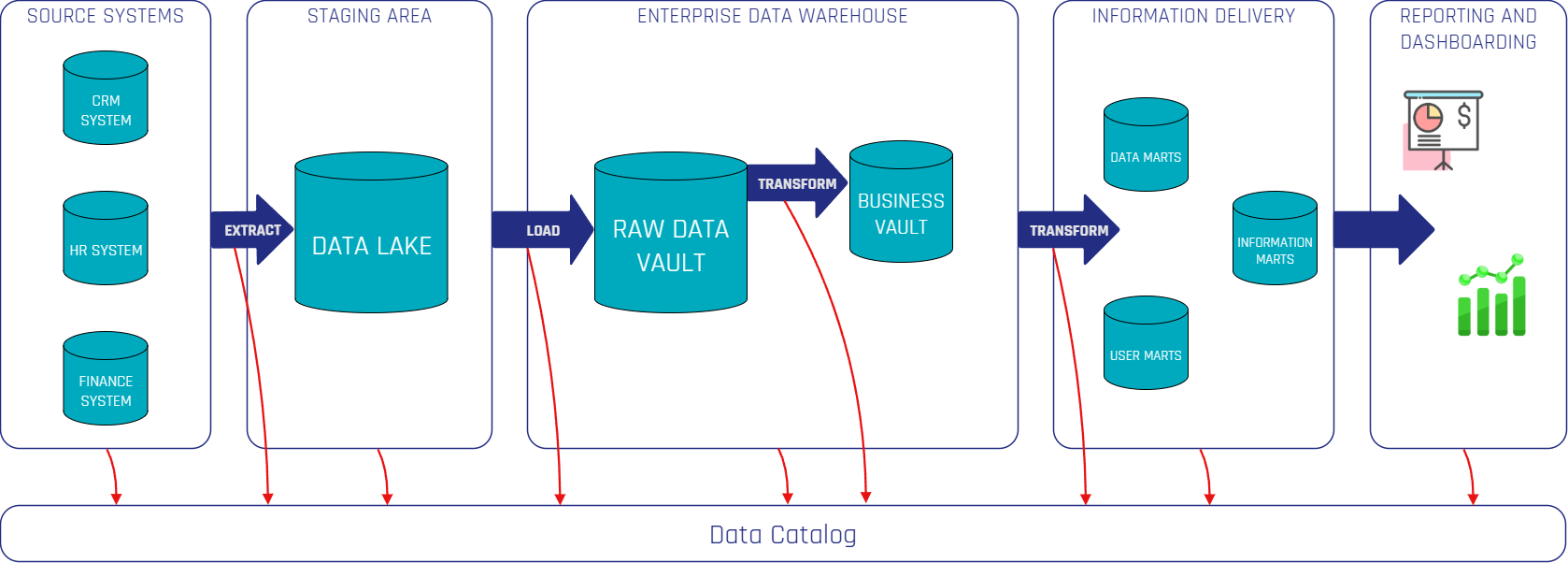
Our client Grenke, had already relied on our expertise and implemented a data warehouse based on Data Vault 2.0. The processes were largely automated so that data sources could be integrated and processed efficiently. When a new requirement for green bond reporting arose, we were able to implement it in just one month, thanks to the already existing scalable setup.
Initial Situation: An Existing, Automated Data Warehouse
- Data Vault 2.0 as a foundation:
Grenke was already using a robust Data Vault 2.0 architecture that enables flexible and expandable data storage thanks to its clear structures (hubs, links and satellites). - Automated model generation:
By using templates and metadata-driven approaches, data vault models can be generated automatically. This reduces manual effort, increases standardization and improves data quality. - Quality checks and audit compliance:
Plausibility checks, historization and metadata-supported processes already ensured high data quality and traceability – essential for audits and reporting.
These prerequisites formed the perfect springboard for quickly and reliably integrating the new Green Bond Reporting into the existing system.
New Requirement: Green Bond Reporting
With this new requirement, Grenke was faced with the challenge of collecting and preparing and presenting specific ESG key figures and green bond-specific data in a comprehensible report.
The aim was to design the reporting in such a way that:
External reviewers and auditors can gain insight quickly and easily.
Investors and other stakeholders receive transparent information about the sustainable projects.
Regulatory requirements and internal standards are met at all times and documented in a comprehensible manner.
Thanks to the existing Data Vault 2.0 infrastructure and the high level of automation, it was possible to implement these new requirements in a short space of time.
Our Approach: Expansion Instead Of New Construction
- Requirements analysis
Together with Grenke, we defined the relevant green bond key figures and reporting requirements. These included classifications according to ESG criteria, assignment of project types, as well as regional and financial attributes. - Integration into the existing data warehouse
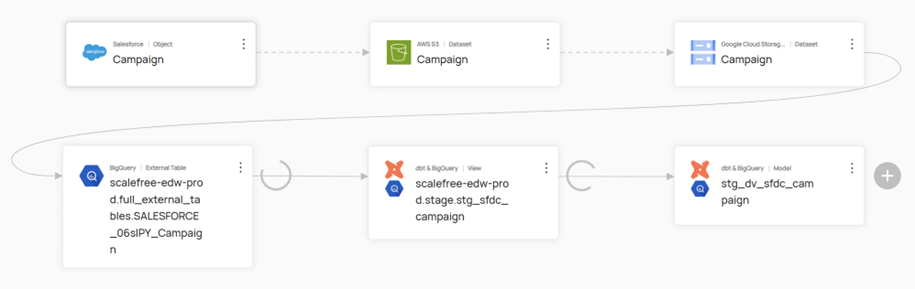
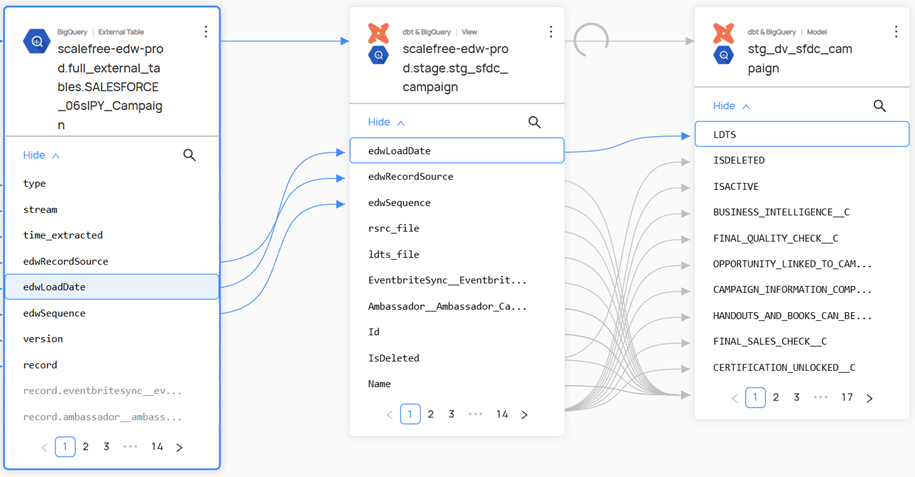
Instead of building a new system, we added the required fields to the existing hubs, links and satellites. Thanks to the agile Data Vault 2.0 methodology, this was possible without much additional effort. - Automated processes and quality checks
Thanks to the existing ETL/ELT routes, we were able to quickly and securely load the data into the system. New validation rules for green bond reporting were added to ensure that all relevant data was recorded completely and correctly. - Reporting & dashboards
Based on the processed data, we have developed interactive dashboards and reports that clearly present the project status, the scope of financing, and other ESG key figures. External auditors can also be given access via export functions if required. - Rapid approval through external audits
As the Data Vault 2.0 structure ensures complete historization and traceability of the data, the external audits ran smoothly. The auditors were able to fully trace all steps and data changes – a decisive advantage for sustainability reports.
Result: Green Bond Reporting In Just One Month
The combination of a scalable Data Vault 2.0 approach, a high level of automation, and an already established data infrastructure enabled us to successfully deliver the Green Bond Reporting in just one month.
This means:
- Fast time-to-market: Grenke was able to publish the report quickly and go straight into communication and marketing.
- Trustworthy database: Thanks to integrated quality checks and traceability, the reporting is audit-proof – a crucial prerequisite for external audits.
- Future-proof solution: New key figures, extended ESG criteria, or regulatory requirements can be flexibly integrated without having to fundamentally rebuild the system.
What Grenke Says
“Partnering with Scalefree has been instrumental in our Data Vault 2.0 journey. Their deep expertise in Data Vault principles and practical dbt know-how have significantly supported our implementation, ensuring a smooth and structured process. Thanks to their guidance, we’ve already improved our ability to integrate and analyze business data while building a scalable and future-proof data warehouse.”
Oliwia Borecka
Chief Data & Analytics Officer at grenke digital GmbH
Conclusion: Agile And Sustainable Into The Future
The project shows how Scalefree supports customers in quickly and efficiently integrating new requirements into existing data ecosystems. The Data Vault 2.0 approach provides the ideal basis for this: scalability, flexibility, and revision security ensure that companies can meet their reporting requirements not only today, but also tomorrow.
Would you like to find out more about how you can future-proof your data warehouse or ESG reporting?
Contact us at Scalefree – together we will develop a customized solution that meets your requirements and puts you in the best possible position in terms of sustainability and transparency. We look forward to making your project a success!